Unrecoverable NodeBB error after NPM install

-
Dear Support, I got this error message after rebooting the app. Recovering the unsuccessful from stable backup
- It's not possible to reboot from dashboard or put it into recovery mode
- Terminal for the app doesn't open (file explorer does)
- Uninstalling the app is not possible. **Error message: Cloudron Error
- getaddrinfo EAI_AGAIN api.cloudron.io**
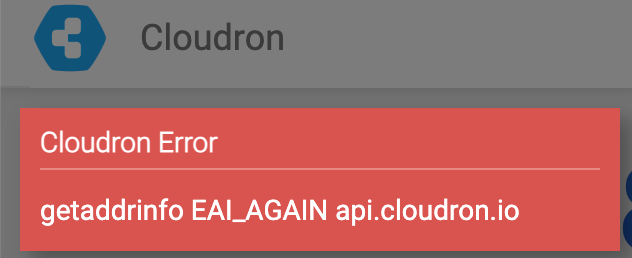
- The error seems to affect the Cloudron app store as well. Nothing loads...
See repair options below.
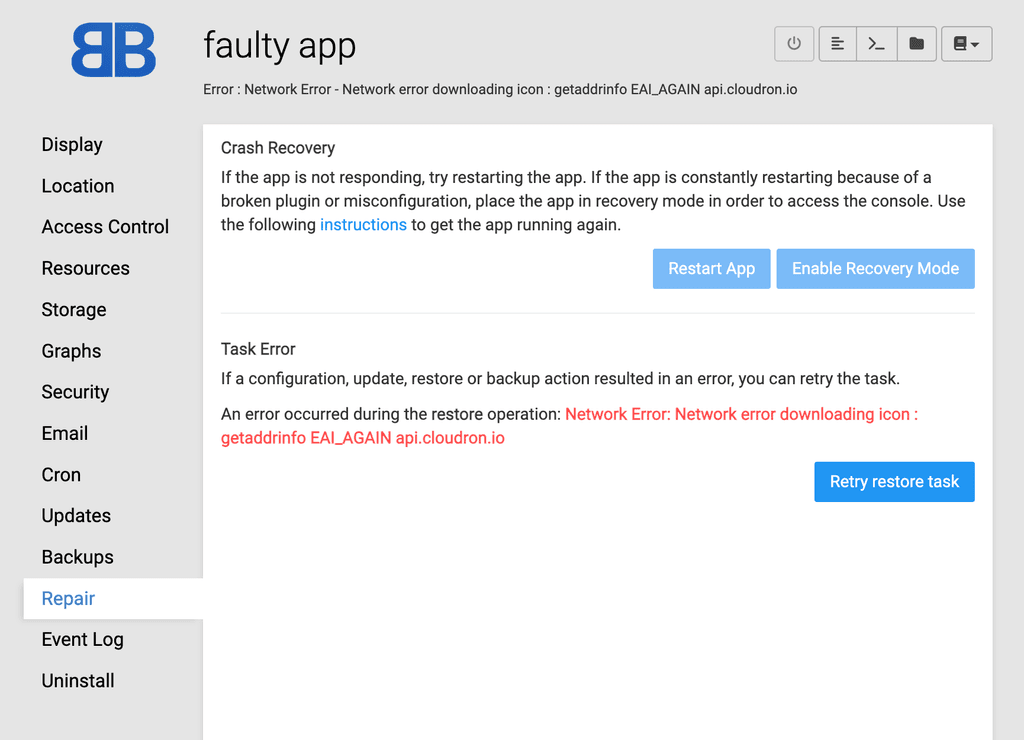
This happened after
- I tried to install some NPM packages over the cloudron terminal for NodeBB.
- The install didn't go through (write error)
- I created a temp folder to install NPM and force my way through.
mkdir /tmp/my_modules cd /tmp/my_modules chmod -R 777 /tmp/my_modules npm install nodebb-plugin-calendar@latestInstall stalled and probably didn't go through. The plugins list in NodeBB ACP didn't load properly first. After rebooting nodeBB, it must have broke the container
 Any suggestions on how to fix this?
Any suggestions on how to fix this? -
SOLVED: Thank you for the suggestions. The api.cloudron.io might have been down temporarily.
- I ran host api.cloudron.io and it resolved to an IP address
- I found it strange, so I opened the app store and indeed everything was loading.
- Then I tried the recovery again to a stable version. It connected to the API to pull the image.
- After recovery the app was non responsive. It asked me to follow https://docs.cloudron.io/troubleshooting/#unresponsive-app
- I went into recovery mode, but couldn't find the correct script like "start.sh" to restart it.
- Without doing anything I disabled recovery mode and restarted the app. Opened to logs and it showed, it started reponding.

- It's working fine now.
I am bit surprised and concerned that the API connection has such a strong impact on recovery. If the API is not reachable then the correct image won't re-download. Bringing recovery to a stall. I am testing currently, but in production this can be a blocker. Is there a way to preload the image on Cloudron instance in case of emergency?
-
The root cause here is not
api.cloudron.ioas such but that DNS was not working in general. If DNS is not working, many things fail - for example, download docker images, download app manifest information etc. The icon download is one of the first things that happen in an app's lifecycle, so it's the error that gets reported.Maybe we can add a "check dns" step to give a better error message but DNS failing is generally an exception.
-
That makes sense, and I support the idea. The error message points the blame to the API and not the DNS. Modifying the error message to check the DNS first definitely saves time on the troubleshooting end and on yours.
Even if it's the exception the it's worth considering how much time it takes to check for each step during the process. Anyways thanks for the help. You can close this thread
")
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login