40GB Disk full with a single app - n8n
-
Due to the app being in "error state", I can't add a volume either.
The number of options at my disposal is starting to grow thin.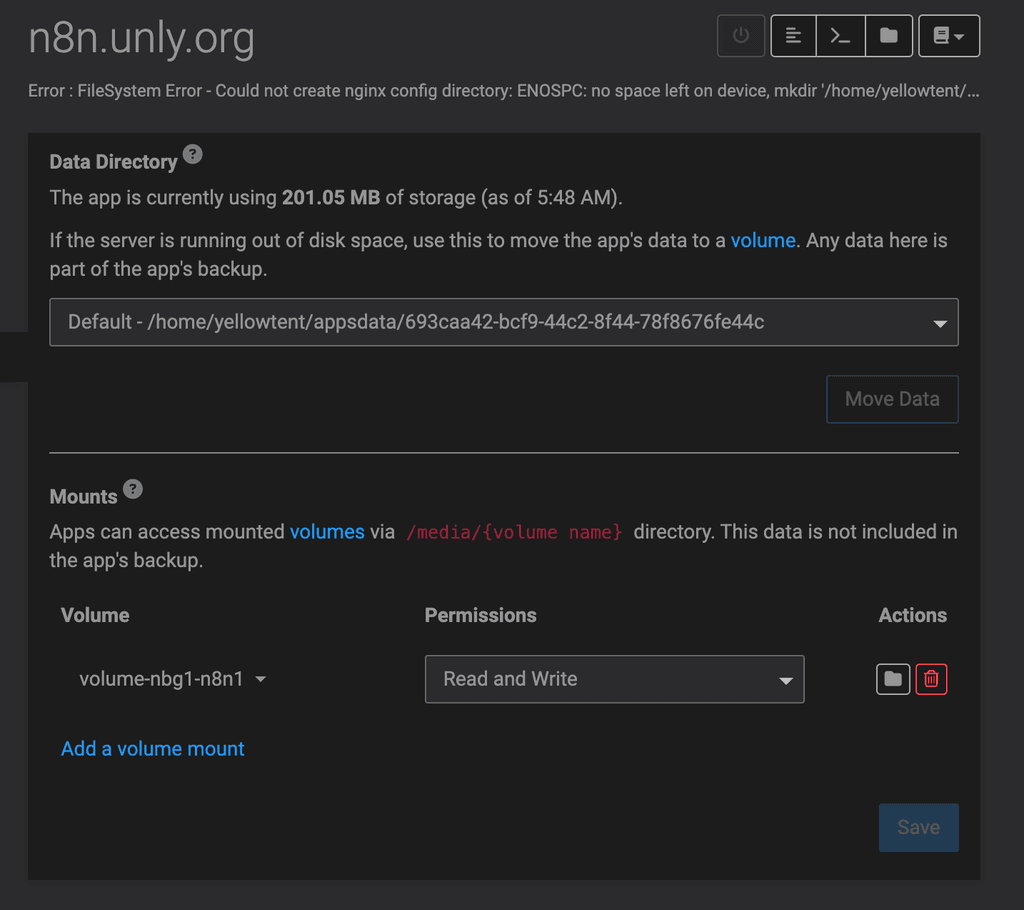
-
I thought Hetzner wasn't allowing me to rescale the instance to one with a bigger disk, but I was mistaken.
There was an option to hide different disks options.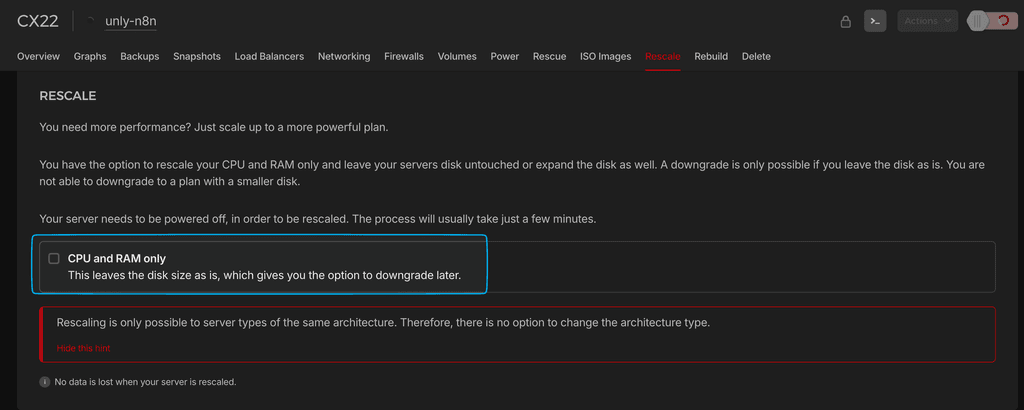
-
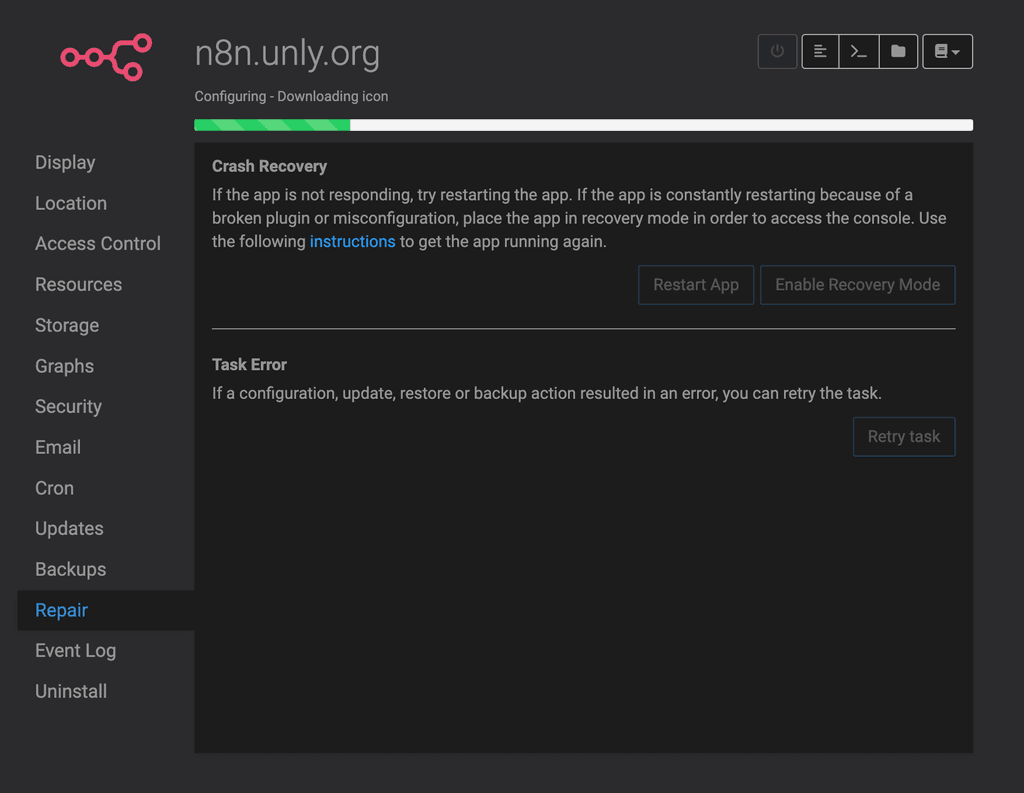
Despite the issue with the disk space being gone, n8n wouldn't restart due to being into "error state"...
So, I tried to click on
Retry configure task, but it failed with some dumb error about an icon not being fetchable...https://gist.github.com/Vadorequest/a57aa42f42c0e241a3076c17ba295b24
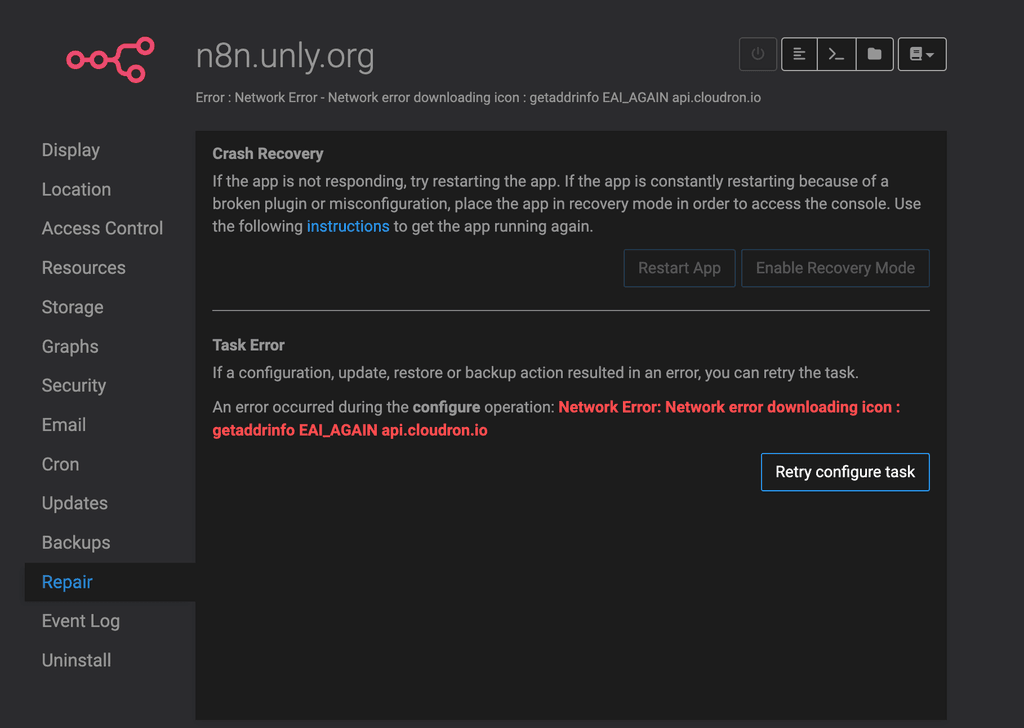
-
I tried to ping cloudron but the server doesn't seem to be willing.
root@unly-n8n:~# ping6 ipv6.api.cloudron.io ping6: ipv6.api.cloudron.io: Temporary failure in name resolution root@unly-n8n:~# ping ipv6.api.cloudron.io ping: ipv6.api.cloudron.io: Temporary failure in name resolution root@unly-n8n:~# ping api.cloudron.io ping: api.cloudron.io: Temporary failure in name resolution root@unly-n8n:~# ping google.com ping: google.com: Temporary failure in name resolutionI guess another restart might solve it...
-
Restarting didn't solve it. I don't know where this issue came from but I had to restart the DNS service
 .
.root@unly-n8n:~# ping google.com ping: google.com: Temporary failure in name resolution root@unly-n8n:~# cat /etc/resolv.conf # Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8) # DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN # 127.0.0.53 is the systemd-resolved stub resolver. # run "systemd-resolve --status" to see details about the actual nameservers. root@unly-n8n:~# systemd-resolve --status systemd-resolve: command not found root@unly-n8n:~# sudo systemctl restart systemd-resolved.service root@unly-n8n:~# ping google.com PING google.com(fra24s06-in-x0e.1e100.net (2a00:1450:4001:829::200e)) 56 data bytes 64 bytes from fra24s06-in-x0e.1e100.net (2a00:1450:4001:829::200e): icmp_seq=1 ttl=116 time=5.00 ms 64 bytes from fra24s06-in-x0e.1e100.net (2a00:1450:4001:829::200e): icmp_seq=2 ttl=116 time=3.83 ms 64 bytes from fra24s06-in-x0e.1e100.net (2a00:1450:4001:829::200e): icmp_seq=3 ttl=116 time=3.69 ms ^C --- google.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2004ms rtt min/avg/max/mdev = 3.694/4.174/4.997/0.584 ms root@unly-n8n:~# ping6 ipv6.api.cloudron.io PING ipv6.api.cloudron.io(prod.cloudron.io (2604:a880:800:10::b66:f001)) 56 data bytes 64 bytes from prod.cloudron.io (2604:a880:800:10::b66:f001): icmp_seq=1 ttl=49 time=84.4 ms 64 bytes from prod.cloudron.io (2604:a880:800:10::b66:f001): icmp_seq=2 ttl=49 time=82.8 msRunning
sudo systemctl restart systemd-resolved.servicefixed this ping issue. -
After the ping was fixed, the "Retry configure task" worked and the n8n instance was up again.
But it wouldn't show my n8n workflows.
Restarting the Cloudron app fixed it.
What a journey.
-
Journey not over, the issue with DNS seems to be still there.
Could not resolve hostname github.com: Temporary failure in name resolution, but the ping from the server itself seems to work fine, so it might be the docker instance that could be buggy... But I'm completely in unknown waters there.Jun 28 23:58:14 2024-06-28T21:58:14.702Z | error | 400 ssh: Could not resolve hostname github.com: Temporary failure in name resolution <30>1 2024-06-28T21:58:14Z unly-n8n 693caa42-bcf9-44c2-8f44-78f8676fe44c 1050 693caa42-bcf9-44c2-8f44-78f8676fe44c - fatal: Could not read from remote repository. -
The internal DNS service "Unbound" was off, I turned it on again.
https://docs.cloudron.io/troubleshooting/#unbound
root@unly-n8n:~# root@unly-n8n:~# systemctl status unbound × unbound.service - Unbound DNS Resolver Loaded: loaded (/etc/systemd/system/unbound.service; enabled; vendor preset: enabled) Active: failed (Result: exit-code) since Fri 2024-06-28 21:43:24 UTC; 26min ago Process: 1223 ExecStart=/usr/sbin/unbound -d (code=exited, status=1/FAILURE) Main PID: 1223 (code=exited, status=1/FAILURE) CPU: 17ms Jun 28 21:43:24 unly-n8n systemd[1]: unbound.service: Scheduled restart job, restart counter is at 5. Jun 28 21:43:24 unly-n8n systemd[1]: Stopped Unbound DNS Resolver. Jun 28 21:43:24 unly-n8n systemd[1]: unbound.service: Start request repeated too quickly. Jun 28 21:43:24 unly-n8n systemd[1]: unbound.service: Failed with result 'exit-code'. Jun 28 21:43:24 unly-n8n systemd[1]: Failed to start Unbound DNS Resolver. root@unly-n8n:~# unbound-anchor -a /var/lib/unbound/root.key root@unly-n8n:~# systemctl restart unbound root@unly-n8n:~# systemctl status unbound ● unbound.service - Unbound DNS Resolver Loaded: loaded (/etc/systemd/system/unbound.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2024-06-28 22:10:03 UTC; 3s ago Main PID: 6380 (unbound) Tasks: 1 (limit: 9160) Memory: 8.4M CPU: 100ms CGroup: /system.slice/unbound.service └─6380 /usr/sbin/unbound -d Jun 28 22:10:03 unly-n8n systemd[1]: Starting Unbound DNS Resolver... Jun 28 22:10:03 unly-n8n unbound[6380]: [6380:0] notice: init module 0: subnet Jun 28 22:10:03 unly-n8n unbound[6380]: [6380:0] notice: init module 1: validator Jun 28 22:10:03 unly-n8n unbound[6380]: [6380:0] notice: init module 2: iterator Jun 28 22:10:03 unly-n8n unbound[6380]: [6380:0] info: start of service (unbound 1.13.1). Jun 28 22:10:03 unly-n8n systemd[1]: Started Unbound DNS Resolver.And now my workflows are working (almost) properly.
I'll have to restart n8n again after re-enabling the node modules (i had disabled them because they were blocking the n8n boot due to packages not being installable due to the DNS issue) -
A AmbroiseUnly referenced this topic on
-
 G girish marked this topic as a question on
G girish marked this topic as a question on
-
G girish has marked this topic as solved on
-
Good to know! Thanks
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login