How to run local Llama 3.1 405b with RAG with Cloudron?
-
Llama 3.1 405b is a recently released, Free software Large Language model which is highly capable and setting the standard on leaderboards. RAG (Retrieval Augmented Generation) is where an AI agent is used by the language model to "go out onto the internet", find the appropriate, current data and then use that to help formulate a response to a query.
Because Llama 3.1 405b is very large, expensive hardware is needed to generate timely responses to queries.
Does anybody have suggestions about how to setup and run a llama 3.1 405b model with RAG, perhaps using Cloudron? Where would you host it? If it were for private use and you were not expecting to run queries 24/7, where would you run it?
https://blog.runpod.io/run-llama-3-1-405b-with-ollama-a-step-by-step-guide/
-
@LoudLemur Of course the answer depends on how much money you are willing to spend per month. I would probably wait until someone creates a 7b parameter model with only slightly less performance vs. competitive solutions. Then you have many more options - including self-hosting on your own hardware. I don't think Cloudron is the right platform to use in this case solely because all applications are Docker-based and some of the components required to run these modals (CUDA libraries, Torch, etc.) do not play well in a Docker environment. [Note: This was recently shared by an AI engineer during our conversation, but like everything in AI, it is almost obsolete as soon as it is published. So take this advice with a grain of salt and double-check its accuracy, especially over time.]
-
Llama 3.1 405b is a recently released, Free software Large Language model which is highly capable and setting the standard on leaderboards. RAG (Retrieval Augmented Generation) is where an AI agent is used by the language model to "go out onto the internet", find the appropriate, current data and then use that to help formulate a response to a query.
Because Llama 3.1 405b is very large, expensive hardware is needed to generate timely responses to queries.
Does anybody have suggestions about how to setup and run a llama 3.1 405b model with RAG, perhaps using Cloudron? Where would you host it? If it were for private use and you were not expecting to run queries 24/7, where would you run it?
https://blog.runpod.io/run-llama-3-1-405b-with-ollama-a-step-by-step-guide/
@LoudLemur We planned to buy servers especially for AI for our company uses. This configuration is for entreprise use so i don't know if it's gonna help you but to run Lamma 3.1 405b we planned using something like this :
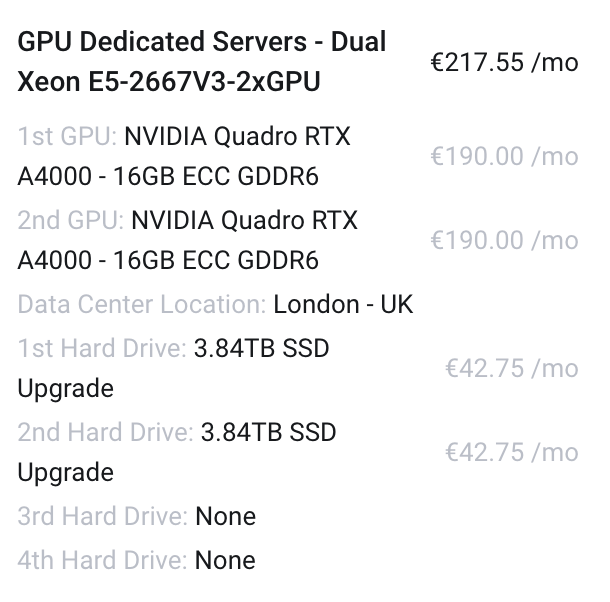
With 384gb RAM minimum, maybe more, we have to run tests to see if the models we want to use are using RAM or only GPU's.
We plan to place the order at BinaryRacks. -
@Dont-Worry Be careful of the GPU RAM (16GB in your case). More GPU RAM will allow larger models to run more efficiently. CPU cores + CPU RAM were much slower (~8x) in our tests with a 7b model vs. running the same load across GPUs.
-
@humptydumpty Let me suggest a great book to read: Co-Intelligence, by Ethan Mollick. I have read 70% of the book and am coming to the same opinion as the author: "invite AI to your work table all the time". Whether its writing an article, marketing study, presentation or report, it can help create the first draft (edit and polish it yourself). It can generate example code (fix, check and correct it yourself). I find AI helps when you are staring at a blank screen wondering where to start. It can generate many ideas, but it is best when you evaluate and refine them.
I also found the author presented some great examples of using "prompt engineering" and "personas" to get better results. But there are also subtle reminders in the book about training bias, how AI tries to generate answers that "please us humans", and its inherent limitations and why the same prompt will generate inconsistent responses. Like any tool, it needs to be wielded by a trained craftsman. It can help you get work done faster, but it can also help you get to the wrong answer very quickly.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login