Recurrent Cloudron Downtime - Request for Support
-
Dear Support Team,
For the past three weeks, we have been experiencing recurrent issues with our Cloudron instance. Specifically, the system goes down and all the applications hosted on it become unavailable. This has been happening 1-2 times per week during this period.
Each time this issue occurs, we are forced to restart the server on AWS to restore the services and make the applications accessible again. This situation is significantly impacting our organization, as our team members are unable to work with the tools hosted within the Cloudron container during these downtimes.
We have monitored the server resources (CPU, RAM, storage, etc.), and everything appears to be within normal ranges. Unfortunately, we do not have any logs or additional details to identify the root cause of these failures.
We kindly request your assistance in investigating and resolving this issue.
We appreciate your prompt support and look forward to your guidance to prevent further disruptions.
Best regards,
Felipe Rubilar
Cloud Engineer -
Hello @Felipe.rubilar
If you feel comfortable doing so, please provide the logs of your system, so people here can take a look.
Also, since you are monitoring CPU, RAM, storage, etc please provide some Screenshots of the weeks where this issue arrises. -
@Felipe.rubilar When the apps become unresponsive, is the server up? i.e can you ping the server? Can you ssh into the server?
If you are unable to SSH into the server, this indicates a problem on the server side. Which EC2 instance are you using? If you use lower end EC2 servers, they have a concept of CPU credits. This is usually the root cause of unresponsiveness.
-
Cloudron Performance Issues Analysis
Thank you for your responses and guidance. I've gathered additional information and performed a detailed analysis of the system resources, as you suggested. Here's what I've found:
1. Logs and Observations
- When the apps become unresponsive, the server itself is also unreachable (cannot ping or SSH into it)
- This confirms that the issue is likely on the server side
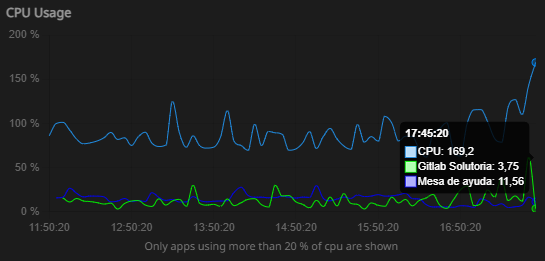
- I've attached screenshots of the CPU and memory usage graphs for the last 6 hours, which include the period leading up to the most recent downtime
2. Resource Analysis
CPU Usage:
- The CPU usage shows frequent spikes, with a peak of 169.2% (see attached graph)
- Most of the CPU usage does not seem to come from the applications themselves (e.g., GitLab and Mesa de Ayuda have low CPU usage)
- Since the instance is a
t3.large, which relies on CPU credits, I suspect that these spikes might be depleting the credits, causing the instance to slow down or become unresponsive
Memory Usage:
- The memory usage is consistently high, with 7.18 GiB of RAM used out of 8 GiB
- GitLab alone consumes 4.63 GiB, and the system is actively using swap (4.12 GiB)
- The reliance on swap could be degrading performance, especially during high memory demand
Nginx Warnings:
- I noticed several
ssl_staplingwarnings in the logs for the SSL certificates of my apps - While these are just warnings, I'm unsure if they could be contributing to the issue
3. Possible Root Cause
Based on the resource analysis, I believe the main issue might be resource limitations:
CPU Credits:
- The high CPU usage might be depleting the CPU credits of the
t3.largeinstance, leading to performance degradation
Memory Constraints:
- The high memory usage and reliance on swap suggest that the instance might not have enough RAM for the current workload
4. Next Steps and Questions
I'm considering upgrading the instance to address these limitations, but I'd like to confirm if this is the root cause of the downtime. Specifically:
- Does this analysis align with the symptoms of the instance becoming unresponsive?
- Would upgrading to a more powerful instance (e.g.,
t3.xlarge,m5.large, orm5.xlarge) resolve the issue? - Are there additional steps I should take to optimize the current setup or gather more diagnostic information?
Attachments
- CPU and Memory Usage Graphs
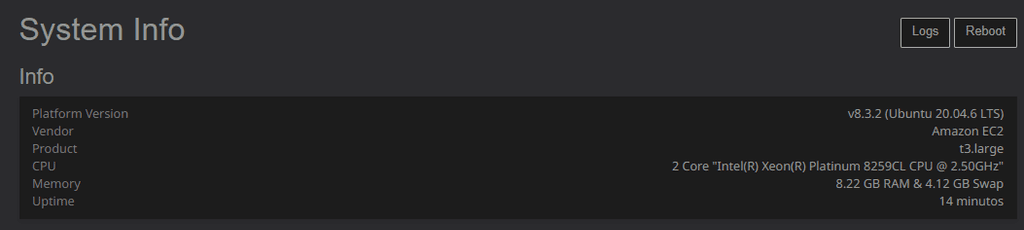
- System Info Screenshot
Thank you again for your help! I look forward to your insights.
Best regards,
Felipe Rubilar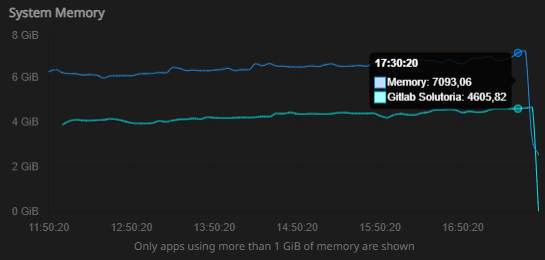
-
Just as a sidenote: Had similar issues recently - Nextcloud appeared to be the issue, more specifically Nextcloud brought the backup process into some strange shenanigans which crashed the whole VM.
I had no time to properly investigate, though, and we do not use nextcloud really, so I simply uninstalled it. Fixed it. -
J joseph has marked this topic as solved on
-
Hello everyone,
Thank you all for your support and suggestions throughout this process. I’m happy to report that the issue has been resolved.
After analyzing the resources and following the recommendations provided, we decided to upgrade the AWS instance from t3.large to t3.xlarge. This upgrade provided additional CPU and RAM, which addressed the resource limitations that were causing the server to become unresponsive.
Since the upgrade, we have not experienced any further downtime or performance issues. We can confirm that the problem was related to resource constraints, specifically the depletion of CPU credits and the high reliance on swap memory.
Thank you again for your help and guidance.
Best regards,
Felipe Rubilar -
Disk space. Ram. Probably the two* main components of a server that will make running Cloudron (or any software, really) a pleasure or a pain. But I think the easy answer isn't necessarily the best - buy a server with lots of disk space and lots of RAM - because use-case factors in alot. Perhaps some sort of pop-up questionnaire at some point in the purchase stream or set up process asking which apps are likely to be used would be one way to give a user a heads-up that their 4GB RAM, 60GB SSD server isn't going to cut it (or in this case an 8GB running Gitlab! Plus, it seems they are running additional software on that server, this "Mesa de Ayuda" which seems to be some kind of helpdesk software... Cloudron clearly advises running only Cloudron on a server and nothing else, so that was utilizing the same minimal 8GB of RAM).
That said, I moved my Mastodon app off of my main server which has 64GB RAM and successfully run it on another server with just 4GB RAM plus 4GB swap, plus a Wordpress app, with stable results. I've also run a Presearch node on a 3.5GB RAM server along with Cloudron, and it all worked.
*A third would be using Cloudflare. I know why ppl use it, I just don't know why ppl use it.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login