let's collect some metrics
-
@lukas said in let's collect some metrics:
I'm asking me which hardware are needed to get quick response?!
DEDI 8 Core "Intel(R) Xeon(R) CPU E3-1275 v5 @ 3.60GHz"
Memory 67.2 GB RAM & 34.33 GB Swap
APP RAM: 15.75 GiB
Model: llama2:latest (3.6GB)
PROMPT: Hello llama. How are you?
COMPL: blinks Hello there! scratches nose I'm feeling a bit woolly today, thank you for asking!

TIME: 22 secPROMPT: Tell me a random fun fact about the Roman Empire
COMPL: Did you know that the Roman Empire had a official "censor" position? The censor was responsible for keeping track of who was born, who died, and who got married within the empire! They also kept records of public crimes and acts of heroism. This position was important because it helped the emperor maintain control over the vast territories of the Roman Empire.
TIME: 25 secFirst time question about roman empire memory was at 2 GiB, so it took around 7 minutes.
Seems like dedi hardware with more processor power, and more RAM helps.
-
SAME MACHINE:
Model: mistral:latest
PROMPT: Tell me a random fun fact about the Roman Empire
COMPL: The Roman Empire was not only known for its impressive architecture, military might, and political structures, but also for its advanced system of roads. The Romans built an extensive network of paved roads, estimated to be over 50,000 miles (80,000 kilometers) long! This made it easier for the movement of armies and trade between different regions of the empire. An interesting fact about these roads is that they were often built using a layer of volcanic ash, pozzolana, which contributed to their durability and strength, paving the way for the modern concrete we use today.
TIME: 43 sec (more words in response though) -
Not surprisingly, this kind of app obviously requires much more power than the average app for a start. On the other hand, it's NOT that much of power, meaning it's relatively accessible to pretty much anyone who desires it hard enough, with relatively low starting budget.
-
Standard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 22.38 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 2 min
laughs Oh, hello there! twinkle in my eye I'm doing well, thank you for asking! winks It's always a pleasure to meet someone new. nuzzles your hand with my soft, fluffy nose How about you? What brings you to this neck of the woods? hops around in excitementStandard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 32 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 45 sec
chomps on some grass Hmmm? Oh, hello there! blinks I'm doing great, thanks for asking! stretches It's always a beautiful day when I get to spend it in this gorgeous green pasture. chews on some more grass How about you? What brings you to this neck of the woods?Standard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 50.63 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 35 sec
Ho there, friend! adjusts sunglasses I'm feeling quite well, thank you for asking! How about you? Have you had a good day?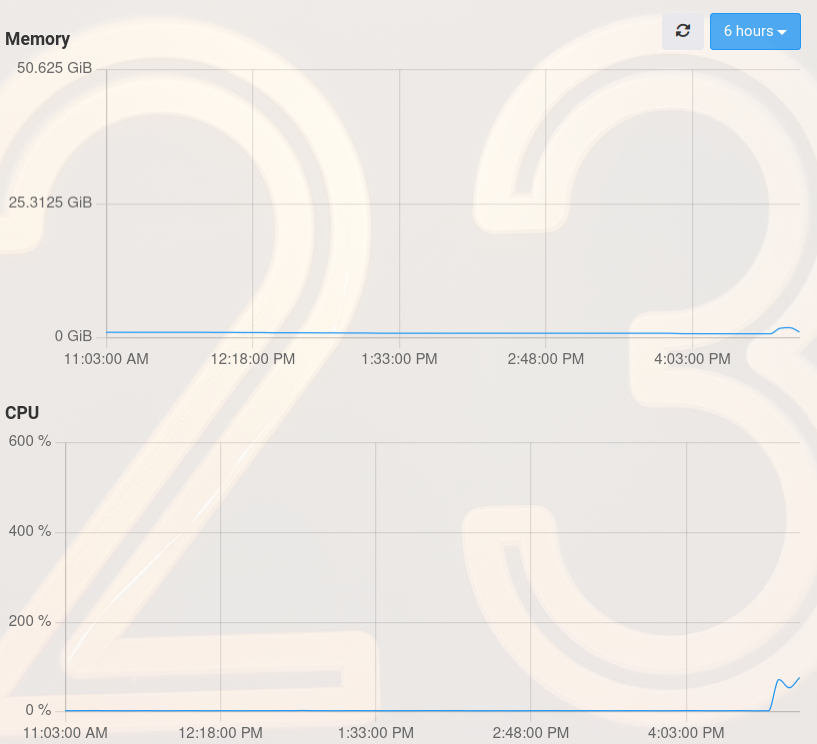
Pronouns: he/him | Primary language: German
-
Standard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 22.38 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 2 min
laughs Oh, hello there! twinkle in my eye I'm doing well, thank you for asking! winks It's always a pleasure to meet someone new. nuzzles your hand with my soft, fluffy nose How about you? What brings you to this neck of the woods? hops around in excitementStandard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 32 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 45 sec
chomps on some grass Hmmm? Oh, hello there! blinks I'm doing great, thanks for asking! stretches It's always a beautiful day when I get to spend it in this gorgeous green pasture. chews on some more grass How about you? What brings you to this neck of the woods?Standard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 50.63 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 35 sec
Ho there, friend! adjusts sunglasses I'm feeling quite well, thank you for asking! How about you? Have you had a good day?@luckow interesting how much slower your machine is even when allocating more RAM than @micmc did. And interesting that at the same time the graphs don't seem to show much of anything

I've got a dedicated Hetzner server with a little more power still:
As described by my Cloudron dashboard at #/system:
CPU: 12 Core "AMD Ryzen 5 3600 6-Core Processor"
Memory: 67.33 GB RAM & 34.33 GB SwapI'll join in this game when I get the chance and report back...
-
@luckow interesting how much slower your machine is even when allocating more RAM than @micmc did. And interesting that at the same time the graphs don't seem to show much of anything
I've got a dedicated Hetzner server with a little more power still:
As described by my Cloudron dashboard at #/system:
CPU: 12 Core "AMD Ryzen 5 3600 6-Core Processor"
Memory: 67.33 GB RAM & 34.33 GB SwapI'll join in this game when I get the chance and report back...
@jdaviescoates Yeah, I too am testing this on a dedicated server on Hetzner. Now, that reminds me of another factor on Hetz we're also on 1 Gbps pipes which is not the case of many providers and that could also be a factor, I guess.
@luckow are your VPSs on 1 Gbps connection to outside?
-
@lukas said in let's collect some metrics:
I'm asking me which hardware are needed to get quick response?!
DEDI 8 Core "Intel(R) Xeon(R) CPU E3-1275 v5 @ 3.60GHz"
Memory 67.2 GB RAM & 34.33 GB Swap
APP RAM: 15.75 GiB
Model: llama2:latest (3.6GB)
PROMPT: Hello llama. How are you?
COMPL: blinks Hello there! scratches nose I'm feeling a bit woolly today, thank you for asking!
TIME: 22 secPROMPT: Tell me a random fun fact about the Roman Empire
COMPL: Did you know that the Roman Empire had a official "censor" position? The censor was responsible for keeping track of who was born, who died, and who got married within the empire! They also kept records of public crimes and acts of heroism. This position was important because it helped the emperor maintain control over the vast territories of the Roman Empire.
TIME: 25 secFirst time question about roman empire memory was at 2 GiB, so it took around 7 minutes.
Seems like dedi hardware with more processor power, and more RAM helps.
@micmc said in let's collect some metrics:
DEDI 8 Core "Intel(R) Xeon(R) CPU E3-1275 v5 @ 3.60GHz"
Memory 67.2 GB RAM & 34.33 GB Swap
APP RAM: 15.75 GiB
Model: llama2:latest (3.6GB)
PROMPT: Hello llama. How are you?
COMPL: blinks Hello there! scratches nose I'm feeling a bit woolly today, thank you for asking!
TIME: 22 secI tried to my test as similar to this as possible, so:
Hetzner DEDI 12 Core "AMD Ryzen 5 3600 6-Core Processor"
Memory: 67.33 GB RAM & 34.33 GB Swap
APP RAM: 15.75 GiB
Model: llama2:latest (3.6GB)
PROMPT: Hello llama. How are you?
COMPL: chomps on some grass Ummm, hello there! gives a curious glance I'm doing great, thanks for asking! stretches It's always nice to meet someone new... or in this case, someone who is talking to me. winks How about you? What brings you to this neck of the woods? Or should I say, this mountain range? Hehe!
TIME: 5 sec (for it to begin writing), didn't actually time how long it took to finish...Same prompt, answered:
chomps on some grass Ummm, hello there! gives a curious glance I'm doing great, thanks for asking! stretches It's always nice to meet someone new... or in this case, someone who is talking to me. winks How about you? What brings you to this neck of the woods? Or should I say, this mountain range? Hehe!This time took maybe 10 seconds before it started writing and have finished after about 20 seconds.
Same everything but new prompt:
Tell me a random fun fact about the Roman Empire
Answer: Ooh, that's a great question! grins Did you know that during the height of the Roman Empire (around 100-200 AD), there was a gladiator named "Draco" who was so popular that he had his own comic book series?! 🤯 It's true! The Roman Empire really knew how to entertain their citizens, huh? chuckles
TIME: started writing it after about 3 seconds, finished after about 14. Not bad!
-
Standard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 22.38 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 2 min
laughs Oh, hello there! twinkle in my eye I'm doing well, thank you for asking! winks It's always a pleasure to meet someone new. nuzzles your hand with my soft, fluffy nose How about you? What brings you to this neck of the woods? hops around in excitementStandard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 32 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 45 sec
chomps on some grass Hmmm? Oh, hello there! blinks I'm doing great, thanks for asking! stretches It's always a beautiful day when I get to spend it in this gorgeous green pasture. chews on some more grass How about you? What brings you to this neck of the woods?Standard installation of the app, three models downloaded.
hosting provider: netcup
VPS: 6 Core "Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz", 33.66 GB RAM & 38.65 GB Swap
Open WebUI - Memory Limit : 50.63 GiB
Model: llama2:latest (3.6GB)
Prompt: Hello llama. How are you?
response after: 35 sec
Ho there, friend! adjusts sunglasses I'm feeling quite well, thank you for asking! How about you? Have you had a good day?@luckow I don't know enough about the hardware requirements for Ollama, but maybe it is slow because your VPS doesn't have a GPU?
I just tested it on a server with the following specs:
CPU: Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz
GPU: NVIDIA Corporation GV100GL [Tesla V100S PCIe 32GB]
RAM: 64 GB
-
@luckow I don't know enough about the hardware requirements for Ollama, but maybe it is slow because your VPS doesn't have a GPU?
I just tested it on a server with the following specs:
CPU: Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz
GPU: NVIDIA Corporation GV100GL [Tesla V100S PCIe 32GB]
RAM: 64 GB
@Lanhild That's interesting! Of course, to run our own models on premise GPU power is required, and we've started to see AI oriented hardware servers offers lately indeed.
And, for the sake of transparency I must say that connecting with OpenAi with API key works pretty well afaics. With the same machine and config, it's as fast as being on ChatGPT.
-

Where did you get those handy figures from @Lanhild ?
")
-
Simply hover the icon
@Lanhild Heh, thanks!
-
64GB RAM, 12 core xeon
Hello, how are you doing? 8 seconds: mistral-openorca 7b.
Hello there! I'm doing well, thanks for asking. How about yourself?Dolphin-Mixtral 47b 23 seconds:
Hello there! I am functioning perfectly and ready to assist with any questions or tasks you may have. Please let me know how I can help you today. -
One thing I would like to have as an option is a bell sound when the generation has completed. It helps me be productive elsewhere instead of waiting.
Oh, I would suggest overriding the initial memory allocation and ramping it up to as much RAM as you can spare.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login