grab-site
-
https://github.com/ArchiveTeam/grab-site
grab-site
grab-site is an easy preconfigured web crawler designed for backing up websites. Give grab-site a URL and it will recursively crawl the site and write WARC files. Internally, grab-site uses a fork of wpull for crawling.
grab-site gives you
-
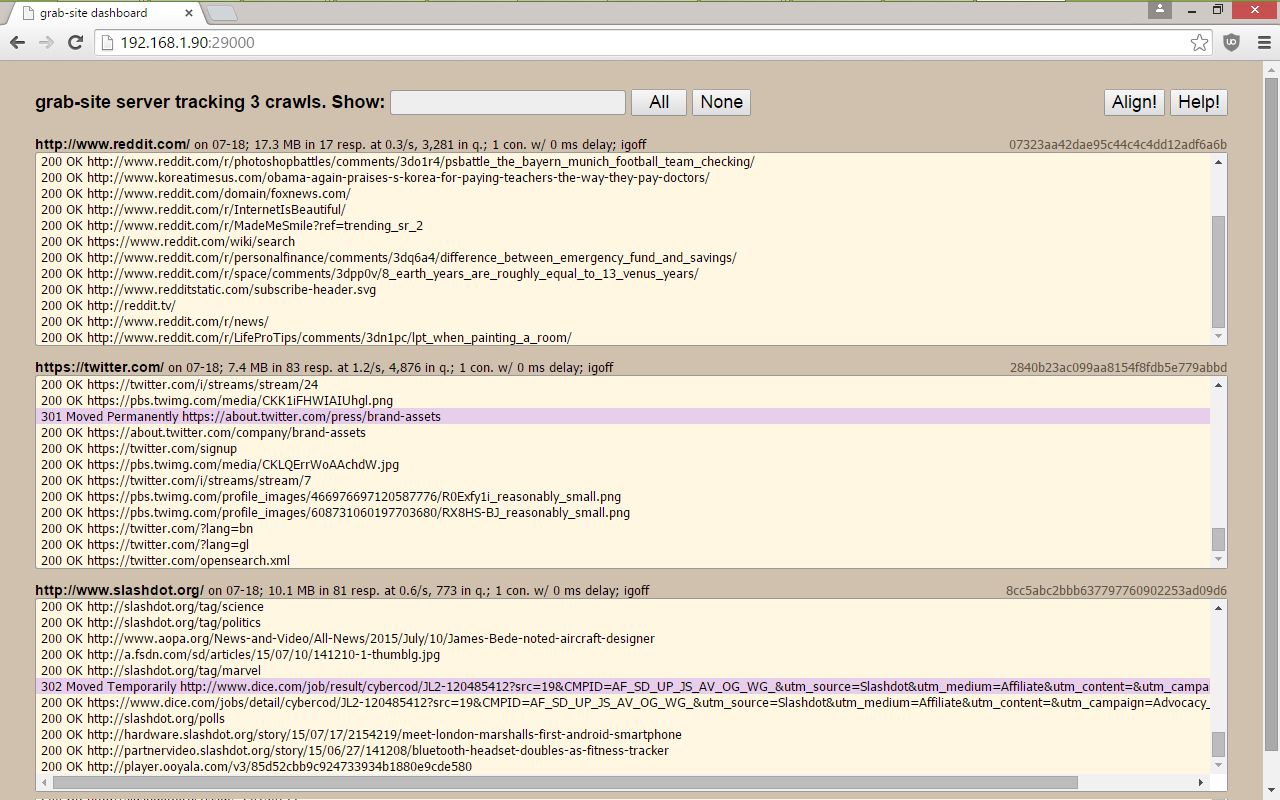
a dashboard with all of your crawls, showing which URLs are being grabbed, how many URLs are left in the queue, and more.
-
the ability to add ignore patterns when the crawl is already running. This allows you to skip the crawling of junk URLs that would otherwise prevent your crawl from ever finishing. See below.
-
an extensively tested default ignore set (global) as well as additional (optional) ignore sets for forums, reddit, etc.
-
duplicate page detection: links are not followed on pages whose content duplicates an already-seen page.
The URL queue is kept on disk instead of in memory. If you're really lucky, grab-site will manage to crawl a site with ~10M pages.
-
-
https://github.com/ArchiveTeam/grab-site
grab-site
grab-site is an easy preconfigured web crawler designed for backing up websites. Give grab-site a URL and it will recursively crawl the site and write WARC files. Internally, grab-site uses a fork of wpull for crawling.
grab-site gives you
-
a dashboard with all of your crawls, showing which URLs are being grabbed, how many URLs are left in the queue, and more.
-
the ability to add ignore patterns when the crawl is already running. This allows you to skip the crawling of junk URLs that would otherwise prevent your crawl from ever finishing. See below.
-
an extensively tested default ignore set (global) as well as additional (optional) ignore sets for forums, reddit, etc.
-
duplicate page detection: links are not followed on pages whose content duplicates an already-seen page.
The URL queue is kept on disk instead of in memory. If you're really lucky, grab-site will manage to crawl a site with ~10M pages.
-
-
Useful utility.
This free tool https://www.httrack.com/ does this very well too.
-
https://github.com/ArchiveTeam/grab-site
grab-site
grab-site is an easy preconfigured web crawler designed for backing up websites. Give grab-site a URL and it will recursively crawl the site and write WARC files. Internally, grab-site uses a fork of wpull for crawling.
grab-site gives you
-
a dashboard with all of your crawls, showing which URLs are being grabbed, how many URLs are left in the queue, and more.
-
the ability to add ignore patterns when the crawl is already running. This allows you to skip the crawling of junk URLs that would otherwise prevent your crawl from ever finishing. See below.
-
an extensively tested default ignore set (global) as well as additional (optional) ignore sets for forums, reddit, etc.
-
duplicate page detection: links are not followed on pages whose content duplicates an already-seen page.
The URL queue is kept on disk instead of in memory. If you're really lucky, grab-site will manage to crawl a site with ~10M pages.
@robi grab-site is a great suggestion and I hope Cloudron supports it. @jdaviescoates makes a good recommendation too.
After the website is grabbed, the next phase is reading and searching it offline. I don't know if you have had much joy trying that with grab-site.
If grab-site can be supported, it is not very far from being able to support YaCy too, which also visits websites and crawls the pages. There is a request for YaCy support on Cloudron here:
https://forum.cloudron.io/topic/2715/yacy-decentralized-web-search?_=1673430654350
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login