Should ollama be part of this app package?
-
Was wondering if people had thoughts on this. Should https://github.com/ollama/ollama be packaged as part of this app? Maybe this can be an optional component.
The models have some heavy requirements: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Also, Cloudron does not have GPU support for containers yet, so I don't know how well these work.
-
Ollama should definitely be part of the app package, even if it's optional! We're extremely interested in this possibility and have a very powerful infrastructure on which Cloudron is installed. For companies like us, this would be a total game changer!
What's more, we think it's very important to always leave the choice open in this kind of project. That's one of the reasons why we chose cloudron.
What's more, we would use Ollama a lot.
Have a great day and thank you for this new feature. -
I think many have suitable hardware to include and run ollama, so I don't see the RAM requirements are a reason for it not to be included.
There's a big demand for locally run AI models, so including ollama would be great.
However I do not know how he absence of a GPU (in CLoudron or on a server) would affect viability.
I guess we just have to try ? -
@timconsidine I tried it locally on my low end netcup, it works atleast. Very slowly but works.
@girish great !
I know all the big engines flaunt their speed, but for me it's not the primary issue.
Within reason of course.
How did you install ollama on netcup ? manually ? docker run ? docker-compose ?
I'm looking for a decent docker-compose.yaml as I prefer that for my non-cloudron docker apps (using traefik which I have got sussed, mostly).Indie app dev, scratching my itches, lover of Cloudron PaaS, communityapps.appx.uk
-
At least as long as the App throws errors because Ollama is unavailable - but OpenAI could be still used - it should be included in the package.
-
@girish great !
I know all the big engines flaunt their speed, but for me it's not the primary issue.
Within reason of course.
How did you install ollama on netcup ? manually ? docker run ? docker-compose ?
I'm looking for a decent docker-compose.yaml as I prefer that for my non-cloudron docker apps (using traefik which I have got sussed, mostly).@timconsidine said in Should ollama be part of this app package?:
How did you install ollama on netcup ? manually ? docker run ? docker-compose ?
ollama is just a single go binary. I just downloaded it to /app/data and chmod +x and ran it
") you can see the openwebui-app repo where it is now integrated.
you can see the openwebui-app repo where it is now integrated. -
Was wondering if people had thoughts on this. Should https://github.com/ollama/ollama be packaged as part of this app? Maybe this can be an optional component.
The models have some heavy requirements: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
Also, Cloudron does not have GPU support for containers yet, so I don't know how well these work.
@girish said in Should ollama be part of this app package?:
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
This is ordinary RAM, right, not VRAM? SSDnodes is great for lavish amounts of RAM.
We would have to go into the application's settings in Cloudron and increase the resource allocation to e.g. 16GB?
-
@timconsidine said in Should ollama be part of this app package?:
How did you install ollama on netcup ? manually ? docker run ? docker-compose ?
ollama is just a single go binary. I just downloaded it to /app/data and chmod +x and ran it
you can see the openwebui-app repo where it is now integrated.@girish I would much rather have ollama as part of the app package than having to do that!
One further suggestion: I think it should ship with a small but functioning model and prompt.
On first run, "nothing is there", which is nice for people who are used to having to configure everything, but it is not so encouraging if you are just getting started. You have to "leave" the instance and go to the openwebui website and then try and find a model and prompt.
I guess most people won't want that, so I think we should anyway include a step by step in the documentation on how to get find and install a model and prompt that would work.
Also, I think the documentation could benefit from your above guidelines on what size model to use depending on your available RAM.
-
Local ollama is now integrated. You have to reinstall the app though.
Keep your expectations in check. It probably won't work great if you don't have a good CPU and we have no GPU integration yet. It's very slow with low end CPUs. I am not an expert on the RAM/CPU/GPU requirements. Feel free to experiment.
-
@girish I would much rather have ollama as part of the app package than having to do that!
One further suggestion: I think it should ship with a small but functioning model and prompt.
On first run, "nothing is there", which is nice for people who are used to having to configure everything, but it is not so encouraging if you are just getting started. You have to "leave" the instance and go to the openwebui website and then try and find a model and prompt.
I guess most people won't want that, so I think we should anyway include a step by step in the documentation on how to get find and install a model and prompt that would work.
Also, I think the documentation could benefit from your above guidelines on what size model to use depending on your available RAM.
@LoudLemur said in Should ollama be part of this app package?:
One further suggestion: I think it should ship with a small but functioning model and prompt.
Now with the local ollama integration, you can download whichever models you want from the UI itself. The models are quite big so pre-installing them is not an option.
-
@LoudLemur said in Should ollama be part of this app package?:
One further suggestion: I think it should ship with a small but functioning model and prompt.
Now with the local ollama integration, you can download whichever models you want from the UI itself. The models are quite big so pre-installing them is not an option.
-
-
 G girish forked this topic on
G girish forked this topic on
-
@girish great job!
one question, is it possible to enable external use of the ollama api ?
@Kubernetes I am not sure if this is what you are asking, but I am currently running Ollama separately via docker with a dedicated OLD GPU (8GB NVIDIA) on my NAS (working shockingly good on 7B/11B GGUFs and moderately good on 13B ones) and Cloudron on a VM on the same NAS. I use Ollama externally (technically it's still local on the machine's hardware, but is configured as though it is not) and deactivated this app's localhost Ollama. This can be done by going into the Cloudron's Open-Webui File Manager through the settings and configuring "env.sh" -
# Change this to false to disable local ollama and use your own export LOCAL_OLLAMA_ENABLED=false # When using remote ollama, change this to the ollama's base url export OLLAMA_API_BASE_URL="http://changethis:11434" # When local ollama is enabled, this is location for the downloaded models. # If the path is under /app/data, models will be backed up. Note that models # can be very large. To skip backup of models, move the models to a volume (https://docs.cloudron.io/volumes/) # export OLLAMA_MODELS=/app/data/ollama-home/modelsIs this what you are referring to?
-
@Kubernetes I am not sure if this is what you are asking, but I am currently running Ollama separately via docker with a dedicated OLD GPU (8GB NVIDIA) on my NAS (working shockingly good on 7B/11B GGUFs and moderately good on 13B ones) and Cloudron on a VM on the same NAS. I use Ollama externally (technically it's still local on the machine's hardware, but is configured as though it is not) and deactivated this app's localhost Ollama. This can be done by going into the Cloudron's Open-Webui File Manager through the settings and configuring "env.sh" -
# Change this to false to disable local ollama and use your own export LOCAL_OLLAMA_ENABLED=false # When using remote ollama, change this to the ollama's base url export OLLAMA_API_BASE_URL="http://changethis:11434" # When local ollama is enabled, this is location for the downloaded models. # If the path is under /app/data, models will be backed up. Note that models # can be very large. To skip backup of models, move the models to a volume (https://docs.cloudron.io/volumes/) # export OLLAMA_MODELS=/app/data/ollama-home/modelsIs this what you are referring to?
@coniunctio Yes, exactly this was what I was referring to. Thank you for bringing this example up.
-
Local ollama is now integrated. You have to reinstall the app though.
Keep your expectations in check. It probably won't work great if you don't have a good CPU and we have no GPU integration yet. It's very slow with low end CPUs. I am not an expert on the RAM/CPU/GPU requirements. Feel free to experiment.
@girish said in Should ollama be part of this app package?:
Local ollama is now integrated. You have to reinstall the app though.
Keep your expectations in check. It probably won't work great if you don't have a good CPU and we have no GPU integration yet. It's very slow with low end CPUs. I am not an expert on the RAM/CPU/GPU requirements. Feel free to experiment.
I have been using the workaround of disabling local Ollama with the Cloudron app and running a separate (external) docker container installation of Ollama with a dedicated GPU on the same hardware and then linking that instance of Ollama to the Cloudron instance of Open-WebUI. Somehow, this configuration is faster on a NAS purchased in 2018 with an add-on NVIDIA 8GB GPU than my M1 MacBook Pro with 16GB RAM and integrated GPU purchased more recently. The additional bonus of running the Cloudron Open-WebUI vs the localhost version on my Apple silicon MBP is that I can use my local LLMs on my mobile devices in transit when my laptop is shut down.
-
personally I disabled the ollama local, because my Cloudron doesnt have GPU and on CPU it is too painfull.
in exchange; I activated a bunch of Providers API compatible with OpenAI
but at the end I realized that I just need OpenRouter to access all of them.
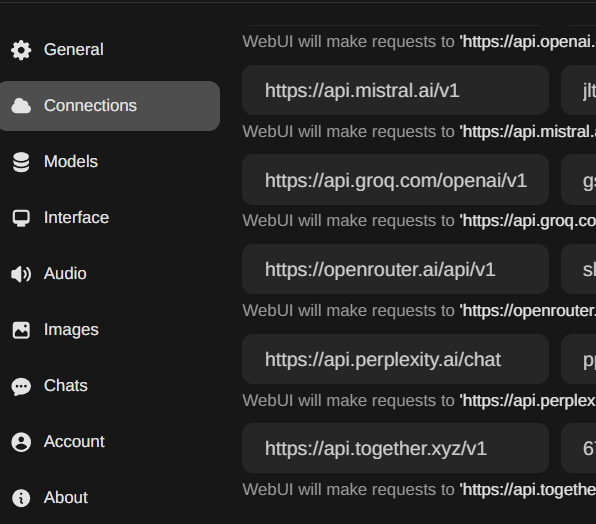
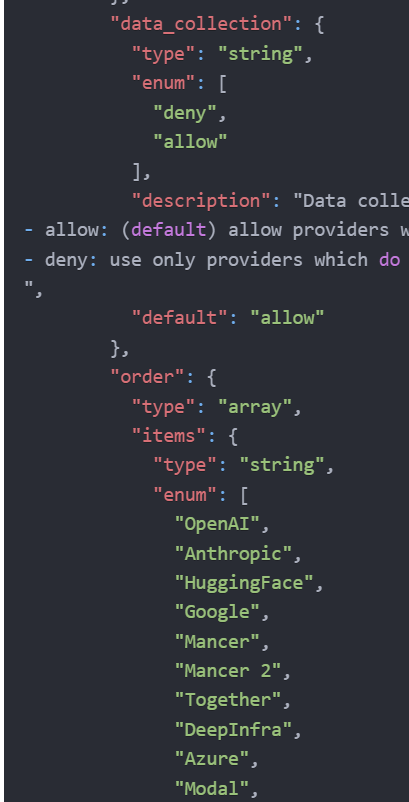
with OpenRouter, you could even block providers that logs your queries;
which I will Feature Request for Open-WebUI
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login