Nextcloud in Error state even though it's running (after Cloudron 5.5 update)
-
@necrevistonnezr Do you think you can stop the existing nextcloud and then maybe clone from the latest backup and check if postgres is still using a lot of CPU? If it works out, maybe you can then just move stopped nextcloud into another domain and then put the cloned one there.
-
@necrevistonnezr Do you think you can stop the existing nextcloud and then maybe clone from the latest backup and check if postgres is still using a lot of CPU? If it works out, maybe you can then just move stopped nextcloud into another domain and then put the cloned one there.
@girish said in Nextcloud in Error state even though it's running (after Cloudron 5.5 update):
@necrevistonnezr Do you think you can stop the existing nextcloud and then maybe clone from the latest backup and check if postgres is still using a lot of CPU? If it works out, maybe you can then just move stopped nextcloud into another domain and then put the cloned one there.
Clone Nextcloud into another subdomain you mean? How do I do that?
EDIT: Found it.
-
What was the root cause if you found it?
On a side note postgres really gets hammered with SELECTs during for example a rescan of nextcloud files.@nebulon said in Nextcloud in Error state even though it's running (after Cloudron 5.5 update):
What was the root cause if you found it?
On a side note postgres really gets hammered with SELECTs during for example a rescan of nextcloud files.I meant I found the cloning process, I haven't found the cause for the CPU spikes.
I'm trying go clone a backup to a new subdomain but I don't have enough free space to clone a 300 GB Nextcloud instance...
-
@necrevistonnezr Do you think you can stop the existing nextcloud and then maybe clone from the latest backup and check if postgres is still using a lot of CPU? If it works out, maybe you can then just move stopped nextcloud into another domain and then put the cloned one there.
@girish said in Nextcloud in Error state even though it's running (after Cloudron 5.5 update):
@necrevistonnezr Do you think you can stop the existing nextcloud and then maybe clone from the latest backup and check if postgres is still using a lot of CPU? If it works out, maybe you can then just move stopped nextcloud into another domain and then put the cloned one there.
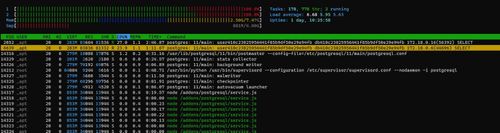
I did that now. Took 10 hours. Result is the same. 100 % CPU on Postgres on Nextcloud (app id 410c...). This is HUGELY frustrating. And I can't even login, it takes forever.
-
No, I switched off all clients on purpose - and after cloning to a new subdomain, there would be no connection, anyway.
-
maybe some plugin causes this? Can you use the
occtool via terminal into the app to disable some?@nebulon said in Nextcloud in Error state even though it's running (after Cloudron 5.5 update):
maybe some plugin causes this? Can you use the
occtool via terminal into the app to disable some?I think only the bare minimum is enabled....
occ app:list Enabled: - accessibility: 1.5.0 - activity: 2.12.0 - admin_audit: 1.9.0 - calendar: 2.0.3 - cloud_federation_api: 1.2.0 - comments: 1.9.0 - contacts: 3.3.0 - contactsinteraction: 1.0.0 - dav: 1.15.0 - encryption: 2.7.0 - federatedfilesharing: 1.9.0 - files: 1.14.0 - files_external: 1.10.0 - files_pdfviewer: 1.8.0 - files_rightclick: 0.16.0 - files_sharing: 1.11.0 - files_trashbin: 1.9.0 - files_versions: 1.12.0 - files_videoplayer: 1.8.0 - firstrunwizard: 2.8.0 - logreader: 2.4.0 - lookup_server_connector: 1.7.0 - nextcloud_announcements: 1.8.0 - notifications: 2.7.0 - oauth2: 1.7.0 - password_policy: 1.9.1 - photos: 1.1.0 - privacy: 1.3.0 - provisioning_api: 1.9.0 - recommendations: 0.7.0 - serverinfo: 1.9.0 - settings: 1.1.0 - sharebymail: 1.9.0 - spreed: 9.0.3 - support: 1.2.1 - systemtags: 1.9.0 - text: 3.0.1 - theming: 1.10.0 - twofactor_backupcodes: 1.8.0 - twofactor_totp: 4.1.3 - updatenotification: 1.9.0 - user_ldap: 1.9.0 - viewer: 1.3.0 - workflowengine: 2.1.0 Disabled: - bookmarks - bruteforcesettings - documentserver_community - federation - mail - maps - ransomware_detection - survey_client - tasks - twofactor_admin -
To be clear: Postgres goes crazy if I try to login from a browser or a client...
-
To be clear: Postgres goes crazy if I try to login from a browser or a client...
Can I somehow go back to an earlier Postgres version? This right now is killing my server and my workflow.
-
This is not related to the thread directly (but I was wondering about if we do make db rollbacks even possible). Do you use other apps that use Postgres? I realize this is not immediately obvious and hard to tell
 . For example, GitLab is now incompatible with the older postgres and then some of the newer apps like loomio require some of the Postgres extensions we have enabled (maybe one of these extensions is causing CPU use). If it's possible, as @nebulon said we can take a look.
. For example, GitLab is now incompatible with the older postgres and then some of the newer apps like loomio require some of the Postgres extensions we have enabled (maybe one of these extensions is causing CPU use). If it's possible, as @nebulon said we can take a look. -
@necrevistonnezr Ah ok, I guess all of them are mysql. That does make it easier to debug. Please write when possible, we can look into it asap.
-
We hit this with another user now and I think the root cause is that the migration only partially imported the database. This is causing nextcloud to do a log of queries (maybe some internal loop).
To fix this (please do all this carefully, if you not are confident just reach out to support@cloudron.io and we can do it for you):
-
Give the postgresql service a lot more memory (
Services->PostgreSQL). There is no good number for this, just give it as much as you can. It's harmless since you can always scale it down later after the import. -
First, identify the backup of the app that was created before the Cloudron updated to 5.5.0. From this backup, copy over the postgresqldump file. Assuming
f6e87030-2102-4c6c-b8eb-b2d86a268917is the id of the nextcloud app:
# cp /home/yellowtent/appsdata/f6e87030-2102-4c6c-b8eb-b2d86a268917/postgresqldump /root/postgresqldump.current # cp /from/the/app/backups/postgresqldump /home/yellowtent/appsdata/f6e87030-2102-4c6c-b8eb-b2d86a268917/postgresqldumpOn your PC/Mac (not Cloudron!), then use the CLI tool to import the data in-place. This command simple re-imports the database that we just copied above.
$ cloudron import --in-place --app nextcloud.domain.comIf you had generated some files in the past few days, you should run the occ scan again - https://cloudron.io/documentation/apps/nextcloud/#rescan-files after nextcloud is running again.
-
-
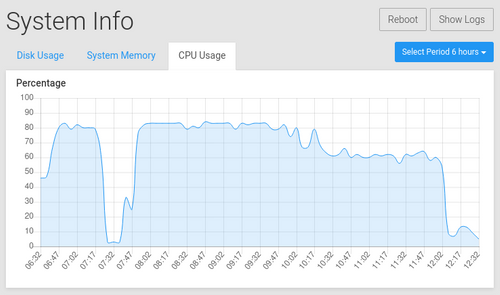
CPU usage after the re-import:
-
Since I was pressured for time, I re-setup Nextcloud from scratch, imported the backup and went that route. Really stressful and I hope I don't have to do that again. Makes you realize why you pay for certain cloud services...
-
@necrevistonnezr thanks for the update. We have fixed the code in the meantime that causes this.
-
@necrevistonnezr thanks for the update. We have fixed the code in the meantime that causes this.
@girish Now I know why support didn't work out: Cloudron blocked my answer from my Cloudron mail account to you guys - as mail relay via Sendgrid - as spam.... (!)
FYI: the shown IP 167.89.12.138 does indeed belong to Sendgrid.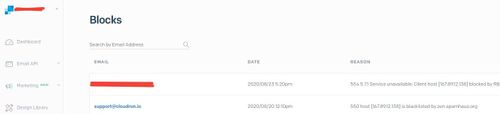
So mail relay via Sendgrid from the Cloudron mail server is not reliable, I guess....
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login