How to use local GPU with remote LibreChat?
-
Many of us run Cloudron on a remote VPS (Virtual Private Server) without a GPU (Graphical Processing Unit) and then deploy applications like LibreChat there.
How could we easily make use of our local hardware, which might include a graphics card, to help the inferencing on LibreChat?
Rathole has been requested for Cloudron but there are other applications which might help, too.
https://github.com/rapiz1/rathole#rathole
how about zrok or FRP?
-
Imo, just serve Ollama on the server that has the GPU either locally (bare metal) or resource mapped (Proxmox/Virtualized), make sure to pass the server address flag in the systemd module / start script (it's in the docs; sorry, on mobile), connect both machines to a Tailscale tailnet, then configure LibreChat in the two config files to point the Ollama settings to your GPU's tailnet IP or hostname. I have found that this pathway is pretty robust. I haven't noticed any real slowdown, and my VPS and homelab are over 4,000 miles apart.

-
Many of us run Cloudron on a remote VPS (Virtual Private Server) without a GPU (Graphical Processing Unit) and then deploy applications like LibreChat there.
How could we easily make use of our local hardware, which might include a graphics card, to help the inferencing on LibreChat?
Rathole has been requested for Cloudron but there are other applications which might help, too.
https://github.com/rapiz1/rathole#rathole
how about zrok or FRP?
@LoudLemur Have you checked out Kimi.com yet?
Although I guess you don't have a terrabyte in VRAM, thought you might like this post:
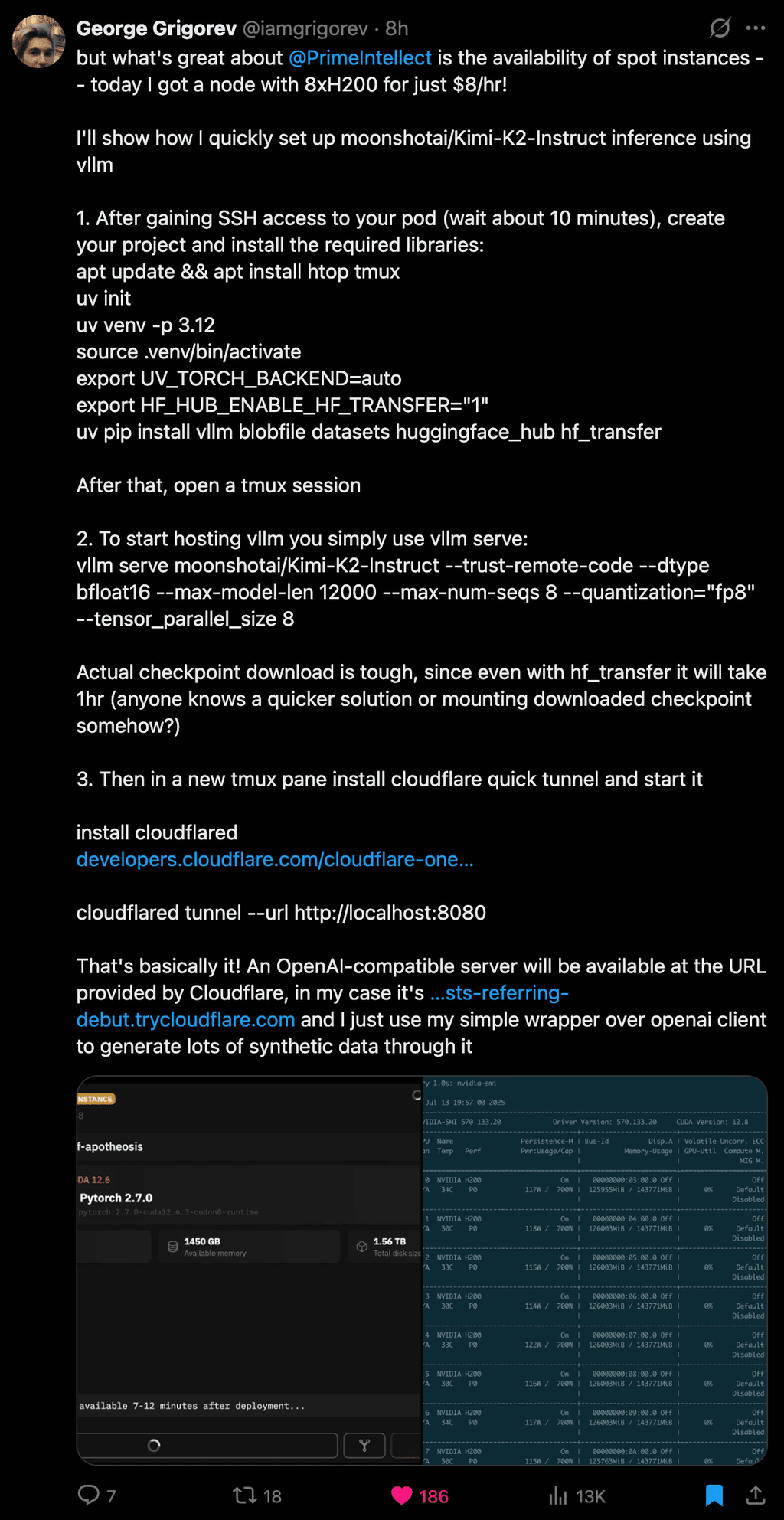
-
@LoudLemur Have you checked out Kimi.com yet?
Although I guess you don't have a terrabyte in VRAM, thought you might like this post:
@marcusquinn Wow! That is amazing. Thank you.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login