I thought I would just restart the server in case that fixes things after the weekend. The dashboard came up and I was able to start troubleshooting the unresponsive apps. I guess this is one of those things that cloudron fixes itself with those health checks. Thanks
Z
ZeZaung
@ZeZaung
Posts
-
After fixing an expired cert, dashboard and apps are unreachable. -
After fixing an expired cert, dashboard and apps are unreachable.I tried the unbound troubleshooting and it's still unreachable, the domain is secure until 2029
2023-10-09T14:29:20.174Z box:apphealthmonitor app health: 22 running / 26 stopped / 1 unresponsiveThe logs say everything is fine, docker and nginx are running, but none of the apps are reachable. I didn't change anything on the Vultr VPS side
-
After fixing an expired cert, dashboard and apps are unreachable.I followed the troubleshooting steps and noticed nginx wasn't starting due to a bad cert on a domain that expired years ago.
I deleted the configs and restarted nginx, then reran
/home/yellowtent/box/setup/start.sh2023-10-07T15:03:32 ==> start: Cloudron Start media:x:500: 2023-10-07T15:03:32 ==> start: Configuring docker Synchronizing state of apparmor.service with SysV service script with /lib/systemd/systemd-sysv-install. Executing: /lib/systemd/systemd-sysv-install enable apparmor 2023-10-07T15:03:36 ==> start: Ensuring directories 2023-10-07T15:03:36 ==> start: Configuring journald 2023-10-07T15:03:38 ==> start: Setting up unbound 2023-10-07T15:03:38 ==> start: Adding systemd services Synchronizing state of unbound.service with SysV service script with /lib/systemd/systemd-sysv-install. Executing: /lib/systemd/systemd-sysv-install enable unbound Synchronizing state of cron.service with SysV service script with /lib/systemd/systemd-sysv-install. Executing: /lib/systemd/systemd-sysv-install enable cron 2023-10-07T15:03:52 ==> start: Configuring sudoers 2023-10-07T15:03:52 ==> start: Configuring collectd 2023-10-07T15:03:52 ==> start: Configuring sysctl 2023-10-07T15:03:52 ==> start: Configuring logrotate 2023-10-07T15:03:52 ==> start: Adding motd message for admins 2023-10-07T15:03:52 ==> start: Configuring nginx 2023-10-07T15:03:53 ==> start: Starting mysql mysqladmin: [Warning] Using a password on the command line interface can be insecure. Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety. mysql: [Warning] Using a password on the command line interface can be insecure. 2023-10-07T15:03:53 ==> start: Migrating data Ignoring invalid configuration option passed to Connection: driver. This is currently a warning, but in future versions of MySQL2, an error will be thrown if you pass an invalid configuration option to a Connection [INFO] No migrations to run [INFO] Done 2023-10-07T15:03:54 ==> start: Changing ownership 2023-10-07T15:03:54 ==> start: Starting Cloudron 2023-10-07T15:03:56 ==> start: Almost doneDocker is running, nginx is running, unbound is running, but none of my apps or dashboard can be reached.
-
Our server is hacked: foreign addresses in china, finland, france etc@BrutalBirdie Also, which system logs would be most appropriate?
-
Our server is hacked: foreign addresses in china, finland, france etc@BrutalBirdie
How do I tell which version of cloudron we're running? -
Our server is hacked: foreign addresses in china, finland, france etc@BrutalBirdie Would a copy of a file generated at /var/backups suffice?
-
Our server is hacked: foreign addresses in china, finland, france etcthanks, we'll be in toch
-
Our server is hacked: foreign addresses in china, finland, france etcAnswers to your question.
Could you please explain what got hacked?
The VPS itself has been hacked and an unknown process emanating from this IP has been detected by our cloud provider
can be expected for a public server.
I am telling you that connections from all these different hosts is unconnected and not explainable, no/
Our instance provider has let us know that we have abuse traffic emanating from our machine. We've monitored foreign addreses and know, for sure, the instance is compromised.
What exactly was happening? This is all so vague.
See below
Do you have:
- logs
- statements from the provider
See below
Hello, Here is a sample of the traffic that was detected per your request. -- Traffic excerpt below -- Reported-From: root@dascos.info Report-ID: 1676447666@jeeg Category: abuse Report-Type: login-attack Service: 404trap User-Agent: csf v14.17 Date: 2023-02-15T08:54:26+0100 Source:(OUR.IP.WAS.HERE) Source-Type: ipv4 Attachment: text/plain Schema-URL: https://download.configserver.com/abuse_login-attack_0.2.json (OUR.IP.WAS.HERE) 172.16.0.50 nolodapria.it [15/Feb/2023:08:54:17 +0100] GET /?author=161 HTTP/2.0 404 (OUR.IP.WAS.HERE) 172.16.0.50 nolodapria.it [15/Feb/2023:08:54:18 +0100] GET /?author=162 HTTP/2.0 404 (OUR.IP.WAS.HERE) 172.16.0.50 nolodapria.it [15/Feb/2023:08:54:19 +0100] GET /?author=163 HTTP/2.0 404 (OUR.IP.WAS.HERE).16.0.50 nolodapria.it [15/Feb/2023:08:54:20 +0100] GET /?author=164 HTTP/2.0 404 -- Traffic excerpt above -- Please review and resolve the abuse. We will be forced to power down this instance if we do not receive an update within 24 hours.This was one of their warnings. We have done some preliminary investigation via netstat and rootkit searches and can provide logs to you. Who do we email?
Can you help us differentiate the traffic we are seeing to discern what processes are responsible for this and where the security compromise is arising from within the operating system? A lot of our diagnostic tools we can not install without interfering with cloudron.
Did you perhaps run an the adguard app and did not secure it properly, and it got used for a reflection attack?
Sorry noPlease let us know who to send this info to. We will capture logs over hte past 20 mins or so in a few files.
-
Our server is hacked: foreign addresses in china, finland, france etcHello there
Evidently, we got hacked.
Our instance provider has let us know that we have abuse traffic emanating from our machine. We've monitored foreign addreses and know, for sure, the instance is compromised.
Question for the cloudron's so-called turnkey security team: What can we do to protect ourselves? This is especially important to get an answer from you since we're incapable of installing modest network or Os-level security provisions within the instance without interfering with cloudron itself.
We understand Cloudron literature suggests the following
Security is a core feature of Cloudron and we continue to push out updates to tighten the Cloudron firewall's security policy. Our goal is that Cloudron users should be able to rely on Cloudron being secure out of the box without having to do manual configuration.Can the turnkey security team give us some advice on software we can install (that still works with cloudron) to deal with this? A lot of our preferred security & hardening measures are not doable without interfering with cloudron itself
Before our team goes through the onerous process of creating a new instance and backing up these apps individually or resetting them all together, we want to know what security measures can be implemented on the second time around, so we aren't wasting time after the fact.
A simple netstat and awk monitoring program shows unique hits from foreign addresses in countries such as China, finland, and France, all on strange ports certainly not associated with our deployed applications.
Considering the restrictive nature of 3rd party installations of software on a OS level for the master control plane instance we are hoping cloudron's turnkey security team can get back to us promptly. the current state of things suggests we can't rely on cloudron as a platform for production grade loads or traffic.
-
Deleting invalid/expired apps Manually?Thank you that worked!
-
Deleting invalid/expired apps Manually?I have some stopped apps from expired domains that I cannot uninstall from Cloudron.
Error : External Error - Domain name not found Error : External Error - API Key is invalid or API access has not been enabled External Error: Sorry, you will not be able to edit the domain (domain.xyz) as the domain is currently locked.Domain Locked reason: Suspended by the Registry, please contact https://gen.xyz/account/submitticket.php?action=unsuspendI removed the associated email addresses and put the redis tables into "recovery" mode to try free up more drive space/RAM but still feel like I'm stuck. The associated docker containers are not running after I ssh into the server. I've looked through the docs but see no mention of manual removal.
Thank you for reading
-
OpenVPN DNS leaks?@girish I am having this issue also using openwrt and am unable to discern how to solve this.
The lines of code added to the ovpn file generated via cloudron goes like this
script-security 2 up /etc/openvpn/update-resolv-conf down /etc/openvpn/update-resolv-confThis seems to work to fix the dns leak issue on mac os or microsoft clients. However, when I try the same config with openwrt (a router), it doesn't work.
I have opened a support ticket on OpenWrt about this. Strange, since other VPN services which provide ovpn files do not have this dns leak and did not require the above block of code to be added beneath 'script-security-2'
-
Domain registration woesHi there
I am trying to register a domain name I acquired several hours ago. I have recently registered another domain name that uses the same user/key combo as before.
Do you guys know what this might be indicating?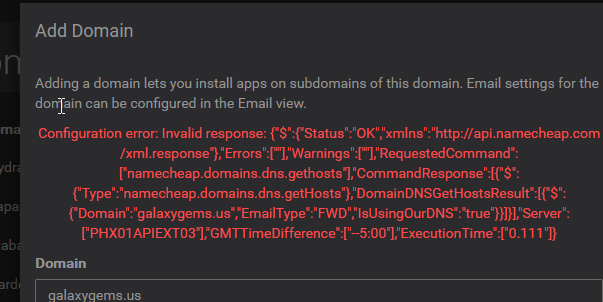
-
New Problem: Recovery after disk full, all services runing, still unreachable dashboard re: ....the DNS record of...is set to this server's IP but cloudron has no apps configured for this domainThat sounds like exactly what happened, what kind of monitoring solution would you recommend for cloudron (interested in space and RAM monitoring)? We've been hesitant about using any sort of
apt getfor fear of interfering with cloudron operation -
New Problem: Recovery after disk full, all services runing, still unreachable dashboard re: ....the DNS record of...is set to this server's IP but cloudron has no apps configured for this domainHi. It seems the matter has solved itself. We did run start.sh and still weren't able to access dashboard (everythign was down except all services appeared active & running) Waited approx 18 hours and now it's all back up again. I guess the certs got replaced eventually, not sure.
Here's some snippets of the
start.shaction:2022-09-26T09:00:00.295Z box:apps Error initiating autoupdate of ce6e40e0-b6d5-48c6-beb1-5ba775d0137f. Not allowed in error state 2022-09-26T09:00:00.305Z box:apps Error initiating autoupdate of d028e2b5-bcd1-40f8-9b12-1139588eb328. Not allowed in error state 2022-09-26T09:00:10.085Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T10:30:00.534Z box:disks checkDiskSpace: disk space checked. out of space: no 2022-09-26T12:00:00.015Z box:janitor Cleaning up expired tokens 2022-09-26T12:00:00.019Z box:janitor Cleaning up docker volumes 2022-09-26T12:00:00.022Z box:janitor Cleaned up 0 expired tokens 2022-09-26T12:00:00.030Z box:tasks startTask - starting task 5607 with options {}. logs at /home/yellowtent/platformdata/logs/tasks/5607.log 2022-09-26T12:00:00.031Z box:shell startTask spawn: /usr/bin/sudo -S -E /home/yellowtent/box/src/scripts/starttask.sh 5607 /home/yellowtent/platformdata/logs/tasks/5607.log 0 400 2022-09-26T12:00:00.151Z box:janitor cleanupTmpVolume ["/26b359fd-4fc2-4e40-99f4-d93f78915e8f"] 2022-09-26T12:00:00.207Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:00:00.312Z box:shell startTask (stdout): Running as unit: box-task-5607.service 2022-09-26T12:00:01.310Z box:shell startTask (stdout): 10633 (process group ID) old priority 0, new priority 0 2022-09-26T12:00:01.660Z box:janitor cleanupTmpVolume ["/8533d5c4-a3c1-40e5-9546-bf3bc9295001"] 2022-09-26T12:00:01.754Z box:janitor cleanupTmpVolume ["/43633466-4a91-4e35-a10e-f80fcde30ff1"] 2022-09-26T12:00:01.852Z box:janitor cleanupTmpVolume ["/c68e6d0e-dba3-4bef-8542-c2fd13a46072"] 2022-09-26T12:00:01.969Z box:janitor cleanupTmpVolume ["/5195f5c9-4e62-4f3c-a74b-1908ef057d99"] 2022-09-26T12:00:02.072Z box:janitor cleanupTmpVolume ["/b8932afc-5c61-4b32-ac43-c3433d5c8d9e"] 2022-09-26T12:00:02.074Z box:janitor BoxError: Failed to exec container: (HTTP code 409) container stopped/paused - Container dd659c1b56c55000b45e4598178af05a7f5b8d4d1dbb0d10171922d30cf113ff is restarting, wait until the container is running at cleanupTmpVolume (/home/yellowtent/box/src/janitor.js:34:22) at runMicrotasks (<anonymous>) at processTicksAndRejections (node:internal/process/task_queues:96:5) 2022-09-26T12:00:02.075Z box:janitor cleanupTmpVolume ["/6614e9bf-7cde-4a4d-81cb-83f24e19d5b7"] 2022-09-26T12:00:02.182Z box:janitor cleanupTmpVolume ["/dc855c65-ad9e-4c58-ace7-37735a857a0d"] 2022-09-26T12:00:02.275Z box:janitor cleanupTmpVolume ["/redis-dc855c65-ad9e-4c58-ace7-37735a857a0d"] 2022-09-26T12:00:02.356Z box:janitor cleanupTmpVolume ["/9e486f53-493d-4c33-861e-5ea3bcf0120e"] 2022-09-26T12:00:02.435Z box:janitor cleanupTmpVolume ["/d49ecfd4-5798-49d7-a92f-1a60a3eedff7"] 2022-09-26T12:00:02.523Z box:janitor cleanupTmpVolume ["/71a74797-240c-4224-8431-dcf0ca8b31d8"] 2022-09-26T12:00:02.598Z box:janitor cleanupTmpVolume ["/52226e9a-5e77-4e8d-9c8f-d8f3aca985dc"] 2022-09-26T12:00:02.687Z box:janitor cleanupTmpVolume ["/5faaa596-1239-4ea8-9e2f-78a310227e12"] 2022-09-26T12:00:02.763Z box:janitor cleanupTmpVolume ["/redis-52226e9a-5e77-4e8d-9c8f-d8f3aca985dc"] 2022-09-26T12:00:02.851Z box:janitor cleanupTmpVolume ["/56fcfa77-bab6-490e-81ba-59ad7a446f4d"] 2022-09-26T12:00:02.927Z box:janitor cleanupTmpVolume ["/eaab0051-f08d-4443-b7cc-e2a8dd0f6df0"] 2022-09-26T12:00:03.004Z box:janitor cleanupTmpVolume ["/3da8624a-96aa-4a04-bb3f-dd1602ea3133"] 2022-09-26T12:00:03.083Z box:janitor cleanupTmpVolume ["/7fef7038-0f05-44cc-85ae-5ab5bfe2cedd"] 2022-09-26T12:00:03.168Z box:janitor cleanupTmpVolume ["/1f4a4797-f865-41cd-b33c-253c35b5014a"] 2022-09-26T12:00:03.248Z box:janitor cleanupTmpVolume ["/798c7dab-463b-4f0b-a31b-aa4138ff7ba8"] 2022-09-26T12:00:03.332Z box:janitor cleanupTmpVolume ["/redis-71a74797-240c-4224-8431-dcf0ca8b31d8"] 2022-09-26T12:00:03.424Z box:janitor cleanupTmpVolume ["/mail"] 2022-09-26T12:00:03.504Z box:janitor cleanupTmpVolume ["/redis-5faaa596-1239-4ea8-9e2f-78a310227e12"] 2022-09-26T12:00:03.584Z box:janitor cleanupTmpVolume ["/0d41c0b8-79f4-4f4a-9918-3210ae6a5f6e"] 2022-09-26T12:00:03.660Z box:janitor cleanupTmpVolume ["/c72baee9-ec9b-4bbb-8a9b-a4e72e416817"] 2022-09-26T12:00:03.743Z box:janitor cleanupTmpVolume ["/11fcd0ab-ff4c-4dac-a58f-4c564fa59036"] 2022-09-26T12:00:03.828Z box:janitor cleanupTmpVolume ["/175049fb-c70d-4cff-b724-54cbf9561762"] 2022-09-26T12:00:03.912Z box:janitor cleanupTmpVolume ["/c960e9ec-b551-424a-a1a2-8bd04a1f311f"] 2022-09-26T12:00:03.989Z box:janitor cleanupTmpVolume ["/920daad0-7f7c-4610-acc3-348fdfe5ef03"] 2022-09-26T12:00:03.991Z box:janitor BoxError: Failed to exec container: (HTTP code 409) container stopped/paused - Container 61200336d6ea05fbfe7ff3060712aa28cdb3b41af622aa36919d54cd4f582709 is restarting, wait until the container is running at cleanupTmpVolume (/home/yellowtent/box/src/janitor.js:34:22) at runMicrotasks (<anonymous>) at processTicksAndRejections (node:internal/process/task_queues:96:5) 2022-09-26T12:00:03.991Z box:janitor cleanupTmpVolume ["/6e7ad12f-d27b-4978-877f-13867e41340e"] 2022-09-26T12:00:03.992Z box:janitor BoxError: Failed to exec container: (HTTP code 409) container stopped/paused - Container 2b9c86c1ec8f0a098294b1b3a0b381d7470835376ea7ec640cafb0eea03dd59a is restarting, wait until the container is running at cleanupTmpVolume (/home/yellowtent/box/src/janitor.js:34:22) at runMicrotasks (<anonymous>) at processTicksAndRejections (node:internal/process/task_queues:96:5) 2022-09-26T12:00:03.992Z box:janitor cleanupTmpVolume ["/ce717ac0-91cf-467d-b457-1dc110003537"] 2022-09-26T12:00:04.088Z box:janitor cleanupTmpVolume ["/sftp"] 2022-09-26T12:00:04.169Z box:janitor cleanupTmpVolume ["/redis-d49ecfd4-5798-49d7-a92f-1a60a3eedff7"] 2022-09-26T12:00:04.262Z box:janitor cleanupTmpVolume ["/redis-d028e2b5-bcd1-40f8-9b12-1139588eb328"] 2022-09-26T12:00:04.351Z box:janitor cleanupTmpVolume ["/redis-c107e741-82e7-4670-b970-1ffded0e4557"] 2022-09-26T12:00:04.434Z box:janitor cleanupTmpVolume ["/redis-aedf9b10-4fa8-4c8f-80d8-28faacd1cd86"] 2022-09-26T12:00:04.520Z box:janitor cleanupTmpVolume ["/redis-9e486f53-493d-4c33-861e-5ea3bcf0120e"] 2022-09-26T12:00:04.602Z box:janitor cleanupTmpVolume ["/redis-70560788-b7f7-42b5-b722-ad557d1821e4"] 2022-09-26T12:00:04.683Z box:janitor cleanupTmpVolume ["/redis-4f4daf11-09e2-4396-bb6b-84748c017e89"] 2022-09-26T12:00:04.767Z box:janitor cleanupTmpVolume ["/redis-35f25c44-7707-43b8-ab2a-611327d5ca20"] 2022-09-26T12:00:04.850Z box:janitor cleanupTmpVolume ["/redis-2df3d2af-3983-4403-aa08-a02f68e39e8c"] 2022-09-26T12:00:04.926Z box:janitor cleanupTmpVolume ["/redis-20a23213-ed2e-45d0-a83d-e6856f128c20"] 2022-09-26T12:00:05.005Z box:janitor cleanupTmpVolume ["/redis-1f4a4797-f865-41cd-b33c-253c35b5014a"] 2022-09-26T12:00:05.088Z box:janitor cleanupTmpVolume ["/redis-1319b8cd-e506-412b-a317-38c94b88a4e7"] 2022-09-26T12:00:05.174Z box:janitor cleanupTmpVolume ["/redis-06579a1c-cd5f-48aa-852c-db2a147eca16"] 2022-09-26T12:00:05.263Z box:janitor cleanupTmpVolume ["/mongodb"] 2022-09-26T12:00:05.352Z box:janitor cleanupTmpVolume ["/postgresql"] 2022-09-26T12:00:05.426Z box:janitor cleanupTmpVolume ["/0b3d023e-be95-435f-98d9-956726387db3"] 2022-09-26T12:00:05.502Z box:janitor cleanupTmpVolume ["/d028e2b5-bcd1-40f8-9b12-1139588eb328"] 2022-09-26T12:00:05.587Z box:janitor cleanupTmpVolume ["/c107e741-82e7-4670-b970-1ffded0e4557"] 2022-09-26T12:00:05.662Z box:janitor cleanupTmpVolume ["/4f4daf11-09e2-4396-bb6b-84748c017e89"] 2022-09-26T12:00:05.753Z box:janitor cleanupTmpVolume ["/2df3d2af-3983-4403-aa08-a02f68e39e8c"] 2022-09-26T12:00:05.847Z box:janitor cleanupTmpVolume ["/20a23213-ed2e-45d0-a83d-e6856f128c20"] 2022-09-26T12:00:05.923Z box:janitor cleanupTmpVolume ["/06579a1c-cd5f-48aa-852c-db2a147eca16"] 2022-09-26T12:00:06.000Z box:janitor cleanupTmpVolume ["/graphite"] 2022-09-26T12:00:06.084Z box:janitor cleanupTmpVolume ["/mysql"] 2022-09-26T12:00:06.167Z box:janitor cleanupTmpVolume ["/turn"] 2022-09-26T12:00:06.257Z box:janitor cleanupTmpVolume ["/gracious_jackson"] 2022-09-26T12:00:10.104Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:00:20.111Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:00:30.092Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:00:40.086Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:00:50.086Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:01:00.127Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:01:00.548Z box:shell startTask (stdout): Finished with result: success Main processes terminated with: code=exited/status=0 Service runtime: 1min 240ms 2022-09-26T12:01:00.548Z box:shell startTask (stdout): Service box-task-5607 finished with exit code 0 2022-09-26T12:01:00.552Z box:tasks startTask: 5607 completed with code 0 and signal 0 2022-09-26T12:01:00.553Z box:tasks startTask: 5607 done. error: null 2022-09-26T12:01:10.091Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:01:20.080Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:01:30.185Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:01:40.142Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:01:50.434Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:02:00.097Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:02:10.108Z box:apphealthmonitor app health: 21 alive / 25 dead. 2022-09-26T12:02:13.538Z box:locker Acquired : apptask 2022-09-26T12:02:13.539Z box:scheduler suspendJobs: 47c707f0-e8c2-41f6-b66f-4c62c43ef165 2022-09-26T12:02:13.539Z box:tasks startTask - starting task 5608 with options {"timeout":72000000,"nice":15,"memoryLimit":400,"logFile":"/home/yellowtent/platformdata/logs/47c707f0-e8c2-41f6-b66f-4c62c43ef165/apptask.log"}. logs at /home/yellowtent/platformdata/logs/47c707f0-e8c2-41f6-b66f-4c62c43ef165/apptask.log 2022-09-26T12:02:13.539Z box:shell startTask spawn: /usr/bin/sudo -S -E /home/yellowtent/box/src/scripts/starttask.sh 5608 /home/yellowtent/platformdata/logs/47c707f0-e8c2-41f6-b66f-4c62c43ef165/apptask.log 15 400 2022-09-26T12:02:13.697Z box:shell startTask (stdout): Running as unit: box-task-5608.service 2022-09-26T12:02:14.682Z box:shell startTask (stdout): 13398 (process group ID) old priority 0, new priority 15 2022-09-26T12:02:17.299Z box:shell startTask (stdout): Finished with result: exit-code Main processes terminated with: code=exited/status=50 Service runtime: 3.618s 2022-09-26T12:02:17.300Z box:shell startTask code: 50, signal: null 2022-09-26T12:02:17.301Z box:tasks startTask: 5608 completed with code 50 and signal null 2022-09-26T12:02:17.303Z box:apps scheduleTask: task 5608 of 47c707f0-e8c2-41f6-b66f-4c62c43ef165 completed 2022-09-26T12:02:17.303Z box:locker Released : apptask 2022-09-26T12:02:17.304Z box:scheduler resumeJobs: 47c707f0-e8c2-41f6-b66f-4c62c43ef165 2022-09-26T12:02:17.304Z box:tasks startTask: 5608 done. error: [object Object] 2022-09-26T12:02:20.112Z box:apphealthmonitor app health: 21 alive / 25 dead. -
New Problem: Recovery after disk full, all services runing, still unreachable dashboard re: ....the DNS record of...is set to this server's IP but cloudron has no apps configured for this domainThis is a follow-up thread based on our own resolution of issues with nginx, certs, and configs, which we removed based on a recommendation found with a very similar error encountered by other cloudron users. That thread can be found here: https://forum.cloudron.io/topic/7722/nginx-problems-running-after-diskfull-recovery-walkthrough/3
But now we have a new error: unreachable dashboard, this is what we get:
You are seeing this page because the DNS record of my.redacted.domain is set to this server's IP but Cloudron has no app configured for this domain.We dont' know where to go now. All our services are in a running state, but we fear something is misconfigured and do not know how to debug any further without potentially causing even more issues.
-
Nginx problems running after diskfull recovery walkthroughSo turns out we've resolved this portion.
Main issue is there were way too many confs pointing to the main problematic certficate. Everything in /home/yellowtent/platformdata/nginx/applications basically needed to be moved (/removed) in order to get nginx to restart again once more
-
Nginx problems running after diskfull recovery walkthroughby the way, when I run restart on nginx I get the very same issue experienced by the other user i linked to in that thread
Here is the newest log (note the "BIO")
Sep 25 14:27:28 cloudron0 systemd[1]: Starting nginx - high performance web server... -- Subject: Unit nginx.service has begun start-up -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit nginx.service has begun starting up. Sep 25 14:27:28 cloudron0 nginx[20372]: nginx: [emerg] cannot load certificate "/home/yellowtent/platformdata/nginx/cert/_.covidian.life.cert": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/home/yellowtent/platformdata/nginx/cert/_.covidian.life.cert','r') error:2006D080:BIO routines:BIO_new_file:no such file) Sep 25 14:27:28 cloudron0 systemd[1]: nginx.service: Control process exited, code=exited status=1 Sep 25 14:27:28 cloudron0 systemd[1]: nginx.service: Failed with result 'exit-code'. Sep 25 14:27:28 cloudron0 systemd[1]: Failed to start nginx - high performance web server. -- Subject: Unit nginx.service has failed -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit nginx.service has failed. -- -- The result is RESULT. Sep 25 14:27:28 cloudron0 systemd[1]: Started Cloudron Admin. -- Subject: Unit box.service has finished start-up -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished starting up. -- -- The start-up result is RESULT. Sep 25 14:27:28 cloudron0 systemd[1]: nginx.service: Service hold-off time over, scheduling restart. Sep 25 14:27:28 cloudron0 systemd[1]: nginx.service: Scheduled restart job, restart counter is at 5. -- Subject: Automatic restarting of a unit has been scheduled -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Automatic restarting of the unit nginx.service has been scheduled, as the result for -- the configured Restart= setting for the unit. Sep 25 14:27:28 cloudron0 systemd[1]: Stopped nginx - high performance web server. -- Subject: Unit nginx.service has finished shutting down -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit nginx.service has finished shutting down. Sep 25 14:27:28 cloudron0 systemd[1]: nginx.service: Start request repeated too quickly. Sep 25 14:27:28 cloudron0 systemd[1]: nginx.service: Failed with result 'exit-code'. Sep 25 14:27:28 cloudron0 systemd[1]: Failed to start nginx - high performance web server. -- Subject: Unit nginx.service has failed -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit nginx.service has failed. -- -- The result is RESULT. Sep 25 14:27:29 cloudron0 systemd[1]: box.service: Main process exited, code=exited, status=1/FAILURE Sep 25 14:27:29 cloudron0 systemd[1]: box.service: Failed with result 'exit-code'. Sep 25 14:27:29 cloudron0 systemd[1]: box.service: Service hold-off time over, scheduling restart. Sep 25 14:27:29 cloudron0 systemd[1]: box.service: Scheduled restart job, restart counter is at 159431. -- Subject: Automatic restarting of a unit has been scheduled -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Automatic restarting of the unit box.service has been scheduled, as the result for -- the configured Restart= setting for the unit. Sep 25 14:27:29 cloudron0 systemd[1]: Stopped Cloudron Admin. -- Subject: Unit box.service has finished shutting down -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished shutting down. Sep 25 14:27:29 cloudron0 systemd[1]: Started Cloudron Admin. -- Subject: Unit box.service has finished start-up -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished starting up. -- -- The start-up result is RESULT. -
Nginx problems running after diskfull recovery walkthroughHello there
I am a big fan of cloudron. One of the other users of our cloudron instance filled up the drive with too much 4k drone footage. As expected this caused some issues for cloudron.
However, when attempting to follow the instructions laid out for recovery in this situation, we've struggled to make sense of how to get nginx restarted.
After poking around on this forum I found this page which seems to have mirrored what we were up against: https://forum.cloudron.io/topic/7219/cannot-load-certificate-key-_-sub-domain-org-key-failed-no-such-file-or-directory
^ We did however have a key but it was blank and nginx was complaining that the data found within it was wrong.
So, we ran mv on the associated cert & keyfiles & conf, and attempted a restart, however that doesn't work and the trail has run dry with these cryptic nginx journal logs which do not suggest what we should do next to debug.
-- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished shutting down. Sep 25 14:24:09 cloudron0 systemd[1]: Started Cloudron Admin. -- Subject: Unit box.service has finished start-up -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished starting up. -- -- The start-up result is RESULT. Sep 25 14:24:10 cloudron0 systemd[1]: box.service: Main process exited, code=exited, status=1/FAILURE Sep 25 14:24:10 cloudron0 systemd[1]: box.service: Failed with result 'exit-code'. Sep 25 14:24:10 cloudron0 systemd[1]: box.service: Service hold-off time over, scheduling restart. Sep 25 14:24:10 cloudron0 systemd[1]: box.service: Scheduled restart job, restart counter is at 159233. -- Subject: Automatic restarting of a unit has been scheduled -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Automatic restarting of the unit box.service has been scheduled, as the result for -- the configured Restart= setting for the unit. Sep 25 14:24:10 cloudron0 systemd[1]: Stopped Cloudron Admin. -- Subject: Unit box.service has finished shutting down -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished shutting down. Sep 25 14:24:10 cloudron0 systemd[1]: Started Cloudron Admin. -- Subject: Unit box.service has finished start-up -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished starting up. -- -- The start-up result is RESULT. Sep 25 14:24:11 cloudron0 systemd[1]: box.service: Main process exited, code=exited, status=1/FAILURE Sep 25 14:24:11 cloudron0 systemd[1]: box.service: Failed with result 'exit-code'. Sep 25 14:24:11 cloudron0 systemd[1]: box.service: Service hold-off time over, scheduling restart. Sep 25 14:24:11 cloudron0 systemd[1]: box.service: Scheduled restart job, restart counter is at 159234. -- Subject: Automatic restarting of a unit has been scheduled -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Automatic restarting of the unit box.service has been scheduled, as the result for -- the configured Restart= setting for the unit. Sep 25 14:24:11 cloudron0 systemd[1]: Stopped Cloudron Admin. -- Subject: Unit box.service has finished shutting down -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished shutting down. Sep 25 14:24:11 cloudron0 systemd[1]: Started Cloudron Admin. -- Subject: Unit box.service has finished start-up -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished starting up. -- -- The start-up result is RESULT. Sep 25 14:24:12 cloudron0 systemd[1]: box.service: Main process exited, code=exited, status=1/FAILURE Sep 25 14:24:12 cloudron0 systemd[1]: box.service: Failed with result 'exit-code'. Sep 25 14:24:12 cloudron0 systemd[1]: box.service: Service hold-off time over, scheduling restart. Sep 25 14:24:12 cloudron0 systemd[1]: box.service: Scheduled restart job, restart counter is at 159235. -- Subject: Automatic restarting of a unit has been scheduled -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Automatic restarting of the unit box.service has been scheduled, as the result for -- the configured Restart= setting for the unit. Sep 25 14:24:12 cloudron0 systemd[1]: Stopped Cloudron Admin. -- Subject: Unit box.service has finished shutting down -- Defined-By: systemd -- Support: http://www.ubuntu.com/support -- -- Unit box.service has finished shutting down. Sep 25 14:24:12 cloudron0 systemd[1]: Started Cloudron Admin. -- Subject: Unit box.service has finished start-up``` -
Domain registry not working@girish It's www- not working on a particular application. I will write to support. namecheap overall does work, we're talking about a single domain