Backup feedback over sshfs
-
Some feedback on trying to use sshfs as a backup mechanism. Setup was: cloudron node connected to a remote server hosted in a different country using sshfs.
- Using the rsync method, this was unusably slow, likely due to smaller file sizes (~10 minutes just to process a G or two of data, despite having a decent internet connection on both ends).
- Using tarballs was a bit of a better experience, the backup did eventually complete, but this is not really a practical possibility given the size of data I was trying to back up at present (as I understand it, basically, each day would involve a full upload of those tarballs).
Not sure what can really be done about this from the Cloudron side without some pretty serious surgery, but thought that it was worth mentioning.
-
For the last release, I did some basic performance tests to get the backup speed to be at par with something like rclone. I did not test sshfs specifically but I am curious how long it takes to copy this amount of data using normal tool in your setup? For example, how long does a cp of so small small files take? (Just rough number is fine). Granted, Cloudron being node.js based is not going to be as fast as native tools, but given that both of them are just copying files sequentially, i don't expect that big a difference. (Like maybe Cloudron takes a minute or two more).
-
In the other thread, I saw that you were using encrypted backups. Is this the case when you tested this? Encryption requires a decent CPU as well, so a simple cp is not a fair comparison. I wonder if you can enable encryption on the remote disk somehow and not rely on Cloudron encryption?
-
For the last release, I did some basic performance tests to get the backup speed to be at par with something like rclone. I did not test sshfs specifically but I am curious how long it takes to copy this amount of data using normal tool in your setup?
My guess is that the problem is inherent to sshfs, and is not something specific to Cloudron (sshfs not being fast is pretty widely known/recognized). The only real reason I am reporting this is to perhaps suggest noting that it does not scale well in the docs, or something like that, because I don't think this gives a particularly good impression as-is.
sshfs is very sensitive to latency, so any cases where you run it to a remote server on a different network, the slowdown will be very noticable.
Using a tool more suited to this style of operation (like, say, rsync) will give better results, but it will still not scale well for large files (or large datasets, over say a few hundred GB of small files).
In the other thread, I saw that you were using encrypted backups. Is this the case when you tested this? Encryption requires a decent CPU as well, so a simple cp is not a fair comparison. I wonder if you can enable encryption on the remote disk somehow and not rely on Cloudron encryption?
Correct, encryption was enabled, but it wasn't really a factor. CPU was more or less idle while this was going on. Remote disk encryption isn't really an option in this case because I don't have physical control over the remote host, so I want to keep the data hidden
")
-
We have been using sshfs backup for a few months now, I had same experience with rsync, it takes several days in our case to finish, so I tried tgz backup, it's way faster than rsync but what really bothers me is that each time the sshfs mount breaks (no idea why, sometimes it gets dismounted out of nowhere) then when I remount it all the backups are gone, meaning, they are physically on my storage box but not listed on each apps or on the main backup view.
I have to make a full new backup for it to be listed until the next mount drop...
of course If I attempts to clean the backup, since previous backup are not indexed, they don't exist and need to be cleaned up by hand (which is something I would love to avoid)
Is there anything I could do to improve this situation or perhaps force some kind of scan that would index properly previous backups (before the sshfs mount breakage) ?
edit : not using encrypted backup at this stage
-
We have been using sshfs backup for a few months now, I had same experience with rsync, it takes several days in our case to finish, so I tried tgz backup, it's way faster than rsync but what really bothers me is that each time the sshfs mount breaks (no idea why, sometimes it gets dismounted out of nowhere) then when I remount it all the backups are gone, meaning, they are physically on my storage box but not listed on each apps or on the main backup view.
I have to make a full new backup for it to be listed until the next mount drop...
of course If I attempts to clean the backup, since previous backup are not indexed, they don't exist and need to be cleaned up by hand (which is something I would love to avoid)
Is there anything I could do to improve this situation or perhaps force some kind of scan that would index properly previous backups (before the sshfs mount breakage) ?
edit : not using encrypted backup at this stage
@rmdes said in Backup feedback over sshfs:
Is there anything I could do to improve this situation or perhaps force some kind of scan that would index properly previous backups (before the sshfs mount breakage) ?
It's hard to know why this is happening without looking into the server/logs. If you can email me on support@ , when things are a bit broken, I can debug it further.
-
@rmdes said in Backup feedback over sshfs:
Is there anything I could do to improve this situation or perhaps force some kind of scan that would index properly previous backups (before the sshfs mount breakage) ?
It's hard to know why this is happening without looking into the server/logs. If you can email me on support@ , when things are a bit broken, I can debug it further.
@girish OK next time it breaks I'll send an email about it, leaving it as it is so that you can have a look, I already tried to find the reasons but beside "time-out" I couldn't find anything particular

checking everyday and now that I'm waiting for it to un-mount, it does not
haha -
@girish OK next time it breaks I'll send an email about it, leaving it as it is so that you can have a look, I already tried to find the reasons but beside "time-out" I couldn't find anything particular
checking everyday and now that I'm waiting for it to un-mount, it does not
haha@girish here we go :
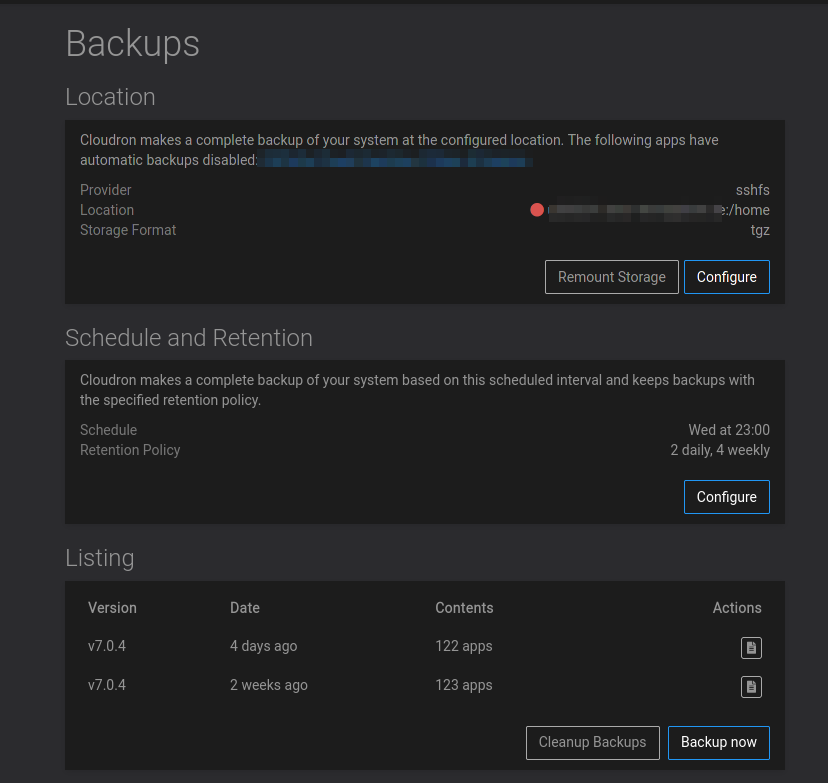
This is after a reboot of the server.
but this time I clicked Remount Storage and instead of "removing" previous backups, everything is mounted and backups are listed as usual..
I think the other times this happened, I was going to Volumes, reconnect the mount (maybe this is what makes previous backups, inside the volume, unlisted after a remount?)
then go to backup and Remount the storage, but this time I just clicked once, in the backup view, remount storage and all is fine.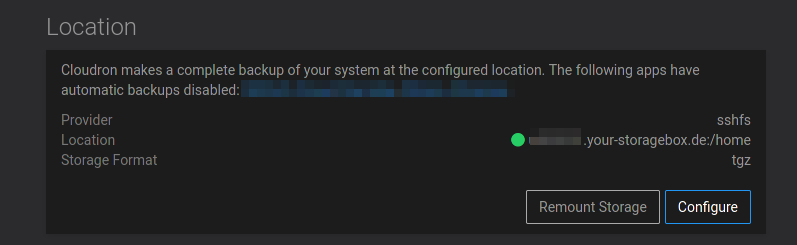
-
@girish here we go :
This is after a reboot of the server.
but this time I clicked Remount Storage and instead of "removing" previous backups, everything is mounted and backups are listed as usual..
I think the other times this happened, I was going to Volumes, reconnect the mount (maybe this is what makes previous backups, inside the volume, unlisted after a remount?)
then go to backup and Remount the storage, but this time I just clicked once, in the backup view, remount storage and all is fine.@rmdes thanks for the details. So this is the same issue with the systemd unit dependencies during boot. The mount units are simply skipped it seems due to this circular dependency. We have to fix this for the next release, just not yet sure how
-
@rmdes thanks for the details. So this is the same issue with the systemd unit dependencies during boot. The mount units are simply skipped it seems due to this circular dependency. We have to fix this for the next release, just not yet sure how
-
@nebulon What if the mount was being made persistent at the OS level so then when cloudron reboot it could check those system mounts and if they match existing volumes, mount them properly ?
@rmdes they are setup with systemd, so they are system-level already. The issue is DNS/unbound dependency for the mounting as well as docker for the volumes. Since there is some circular dependency currently, systemd breaks the circle by disabling the mount points during startup, which is causing the issue that they are not mounted after reboot.
-
@rmdes they are setup with systemd, so they are system-level already. The issue is DNS/unbound dependency for the mounting as well as docker for the volumes. Since there is some circular dependency currently, systemd breaks the circle by disabling the mount points during startup, which is causing the issue that they are not mounted after reboot.
-
Does the xx.your-storagebox.de resolve to a static/fixed single IP?
-
@rmdes thanks for the details. So this is the same issue with the systemd unit dependencies during boot. The mount units are simply skipped it seems due to this circular dependency. We have to fix this for the next release, just not yet sure how
@nebulon @girish Not in a hurry or anything, but the state bug is happening (happens at each reboot basically) I've left it unmounted and will for the weekend if at some point you want to SSH-support and retrieve log traces related to the mounting issue or I can post here if you indicate the commands you want to get more context ?
-
@nebulon @girish Not in a hurry or anything, but the state bug is happening (happens at each reboot basically) I've left it unmounted and will for the weekend if at some point you want to SSH-support and retrieve log traces related to the mounting issue or I can post here if you indicate the commands you want to get more context ?
I have remounted the volume now and something that really is problematic with this type of backup is that, even when you remount the volume and storage backup location (that part works just great with two clicks) it seems previous backup at the mounted location are not listed, it's like a brand new freshly added volume/storage.
Meaning, previous backups can only be restored manually, they can be retrieved anymore from cloudron dashboard, the only way is to follow the manual instruction from the doc to retrieve backup ID etc..
manual remount wouldn't be an issue for my use case If I could get the existing backup listed when the volume/storage is remounted.
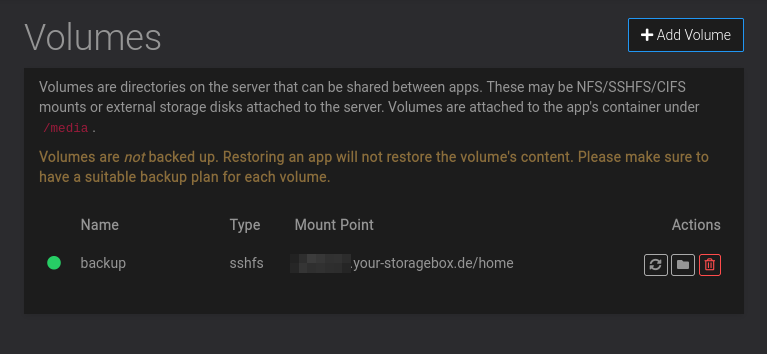
volume view remounted :
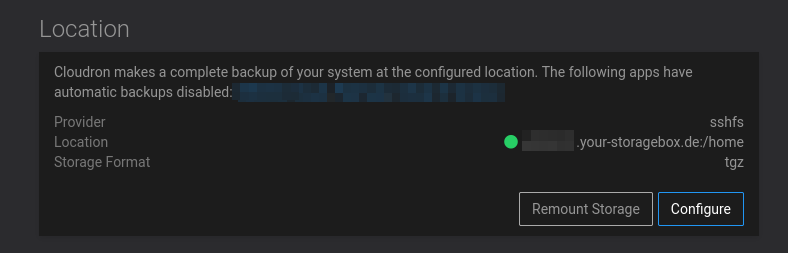
backup view remounted :
the backup listing view after everything is remounted :
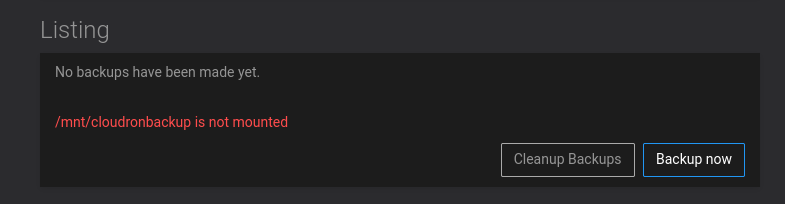
I was wondering if it wouldn't be a good idea to have a button to rescan the backup target for backups that match previously made cloudron backups ?
-
I use a Hetzner storagebox via sshfs as backup provider and also have the issue with the volume being not mounted after reach reboot. Clicking the remount volume button solves it for me though. All previous backups are correctly listed after remounting.
Having to remount the volume manually is somewhat annoying though and I would appreciate a solution which solves the issue with the circular dependency on boot.
-
I have remounted the volume now and something that really is problematic with this type of backup is that, even when you remount the volume and storage backup location (that part works just great with two clicks) it seems previous backup at the mounted location are not listed, it's like a brand new freshly added volume/storage.
Meaning, previous backups can only be restored manually, they can be retrieved anymore from cloudron dashboard, the only way is to follow the manual instruction from the doc to retrieve backup ID etc..
manual remount wouldn't be an issue for my use case If I could get the existing backup listed when the volume/storage is remounted.
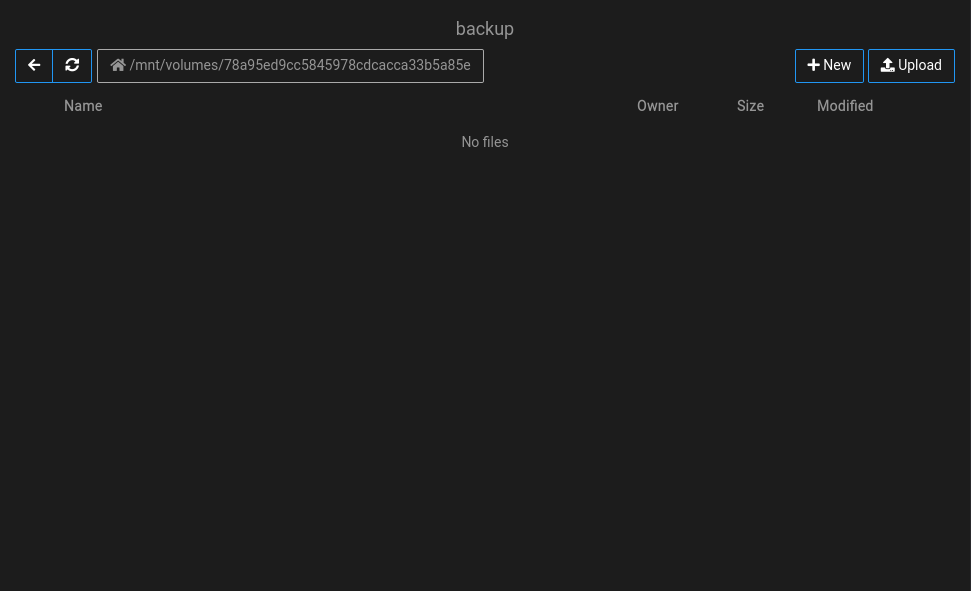
volume view remounted :
backup view remounted :
the backup listing view after everything is remounted :
I was wondering if it wouldn't be a good idea to have a button to rescan the backup target for backups that match previously made cloudron backups ?
@rmdes actually I am not sure if you use that thing correctly. Volumes and the backup storage are not really related. The way you have it configured, the same mountpoint would be mounted twice. Once for the volume (which is supposed to be used within apps) and the backup storage.
@hendrikvl we try to fix this reboot and volume mounting issue in the upcoming release.
-
@rmdes actually I am not sure if you use that thing correctly. Volumes and the backup storage are not really related. The way you have it configured, the same mountpoint would be mounted twice. Once for the volume (which is supposed to be used within apps) and the backup storage.
@hendrikvl we try to fix this reboot and volume mounting issue in the upcoming release.
@nebulon wow, alright, I may have misunderstood the documentation then, will remove on the volume side
- now I remember, I had it on the volume because one of my apps/domains was reading a music folder from the same sshfs mount point, which happened to be the same storage.
-
@nebulon wow, alright, I may have misunderstood the documentation then, will remove on the volume side
- now I remember, I had it on the volume because one of my apps/domains was reading a music folder from the same sshfs mount point, which happened to be the same storage.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login