H2O LLM Studio, no-code GUI, fine-tuning LLMs
-

Welcome to H2O LLM Studio, a framework and no-code GUI designed for
fine-tuning state-of-the-art large language models (LLMs).
https://github.com/h2oai/h2o-llmstudio/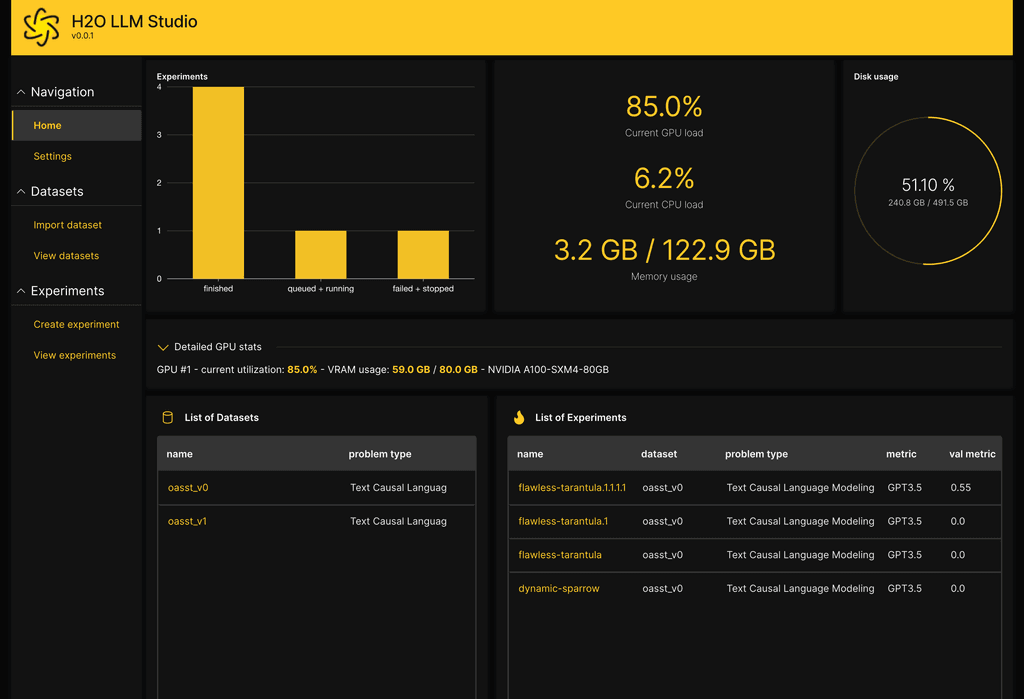
With H2O LLM Studio, you can
- easily and effectively fine-tune LLMs without the need for any coding experience.
- use a graphic user interface (GUI) specially designed for large language models.
- finetune any LLM using a large variety of hyperparameters.
- use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint.
- use advanced evaluation metrics to judge generated answers by the model.
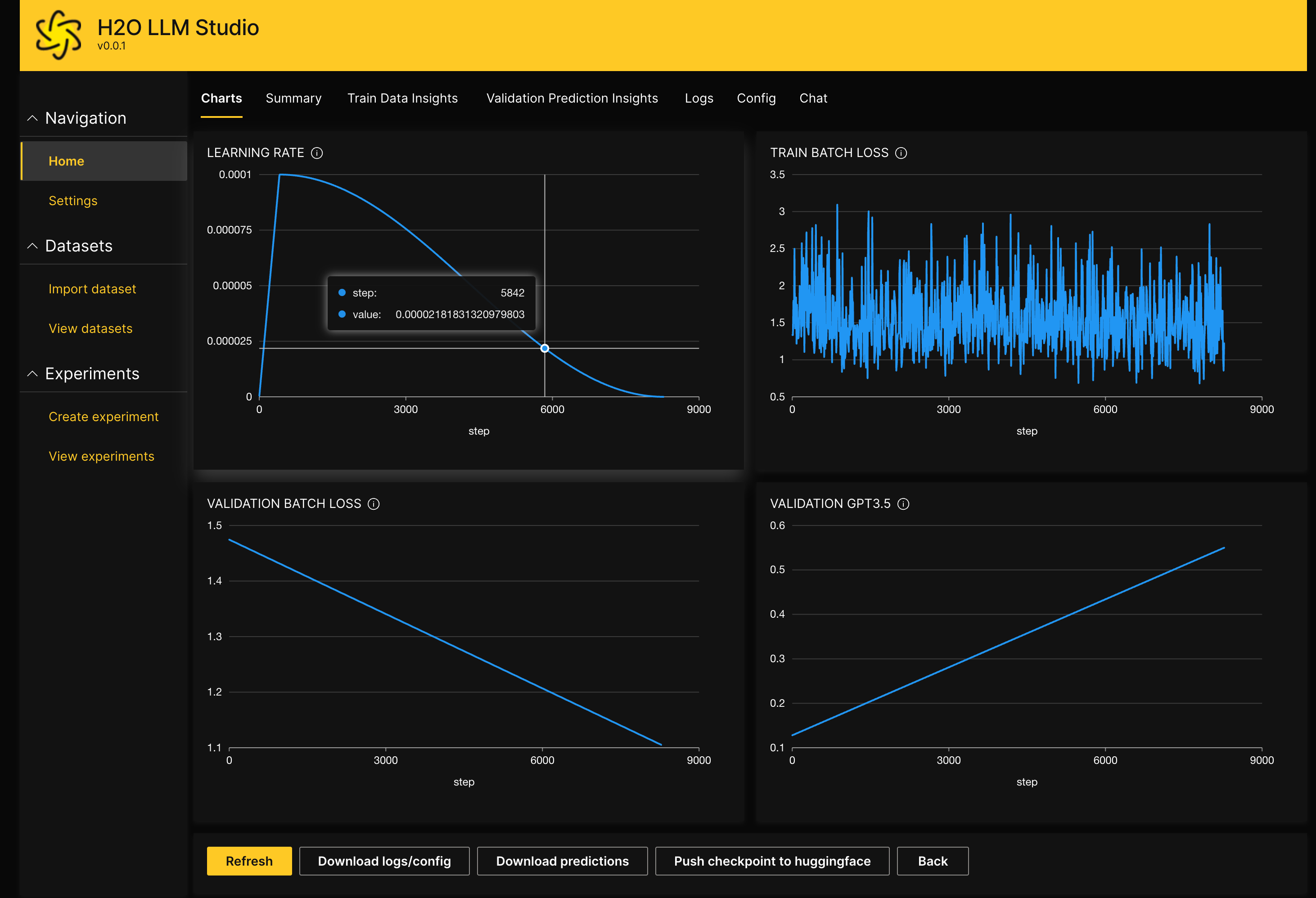
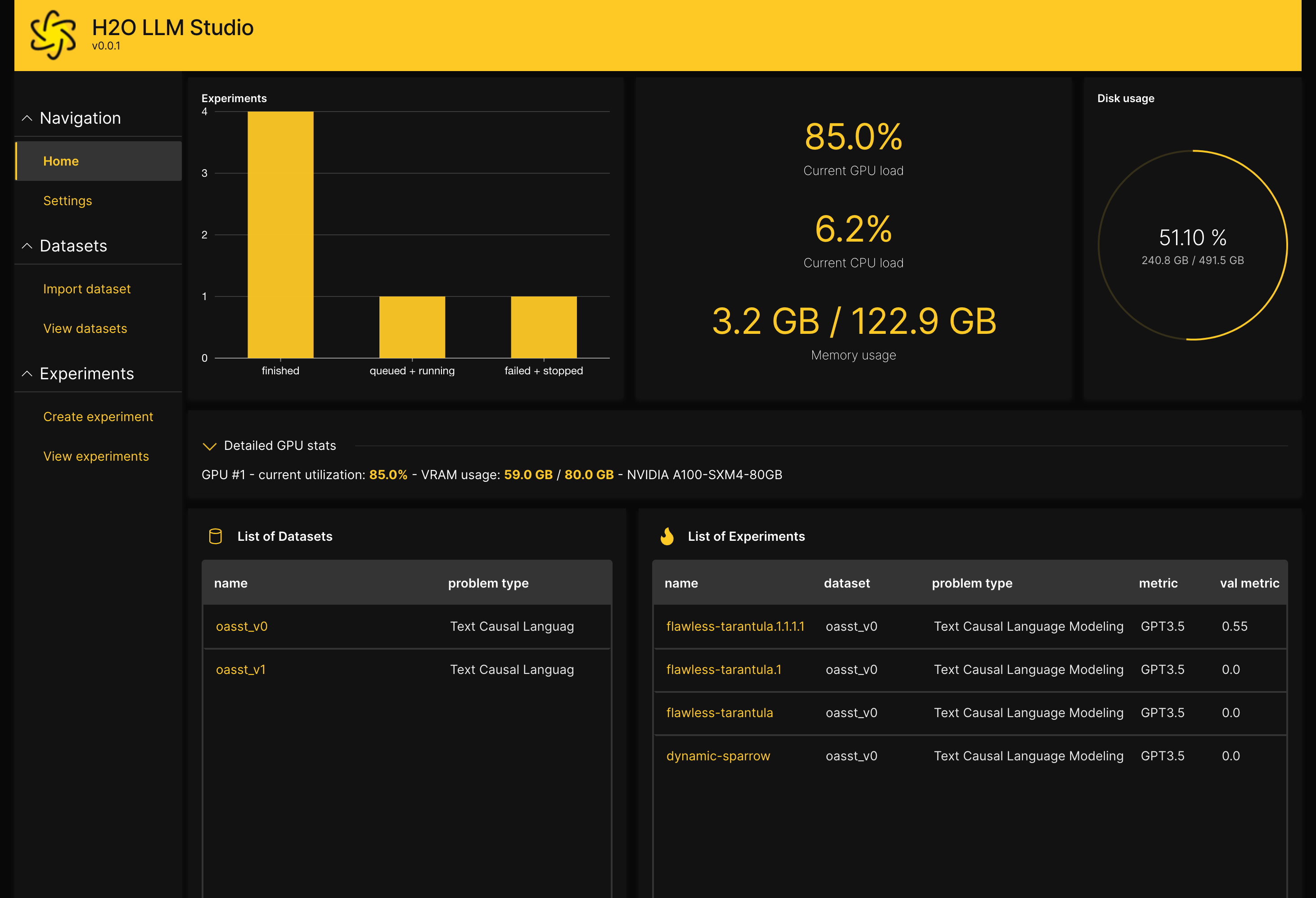
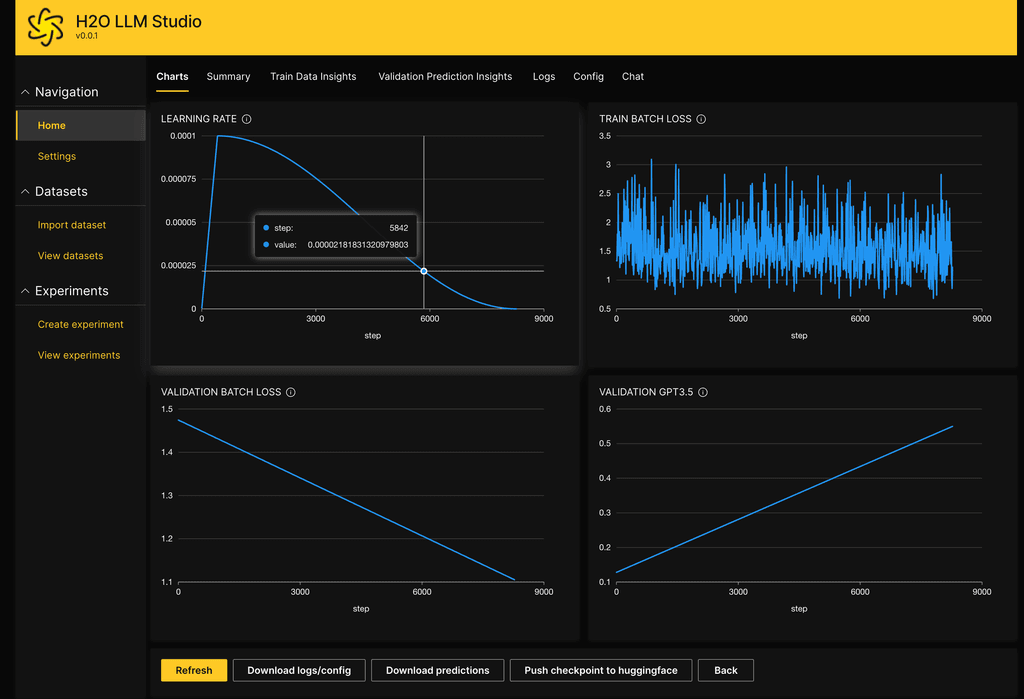
- track and compare your model performance visually. In addition, Neptune integration can be used.
- chat with your model and get instant feedback on your model performance.
- easily export your model to the Hugging Face Hub and share it with the community.
Quickstart
For questions, discussing, or just hanging out, come and join Discord!
We offer several ways of getting started quickly.
Using CLI for fine-tuning LLMs:


-
Well done on finding this one, @robi ! I was about to suggest it myself.
How did I miss it here?https://huggingface.co/h2oai
https://gpt-gm.h2o.ai/There is a video of a chap using it with Falcon 40b here:
https://invidious.io.lol/watch?v=H8Dx-iUY49s&quality=dashI can't seem to find that model there, at the moment. https://falcon.h2o.ai/
Near the very end, you can see him upload / link by URL a document which he then interrogates using the AI.
-
Welcome to H2O LLM Studio, a framework and no-code GUI designed for
fine-tuning state-of-the-art large language models (LLMs).
https://github.com/h2oai/h2o-llmstudio/
With H2O LLM Studio, you can
- easily and effectively fine-tune LLMs without the need for any coding experience.
- use a graphic user interface (GUI) specially designed for large language models.
- finetune any LLM using a large variety of hyperparameters.
- use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint.
- use advanced evaluation metrics to judge generated answers by the model.
- track and compare your model performance visually. In addition, Neptune integration can be used.
- chat with your model and get instant feedback on your model performance.
- easily export your model to the Hugging Face Hub and share it with the community.
Quickstart
For questions, discussing, or just hanging out, come and join Discord!
We offer several ways of getting started quickly.
Using CLI for fine-tuning LLMs:
-
@LoudLemur no different than ones you would use to run the other projects that can run models with.
-
Lots of work has continued on this project:
https://github.com/h2oai/h2o-llmstudio/compare/v0.0.1...v1.14.1Here is an ai summary of the main improvements:
"Overview
H2O.ai's h2o-llmstudio, a tool for fine-tuning large language models (LLMs), has evolved significantly from its initial version (v0.0.1) to the latest (v1.14.1). This software, designed for both technical and non-technical users, has introduced new features and optimizations that enhance its functionality for enterprise applications.
Technical Advancements
The software has added support for new problem types, such as causal regression and classification modeling, making it versatile for different tasks. It has also shifted from Reinforcement Learning from Human Feedback (RLHF) to more efficient methods like Direct Preference Optimization (DPO) and Inverse Preference Optimization (IPO), improving training efficiency. Additionally, Deepspeed integration for distributed training and advanced techniques like Low-Rank Adaptation (LoRA) have boosted performance, especially for larger models.
Performance and Cost Benefits
Research indicates significant performance improvements, with fine-tuned models reducing costs by up to 70% and cutting inference time by 75%. It can now handle 500% more requests, making it scalable for high-demand scenarios. In benchmarks like GAIA, it achieved 79.7% accuracy, nearing human-level performance at 92%, outperforming competitors.
Usability Enhancements
The no-code GUI has been refined, making it easier for users without coding experience to fine-tune LLMs. Features like a single max_length setting and improved user secrets handling with the 'keyring' library enhance usability and security. Integration with tools like Neptune and Weights & Biases (W&B) also helps track and compare model performance.Technical Advancements
The software has introduced several new problem types, enhancing its applicability across various use cases:
Causal Regression Modeling: Added in recent updates, this feature supports single-target regression tasks using LLMs, as noted in pull request (PR) 788 on the GitHub repository. This allows for more advanced predictive modeling.Causal Classification Modeling: Introduced via PR 449, it supports binary and multiclass classification, expanding the software's utility for classification tasks.
DPO/IPO Optimization: A significant shift occurred with the introduction of Direct Preference Optimization (DPO) and Inverse Preference Optimization (IPO) as alternatives to RLHF, starting with PR 530. This was further solidified with PR 592, which began deprecating RLHF, and PR 747, which fully removed it in favor of DPO/IPO/KTO (Kullback-Leibler Divergence-based Training Objective) optimization. This change improves training stability and efficiency.
Additional technical enhancements include:
Deepspeed Integration: PR 288 introduced Deepspeed for sharded training on multiple GPUs with NVLink, replacing Fully Sharded Data Parallel (FSDP). This is particularly beneficial for large-scale distributed training, requiring CUDA toolkit 12.1.Advanced Optimization Techniques: Support for Low-Rank Adaptation (LoRA) and 4-bit QLoRA, mentioned in external announcements, reduces memory footprint and enables faster training, especially for resource-constrained environments.
Performance and Scalability Improvements
The software has seen measurable performance gains, as highlighted in recent business announcements:
Cost Reduction: Fine-tuned open-source LLMs have reduced expenses by up to 70%, making it cost-effective for enterprises.
Latency Improvement: Optimized processing has cut inference time by 75%, enhancing real-time application performance.
Scalability: The platform now handles 500% more requests than previous versions, as noted in the same announcement, making it suitable for high-demand scenarios.
Benchmark performance is also notable:
In the GAIA benchmark, h2oGPTe Agent achieved 79.7% accuracy, with human-level performance measured at 92%, outperforming general-purpose models from Google and Microsoft, which scored below 50% H2O.ai Breaks New World Record for Most Accurate Agentic AI for Generalized Assistants.Usability and User Experience Enhancements
H2O LLM Studio has focused on improving accessibility and usability:
No-Code GUI: The no-code interface, a core feature since its inception, has been refined, making it intuitive for users without coding experience, as mentioned in external blogs and LinkedIn posts.
Configuration Simplification: PR 741 introduced a single max_length setting, resembling the chat_template functionality from the transformers library, simplifying model setup.
User Secrets Handling: PR 364 improved security with support for the 'keyring' library, including automatic migration of user settings, enhancing data protection.
Integration with Tools: Integration with Neptune and Weights & Biases (W&B) for experiment tracking and performance comparison, as noted in AWS Marketplace listings
, improves workflow efficiency.
Model Support and Deployment Flexibility
The software now supports a broader range of LLMs:
Models like DeepSeek, Llama, Qwen, H2O Danube, and H2OVL Mississippi are supported, as mentioned in recent announcements, allowing users to fine-tune diverse state-of-the-art models.Deployment options have been expanded to include on-premises, cloud VPCs, or air-gapped environments, ensuring data privacy and compliance, as highlighted in platform descriptions
.
Evaluation and Export Capabilities
Advanced Evaluation Metrics: Users can now judge generated answers using advanced metrics, improving model reliability, as noted in AWS Marketplace details.Model Export: The ability to export fine-tuned models to the Hugging Face Hub for sharing and collaboration has been enhanced, facilitating community engagement
"
Category Initial (v0.0.1) Latest (v1.14.1) Impact Problem Types Limited to basic fine-tuning Includes causal regression, classification Expanded use cases Optimization Techniques RLHF-based DPO/IPO/KTO, Deepspeed, LoRA, QLoRA Improved efficiency, reduced memory use Scalability Basic, limited requests Handles 500% more requests Enhanced for enterprise needs Cost Efficiency Standard costs Up to 70% cost reduction Significant savings Latency Higher inference time 75% reduction in inference time Faster real-time applications Usability Basic GUI Enhanced no-code GUI, keyring support More accessible to non-coders Model Support Limited models Supports DeepSeek, Llama, etc. Broader model compatibility Benchmark Performance Not specified 79.7% GAIA accuracy, 92% human-level Competitive edge in accuracy
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login