After trying out the Container Registry integration (but eventually deciding that it's not that useful to us), it seems to be the case that something within the process outlined in the docs has left our GitLab instance in an invalid state, which breaks it to the point of becoming unusable.
The problem is that, apparently, a Sidekiq job is stuck in an infinite loop: It keeps spawning. As soon as capacity is available on a Sidekiq worker, a new job pops up. The specific job is called ContainerRegistry::DeleteContainerRepositoryWorker, I have reproduced one of its queue representations below:
{"retry"=>0, "queue"=>"default", "version"=>0, "status_expiration"=>1800, "queue_namespace"=>"container_repository_delete", "args"=>[], "class"=>"ContainerRegistry::DeleteContainerRepositoryWorker", "jid"=>"8e56ce71ec9cf7c4a0eae8fd", "created_at"=>1708097426.835311, "meta.caller_id"=>"ContainerRegistry::DeleteContainerRepositoryWorker", "correlation_id"=>"caa24956212e875d03537fd71282cba2", "meta.root_caller_id"=>"Cronjob", "meta.feature_category"=>"container_registry", "meta.client_id"=>"ip/", "worker_data_consistency"=>"always", "size_limiter"=>"validated", "enqueued_at"=>1708097426.838449}
This effectively suffocates the queue, no other task can be processed and the entire instance grinds to a halt. The web interface works, but most features simply hang because their background jobs never get the chance to run.
Here is a very small excerpt from the instance logs:
Feb 16 16:34:20{"severity":"INFO","time":"2024-02-16T15:34:20.544Z","retry":0,"queue":"default","version":0,"status_expiration":1800,"queue_namespace":"container_repository_delete","args":[],"class":"ContainerRegistry::DeleteContainerRepositoryWorker","jid":"1b599d25b46a565485c3f4f6","created_at":"2024-02-16T15:34:20.409Z","meta.caller_id":"ContainerRegistry::DeleteContainerRepositoryWorker","correlation_id":"caa24956212e875d03537fd71282cba2","meta.root_caller_id":"Cronjob","meta.feature_category":"container_registry","meta.client_id":"ip/","worker_data_consistency":"always","size_limiter":"validated","enqueued_at":"2024-02-16T15:34:20.413Z","job_size_bytes":2,"pid":69152,"message":"ContainerRegistry::DeleteContainerRepositoryWorker JID-1b599d25b46a565485c3f4f6: done: 0.120002 sec","job_status":"done","scheduling_latency_s":0.011408,"redis_calls":8,"redis_duration_s":0.007204,"redis_read_bytes":9,"redis_write_bytes":1246,"redis_queues_calls":4,"redis_queues_duration_s":0.002866,"redis_queues_read_bytes":5,"redis_queues_write_bytes":707,"redis_shared_state_calls":4,"redis_shared_state_duration_s":0.004338,"redis_shared_state_read_bytes":4,"redis_shared_state_write_bytes":539,"db_count":10,"db_write_count":3,"db_cached_count":1,"db_replica_count":0,"db_primary_count":10,"db_main_count":10,"db_ci_count":0,"db_main_replica_count":0,"db_ci_replica_count":0,"db_replica_cached_count":0,"db_primary_cached_count":1,"db_main_cached_count":1,"db_ci_cached_count":0,"db_main_replica_cached_count":0,"db_ci_replica_cached_count":0,"db_replica_wal_count":0,"db_primary_wal_count":0,"db_main_wal_count":0,"db_ci_wal_count":0,"db_main_replica_wal_count":0,"db_ci_replica_wal_count":0,"db_replica_wal_cached_count":0,"db_primary_wal_cached_count":0,"db_main_wal_cached_count":0,"db_ci_wal_cached_count":0,"db_main_replica_wal_cached_count":0,"db_ci_replica_wal_cached_count":0,"db_replica_duration_s":0.0,"db_primary_duration_s":0.033,"db_main_duration_s":0.033,"db_ci_duration_s":0.0,"db_main_replica_duration_s":0.0,"db_ci_replica_duration_s":0.0,"cpu_s":0.061245,"worker_id":"sidekiq","rate_limiting_gates":[],"duration_s":0.120002,"completed_at":"2024-02-16T15:34:20.544Z","load_balancing_strategy":"primary","db_duration_s":0.038678,"urgency":"low","target_duration_s":300,"target_scheduling_latency_s":60}
Feb 16 16:34:20{"severity":"INFO","time":"2024-02-16T15:34:20.553Z","retry":0,"queue":"default","version":0,"status_expiration":1800,"queue_namespace":"container_repository_delete","args":[],"class":"ContainerRegistry::DeleteContainerRepositoryWorker","jid":"6be37d4007f559ced52a8eb5","created_at":"2024-02-16T15:34:20.535Z","meta.caller_id":"ContainerRegistry::DeleteContainerRepositoryWorker","correlation_id":"caa24956212e875d03537fd71282cba2","meta.root_caller_id":"Cronjob","meta.feature_category":"container_registry","meta.client_id":"ip/","worker_data_consistency":"always","size_limiter":"validated","enqueued_at":"2024-02-16T15:34:20.538Z","job_size_bytes":2,"pid":69152,"message":"ContainerRegistry::DeleteContainerRepositoryWorker JID-6be37d4007f559ced52a8eb5: start","job_status":"start","scheduling_latency_s":0.015051}
It's just this, over and over again, multiple times a second. I've tried canceling the tasks manually via the Rails console, but they just keep spawning.
Has anybody encountered this behavior before? Is there a way to prevent these tasks from spawning?
The especially weird thing is that this only started happening after trying out the Container Registry integration, but also not immediately. Even disabling the registry again does nothing to quell the issue, which is particularly frustrating: Currently I have no way back to a stable state (that I can see, at least).
Here's a screenshot of when things went south, the spike in jobs is incredibly drastic:
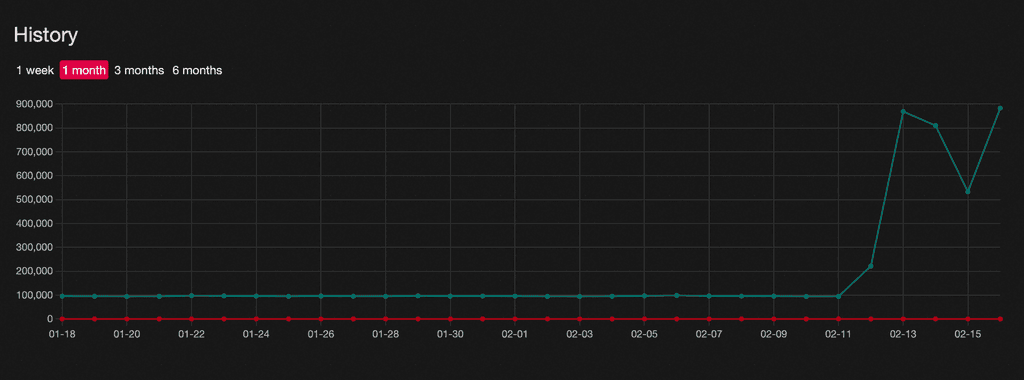
Any info on this would be extremely appreciated.