Hi again,
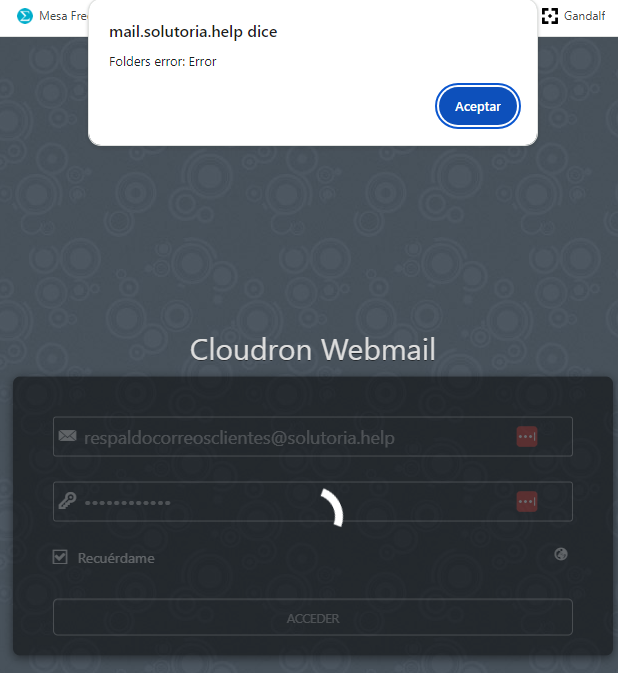
Unfortunately, our FreeScout helpdesk has stopped receiving tickets once more.
When I first ran the cache clear command:
sudo -E -u www-data php artisan freescout:clear-cache
it worked correctly for about 1–2 hours — tickets started coming in again during that period. However, after that time window, new incoming tickets stopped being created again.
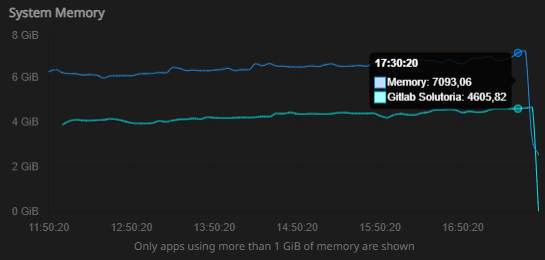
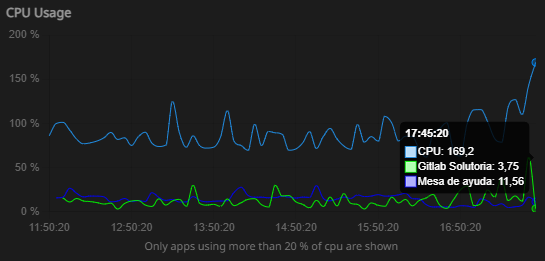
To temporarily restore service, I had to restart the entire Cloudron server, and after that, tickets began arriving again. Even so, the behavior is still intermittent and not stable.
I also noticed a Cloudron notification that might be relevant:
Server is running out of disk space
One or more file systems are running low on space. Please increase the disk size at the earliest.
/dev/nvme0n1p1 (ext4) mounted at / is at 91% capacity.
Used: 350.66GB
Available: 37.02GB
Size: 387.69GB
I’m not sure if this disk space issue could be causing FreeScout to stop processing incoming emails/tickets, but I wanted to mention it in case it’s related to the 419 errors or to the mail processing queue.
Do you think low disk space on the server could be affecting FreeScout’s ability to handle incoming mail, or is there anything else I should check (logs, queues, cron, etc.) on the Freescout/Cloudron side?
Thanks again for your support — I’ll share any new findings here in the same thread.