Baserow - [CRITICAL] WORKER TIMEOUT
-
Hi guys,
Since last weekend, my Baserow instance has started consuming excessive server resources (attached is a screenshot showing the CPU consumption spikes) and the frontend is not working. In fact, I noticed it wasn't working because the n8n workflows that use it were consistently failing.
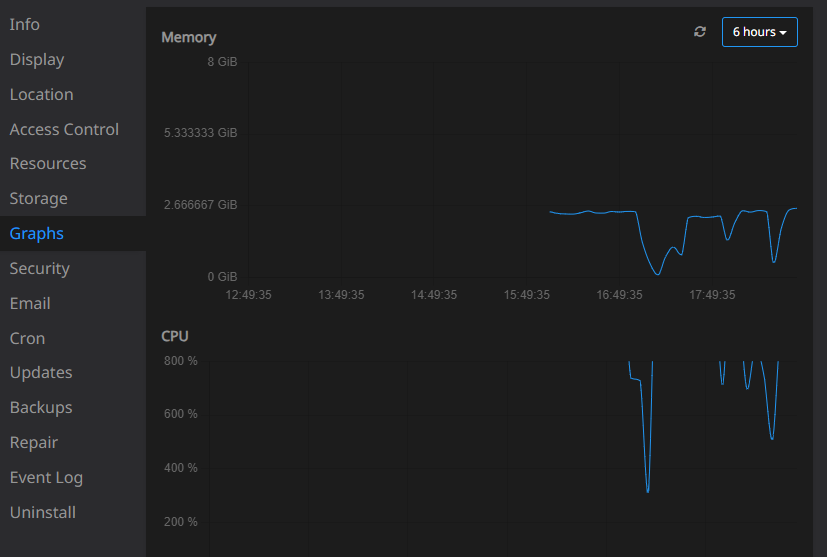
Additionally, when reviewing the application logs, I found numerous warnings like the following:
Jul 22 18:44:59 Not configuring telemetry due to BASEROW_ENABLE_OTEL not being set. Jul 22 18:45:00 [2024-07-22 16:45:00,098: INFO/MainProcess] Scheduler: Sending due task baserow.core.notifications.tasks.beat_send_instant_notifications_summary_by_email() (baserow.core.notifications.tasks.beat_send_instant_notifications_summary_by_email) Jul 22 18:45:00 [2024-07-22 16:45:00,103: INFO/MainProcess] Task baserow.core.notifications.tasks.beat_send_instant_notifications_summary_by_email[1c6e7cb7-e7eb-4809-ae45-c46778e72594] received Jul 22 18:45:00 [2024-07-22 16:45:00,304: INFO/MainProcess] Task baserow.core.notifications.tasks.singleton_send_instant_notifications_summary_by_email[bc948e50-4c8f-4229-96a2-4a79cc986bed] received Jul 22 18:45:00 [2024-07-22 16:45:00,503: INFO/ForkPoolWorker-8] Task baserow.core.notifications.tasks.beat_send_instant_notifications_summary_by_email[1c6e7cb7-e7eb-4809-ae45-c46778e72594] succeeded in 0.3006958370006032s: None Jul 22 18:45:00 [2024-07-22 16:45:00 +0000] [23] [WARNING] Worker with pid 226 was terminated due to signal 9 Jul 22 18:45:00 [2024-07-22 16:45:00,696: INFO/ForkPoolWorker-1] Task baserow.core.notifications.tasks.singleton_send_instant_notifications_summary_by_email[bc948e50-4c8f-4229-96a2-4a79cc986bed] succeeded in 0.2945839520007212s: None Jul 22 18:45:00 [2024-07-22 16:45:00 +0000] [232] [INFO] Booting worker with pid: 232 Jul 22 18:45:02 [2024-07-22 16:45:01 +0000] [23] [CRITICAL] WORKER TIMEOUT (pid:227) Jul 22 18:45:02 [2024-07-22 16:45:01 +0000] [23] [CRITICAL] WORKER TIMEOUT (pid:228) Jul 22 18:45:02 [2024-07-22 16:45:02 +0000] [228] [INFO] Worker exiting (pid: 228) Jul 22 18:45:02 Not configuring telemetry due to BASEROW_ENABLE_OTEL not being set. Jul 22 18:45:02 Not configuring telemetry due to BASEROW_ENABLE_OTEL not being set. Jul 22 18:45:02 [2024-07-22 16:45:02 +0000] [227] [INFO] Worker exiting (pid: 227) Jul 22 18:45:03 [2024-07-22 16:45:03 +0000] [23] [WARNING] Worker with pid 227 was terminated due to signal 9 Jul 22 18:45:03 [2024-07-22 16:45:03 +0000] [233] [INFO] Booting worker with pid: 233 Jul 22 18:45:03 [2024-07-22 16:45:03 +0000] [23] [WARNING] Worker with pid 228 was terminated due to signal 9 Jul 22 18:45:03 [2024-07-22 16:45:03 +0000] [234] [INFO] Booting worker with pid: 234 Jul 22 18:45:07 => Healtheck error: Error: Timeout of 7000ms exceeded Jul 22 18:45:07 172.18.0.1 - - [22/Jul/2024:16:45:07 +0000] "GET /_health HTTP/1.1" 499 0 "-" "Mozilla (CloudronHealth)" Jul 22 18:45:17 => Healtheck error: Error: Timeout of 7000ms exceeded Jul 22 18:45:17 172.18.0.1 - - [22/Jul/2024:16:45:17 +0000] "GET /_health HTTP/1.1" 499 0 "-" "Mozilla (CloudronHealth)" Jul 22 18:45:22 [2024-07-22 16:45:22 +0000] [22] [CRITICAL] WORKER TIMEOUT (pid:229) Jul 22 18:45:23 [2024-07-22 16:45:23 +0000] [22] [WARNING] Worker with pid 229 was terminated due to signal 6 Jul 22 18:45:23 [2024-07-22 16:45:23 +0000] [22] [CRITICAL] WORKER TIMEOUT (pid:230) Jul 22 18:45:23 [2024-07-22 16:45:23 +0000] [22] [CRITICAL] WORKER TIMEOUT (pid:231) Jul 22 18:45:23 [2024-07-22 16:45:23 +0000] [235] [INFO] Booting worker with pid: 235 Jul 22 18:45:24 [2024-07-22 16:45:24 +0000] [22] [WARNING] Worker with pid 230 was terminated due to signal 6 Jul 22 18:45:24 [2024-07-22 16:45:24 +0000] [236] [INFO] Booting worker with pid: 236 Jul 22 18:45:24 [2024-07-22 16:45:24 +0000] [22] [WARNING] Worker with pid 231 was terminated due to signal 9 Jul 22 18:45:24 [2024-07-22 16:45:24 +0000] [237] [INFO] Booting worker with pid: 237 Jul 22 18:45:25 172.18.0.1 - - [22/Jul/2024:16:45:25 +0000] "GET /_health HTTP/1.1" 200 162736 "-" "Mozilla (CloudronHealth)" Jul 22 18:45:31 Not configuring telemetry due to BASEROW_ENABLE_OTEL not being set. Jul 22 18:45:31 [2024-07-22 16:45:30 +0000] [23] [CRITICAL] WORKER TIMEOUT (pid:232) Jul 22 18:45:31 [2024-07-22 16:45:30 +0000] [232] [INFO] Worker exiting (pid: 232) Jul 22 18:45:32 [2024-07-22 16:45:32 +0000] [23] [WARNING] Worker with pid 232 was terminated due to signal 9 Jul 22 18:45:32 [2024-07-22 16:45:32 +0000] [238] [INFO] Booting worker with pid: 238 Jul 22 18:45:33 [2024-07-22 16:45:33 +0000] [23] [CRITICAL] WORKER TIMEOUT (pid:233) Jul 22 18:45:33 [2024-07-22 16:45:33 +0000] [23] [CRITICAL] WORKER TIMEOUT (pid:234) Jul 22 18:45:33 Not configuring telemetry due to BASEROW_ENABLE_OTEL not being set. Jul 22 18:45:33 [2024-07-22 16:45:33 +0000] [234] [INFO] Worker exiting (pid: 234) Jul 22 18:45:33 [2024-07-22 16:45:33 +0000] [233] [INFO] Worker exiting (pid: 233) Jul 22 18:45:34 Not configuring telemetry due to BASEROW_ENABLE_OTEL not being set. Jul 22 18:45:35 [2024-07-22 16:45:35 +0000] [23] [WARNING] Worker with pid 234 was terminated due to signal 9 Jul 22 18:45:35 [2024-07-22 16:45:35 +0000] [23] [WARNING] Worker with pid 233 was terminated due to signal 9 Jul 22 18:45:35 [2024-07-22 16:45:35 +0000] [23] [DEBUG] 2 workers Jul 22 18:45:35 [2024-07-22 16:45:35 +0000] [240] [INFO] Booting worker with pid: 240 Jul 22 18:45:35 [2024-07-22 16:45:35 +0000] [23] [DEBUG] 3 workers Jul 22 18:45:35 172.18.0.1 - - [22/Jul/2024:16:45:35 +0000] "GET /_health HTTP/1.1" 200 162743 "-" "Mozilla (CloudronHealth)"I have tried both restoring a backup from previous days and updating to the latest version, and the time for both processes far exceeds 30 minutes for each operation, which is not normal.
Any suggestions or indications of what might be happening?
-
It has happened when upgrading from package version 1.19.2 to 1.20.0.
I have tested the application in Recovery Mode and running
/app/pkg/start.shmanually and the application works, but when I exit Recovery Mode, the application stays in Not responding state. -
Hm this usually indicates the app running out of memoty (recovery mode does not limit memory) or something tries to write to read-only filesystem. At least here the issue does not show up in my test instance. Are there any special settings or app configs you were using?
-
Hi @nebulon
No, the Baserow application has the standard configuration with which it is installed. Using it daily only stores about 100 rows in a table corresponding to the current month. It has been operating normally, until this anomaly occurred.
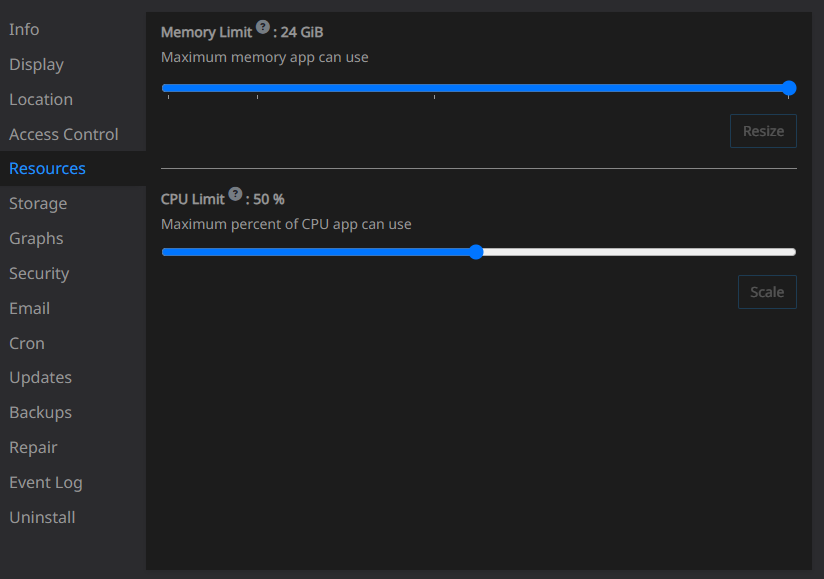
I have raised the memory available for the application to the maximum available, and it still does not work. The application marks running but the frontend cannot be accessed.
Furthermore, as you can see in the following screenshot, the memory barely exceeds normal consumption, but the CPU consumption slows down the operation of other applications on the server.
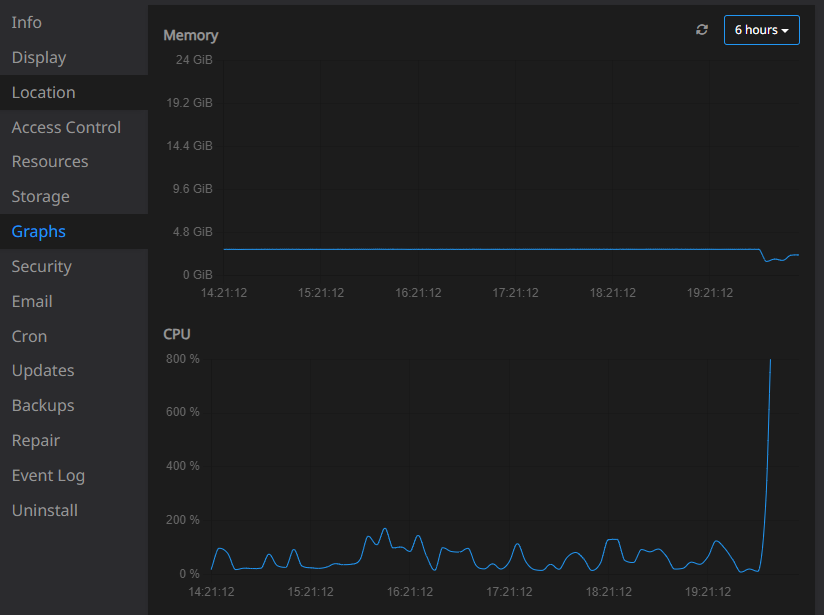
However, in recovery mode, with an allocation of 8 Gb of memory, the consumption of both memory and CPU is normal (you can see it in the hours before the screenshot, before the changes).
-
It very much seems like an app bug in the new version you are hitting here. Not sure if we can help you debug this without app specific expertise. Have you contacted upstream app devs and issue tracker about this already?
To stay in operation, have you tried to clone the non-updated, working version and then only update the cloned app to see if this is easily reproducible?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login