Unable to login to my admin panel and Cloudron apps (Possible local DNS or unbound issue?)


-
I am a long time Cloudron customer because I value your work. This is the first time I have run into an issue that I could not resolve on my own through the outlined steps offered in the Cloudron troubleshooting page. I am at a loss at how to fix this issue.
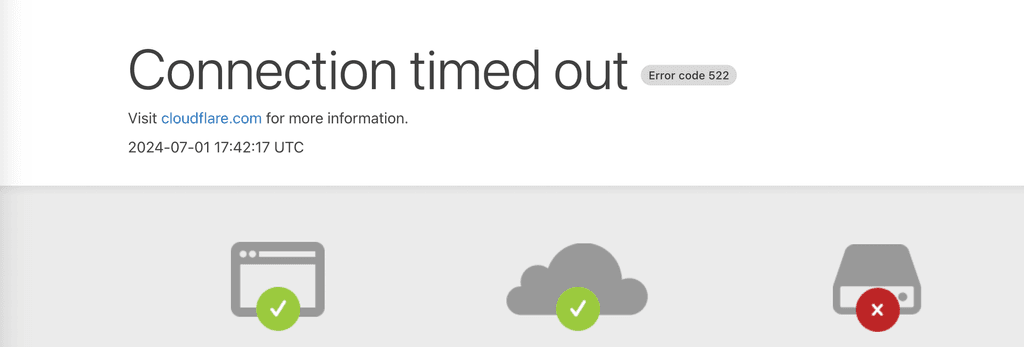
I am wondering if there is an issue with the local DNS configuration or some change that happened as the result of an automatic update that I'm unaware of as I'm getting the Cloudron DNS errors when trying to login to my Cloudron admin panel and Cloudron apps. I have SSH'd into my Cloudron VM installed on my home NAS and am able to do so via internal ip range on my home network.
This issue did follow any changes that I made on the VM itself (Ubuntu 22.04 server), nor at the Cloudron admin ("my.cloudron.adminpage"), nor at Cloudflare that hosts my domain/DNS entries. Can anyone point me in the right direction for troubleshooting steps or steps to fix local DNS assignment on Ubuntu Server 22.04? Wondering, are there Cloudron tech/customer support representatives here that read these messages?
My box.log file shows that my apps are running:
2024-06-30T00:00:10.328Z box:apphealthmonitor app health: 10 running / 2 stopped / 3 unresponsive 2024-06-30T00:10:00.009Z box:network/generic getIPv4: querying ipv4.api.cloudron.io to get server IPv4 2024-06-30T00:10:00.557Z box:dyndns refreshDns: no change in IP. ipv4: xx.xxx.xxx.xx ipv6: null
-
 G girish marked this topic as a question on
G girish marked this topic as a question on
-
I am a long time Cloudron customer because I value your work. This is the first time I have run into an issue that I could not resolve on my own through the outlined steps offered in the Cloudron troubleshooting page. I am at a loss at how to fix this issue.
I am wondering if there is an issue with the local DNS configuration or some change that happened as the result of an automatic update that I'm unaware of as I'm getting the Cloudron DNS errors when trying to login to my Cloudron admin panel and Cloudron apps. I have SSH'd into my Cloudron VM installed on my home NAS and am able to do so via internal ip range on my home network.
This issue did follow any changes that I made on the VM itself (Ubuntu 22.04 server), nor at the Cloudron admin ("my.cloudron.adminpage"), nor at Cloudflare that hosts my domain/DNS entries. Can anyone point me in the right direction for troubleshooting steps or steps to fix local DNS assignment on Ubuntu Server 22.04? Wondering, are there Cloudron tech/customer support representatives here that read these messages?
My box.log file shows that my apps are running:
2024-06-30T00:00:10.328Z box:apphealthmonitor app health: 10 running / 2 stopped / 3 unresponsive 2024-06-30T00:10:00.009Z box:network/generic getIPv4: querying ipv4.api.cloudron.io to get server IPv4 2024-06-30T00:10:00.557Z box:dyndns refreshDns: no change in IP. ipv4: xx.xxx.xxx.xx ipv6: null@coniunctio said in Unable to login to my admin panel and Cloudron apps (Possible local DNS or unbound issue?):
Wondering, are there Cloudron tech/customer support representatives here that read these messages?
We practically live here

-
To narrow down the issue a bit, if you disable Cloudflare proxying temporarily does it work fine?
@nebulon Does not work when disabling cloudflare proxying.
-
@coniunctio said in Unable to login to my admin panel and Cloudron apps (Possible local DNS or unbound issue?):
Wondering, are there Cloudron tech/customer support representatives here that read these messages?
We practically live here
-
@girish what is best way to get some support with this issue from customer/tech support?
@coniunctio yes, you can write to support@cloudron.io .
-
We have experienced issues for the past two days as well. Cloudron and all apps can't be reached for several minutes, then it starts working again for a few hours.
We host Cloudron on a Contabo VPS and have not changed any settings on Cloudron or Contabo.
Right now, for instance, it is not working. It was not working yesterday shortly before midnight. And a few times in between.
EDIT: Now it's working again. It always comes back after ~3-5 minutes.
-
@coniunctio yes, you can write to support@cloudron.io .
-
@girish Thank you! I downloaded the Cloudron support diagnostics through terminal and emailed them with the link to this support forum post and the diagnostics / logs + my Cloudron ID. Hopefully I will hear back from someone soon.
@coniunctio I have replied now. Let's continue there and post the conclusion here.
-
@coniunctio I have replied now. Let's continue there and post the conclusion here.
This post is deleted! -
@coniunctio I have replied now. Let's continue there and post the conclusion here.
@girish I have gathered the information you requested and responded via email. I would really like (need) some live assistance from a support person.
-
To anyone following this thread, I have good news and bad news:
Good news: My issue is resolved. I am now able to log into my Cloudron Dashboard and apps at their respective subdomains, and Cloudron reverse proxying to my Docker apps/containers hosted outside of Cloudron.
Bad news: I tried every troubleshooting angle that I could find both via my own research, via Cloudron tech support, and through ChatGPT by unloading my error logs and step by step troubleshooting at the CLI/terminal level of my Ubuntu Server VM layer. Nothing worked.
Last night as a semi-regular part of my digital housecleaning and maintenance, I ran a disk permissions fix on my home NAS where the Ubuntu Server VM --> Cloudron resides and next thing I know, I received an email from @girish with a screenshot of my Cloudron Dashboard loading. 🧐
Are there any particular Cloudron or Ubuntu Server error logs that I might be able to throw into ChatGPT to figure out what happened so I can report back here?
-
-
G girish has marked this topic as solved on
-
@marylou when it's not reachable, try to ping the server and also ssh in to see if it's some issue from Contabo side.
-
@coniunctio off. all quite strange, hard to guess what goes this working again! But from the logs you sent us on support@, the box code , nginx, unbound were all running fine. This means most likely it is some internal network issue .

@girish What is the location of the Cloudron log that would have observed any changes that were observed when I was able to use Cloudron again? Or is this an error log located at the Ubuntu Server (Virtual Machine, v24.04) level?
I will update this post with that information if I can find what changed for Cloudron to be available again, as the only change I can think of was doing a disk permissions fix to the "shared folder" that the VM is installed on the RAID configuration on my home NAS hardware. That seems like a very imprecise and not very helpful "resolution" to the issue related to this thread for archival (support) purposes.
-
@coniunctio the support tool collects logs and status from various tools.
- systemctl status mysql - status of the database used by cloudron dashboard
- systemctl status box - status of cloudron dashboard
- systemctl status nginx - status of nginx
- systemctl status docker - status of docker
- host my.domain.com - what you domain is pointing to
If the above look correct, it's likely everything is alright. This can be gather from the output of
cloudron-support --send-diagnosticsorcloudron-support --troubleshoot. -
@coniunctio the support tool collects logs and status from various tools.
- systemctl status mysql - status of the database used by cloudron dashboard
- systemctl status box - status of cloudron dashboard
- systemctl status nginx - status of nginx
- systemctl status docker - status of docker
- host my.domain.com - what you domain is pointing to
If the above look correct, it's likely everything is alright. This can be gather from the output of
cloudron-support --send-diagnosticsorcloudron-support --troubleshoot.@joseph Thank you and yes, did all those, and was in communication with tech support. The issue is actually mysteriously resolved and I'm just trying to figure out what happened so I can share that in this thread and hopefully avoid repeating this issue in the future.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login