ETA for GPU support? Could we contribute to help it along?
-
We haven't started working on this as such. I think the hard part is the GPU support in docker is varied. Are you looking for support for NVIDIA GPUs ?
@girish said in ETA for GPU support? Could we contribute to help it along?:
We haven't started working on this as such. I think the hard part is the GPU support in docker is varied. Are you looking for support for NVIDIA GPUs ?
Nvidia GPU support would be the one to have, at the moment, if only one brand could be supported. There are a lot of ai libraries for nvidia.
-
We haven't started working on this as such. I think the hard part is the GPU support in docker is varied. Are you looking for support for NVIDIA GPUs ?
@girish said in ETA for GPU support? Could we contribute to help it along?:
I think the hard part is the GPU support in docker is varied.
From Arya:
"As of 2023, GPU support in Docker, particularly for AI applications, has made significant strides but still faces challenges. The main issue is that Docker was originally designed for CPU-based applications and struggled to efficiently utilize GPU resources. This led to performance issues and difficulty in deploying GPU-accelerated applications within Docker containers. To address these challenges, several projects have emerged to make Docker better suited for GPU workloads:
NVIDIA Docker: NVIDIA, the leading GPU manufacturer, developed the NVIDIA Docker toolkit, which provides a Docker image and runtime that allows containers to leverage NVIDIA GPUs. It simplifies the deployment of GPU-accelerated applications within Docker.
ROCm Docker: AMD's ROCm (Radeon Open Compute) platform offers Docker images optimized for AMD GPUs, enabling developers to run GPU-accelerated applications in Docker containers on AMD hardware.
CUDA Docker: CUDA is NVIDIA's parallel computing platform and programming model for GPUs. CUDA Docker images are available, providing a pre-configured environment for running CUDA applications within Docker containers.
Despite these advancements, challenges remain, such as:
Performance overhead: Running GPU applications in Docker containers can introduce performance overhead compared to running them natively.
Resource isolation: Ensuring proper resource isolation between containers sharing the same GPU can be complex.
Compatibility: Ensuring compatibility between different GPU drivers, Docker versions, and application dependencies requires careful management.
To further improve GPU support in Docker, ongoing efforts focus on enhancing performance, simplifying deployment, and improving resource management. These projects aim to make Docker a more viable option for running GPU-accelerated AI applications, enabling easier deployment and scalability." -
We haven't started working on this as such. I think the hard part is the GPU support in docker is varied. Are you looking for support for NVIDIA GPUs ?
-
@girish said in ETA for GPU support? Could we contribute to help it along?:
I think the hard part is the GPU support in docker is varied.
From Arya:
"As of 2023, GPU support in Docker, particularly for AI applications, has made significant strides but still faces challenges. The main issue is that Docker was originally designed for CPU-based applications and struggled to efficiently utilize GPU resources. This led to performance issues and difficulty in deploying GPU-accelerated applications within Docker containers. To address these challenges, several projects have emerged to make Docker better suited for GPU workloads:
NVIDIA Docker: NVIDIA, the leading GPU manufacturer, developed the NVIDIA Docker toolkit, which provides a Docker image and runtime that allows containers to leverage NVIDIA GPUs. It simplifies the deployment of GPU-accelerated applications within Docker.
ROCm Docker: AMD's ROCm (Radeon Open Compute) platform offers Docker images optimized for AMD GPUs, enabling developers to run GPU-accelerated applications in Docker containers on AMD hardware.
CUDA Docker: CUDA is NVIDIA's parallel computing platform and programming model for GPUs. CUDA Docker images are available, providing a pre-configured environment for running CUDA applications within Docker containers.
Despite these advancements, challenges remain, such as:
Performance overhead: Running GPU applications in Docker containers can introduce performance overhead compared to running them natively.
Resource isolation: Ensuring proper resource isolation between containers sharing the same GPU can be complex.
Compatibility: Ensuring compatibility between different GPU drivers, Docker versions, and application dependencies requires careful management.
To further improve GPU support in Docker, ongoing efforts focus on enhancing performance, simplifying deployment, and improving resource management. These projects aim to make Docker a more viable option for running GPU-accelerated AI applications, enabling easier deployment and scalability."@LoudLemur said in ETA for GPU support? Could we contribute to help it along?:
@girish said in ETA for GPU support? Could we contribute to help it along?:
I think the hard part is the GPU support in docker is varied.
From Arya:
"As of 2023, GPU support in Docker, particularly for AI applications, has made significant strides but still faces challenges. The main issue is that Docker was originally designed for CPU-based applications and struggled to efficiently utilize GPU resources. ...
Thanks for that info, I wasn't aware of that challenge but it certainly makes sense.
The Open WebUI installation page talks about running the Docker image with GPU support but doesn't mention those problems: https://docs.openwebui.com/getting-started/
-
Thinking further on this... Perhaps it's not genuine Cloudron GPU support that we need.
Reading my original question about GPU support in a Cloudron context, I suppose it's easy to assume that there's an expectation of containerized resource management just like we get in all our Cloudron apps - the ability to segregate and limit GPU and attached VRAM just like we can for CPU, RAM, etc. While that would certainly be wonderful, it's not actually what we need for our business case. We just need the ability for OpenWebUI to draw on the hardware GPU resources we attach to its server (which is a virtual machine in our case), and run separate OpenWebUI apps easily with separate logins and datastores (which you've already given us).
Which OpenWebUI already appears to do, I suppose. If the container is started with the GPU usage switch, my understanding is that's all that's needed in the basic case. Please correct me if I'm wrong:
E.g. docker run -d -p 3000:8080 --gpus all etc...
https://docs.openwebui.com/getting-started/So my new questions are these (without having tried anything out yet):
-
If we installed the NVIDIA Ubuntu GPU drivers in the Cloudron OS and started the OpenWebUI container with the GPU switch, would it just work?
-
Does installing the GPU drivers interfere with Cloudron's upgrade processes? (In our case, we wouldn't mind having to manage the GPU drivers separately, we don't expect Cloudron to manage non-native additions.)
-
If we got past those first two questions, could we get a simple switch on the OpenWebUI Cloudron container to enable GPU support rather than having to set up our own custom container?
Cloudron isn't our virtualisation layer, we use VMWare in our case. So we can target our GPU usage to a Cloudron installation, we don't need to go further and manage it at the app level. (Actually making GPUs work in VMWare is a lot harder than it sounds, we found, but that's a separate problem.)
Of course I know nothing of how Cloudron is managing and segregating resources across its docker containers. Perhaps it is wishful thinking. But to be clear, we don't need fancy app level virtual GPU handling, we just want to use our GPU in one (or any) of the running apps. So I'm crossing fingers for good answers to the above questions.
")
(On a separate but interesting note, we've been hoping to do some Cloudron experimentation on this front. And they're not even hard experiments that we could do on a bare metal box, but we've been trying to do it in our data centre hosting environment on our existing systems as a proper proof of concept... However it's been a helluva job spinning up a pilot project with some older Dell servers we have running in a data centre with VMWare just to the point of being able to run GPUs at all, let alone getting as far as experimenting with Cloudron containers.
- We got some Tesla P40s running in some Dell r720xd's for our pilot project. Sourcing the right hardware including cards and power cables was hard enough.
- Then we didn't know what would fit where in which servers because none of it is officially supported or clearly documented.
- Then we found we had to upgrade our power supplies even though we thought the standard ones worked on paper.
- Then the hoops you have to jump through with both server firmware and BIOS/boot settings, and virtual machine BIOS and boot settings, and then VMWare updates and driver installations are CRAZY...
- We've finally got as far as making these things operational only to find that our VMWare Essentials licence doesn't provide virtual GPU support. This fact doesn't seem to be clearly written anywhere in the 1,000 documents we've read lately until you know exactly what to look for, and since BroadCom's recent purchase of VMWare the affordable licences we need seem to have disappeared.
So we still haven't booted a VMWare based Cloudron virtual machine in a data centre with an enterprise GPU in it yet... Our theory that low cost, flexibly hosted, easily backed up, privately hosted AI agents and learning data repositories should be available to smaller enterprises who care about privacy/security and cost enough to avoid the public clouds has encountered many challenges so far. However I think we're not far off - though for licensing reasons I think we might need to re-learn everything we know using a different hypervisor before the end - and I'd like to report back about how this all goes running on Cloudron in the very near future.)
-
-
Thinking further on this... Perhaps it's not genuine Cloudron GPU support that we need.
Reading my original question about GPU support in a Cloudron context, I suppose it's easy to assume that there's an expectation of containerized resource management just like we get in all our Cloudron apps - the ability to segregate and limit GPU and attached VRAM just like we can for CPU, RAM, etc. While that would certainly be wonderful, it's not actually what we need for our business case. We just need the ability for OpenWebUI to draw on the hardware GPU resources we attach to its server (which is a virtual machine in our case), and run separate OpenWebUI apps easily with separate logins and datastores (which you've already given us).
Which OpenWebUI already appears to do, I suppose. If the container is started with the GPU usage switch, my understanding is that's all that's needed in the basic case. Please correct me if I'm wrong:
E.g. docker run -d -p 3000:8080 --gpus all etc...
https://docs.openwebui.com/getting-started/So my new questions are these (without having tried anything out yet):
-
If we installed the NVIDIA Ubuntu GPU drivers in the Cloudron OS and started the OpenWebUI container with the GPU switch, would it just work?
-
Does installing the GPU drivers interfere with Cloudron's upgrade processes? (In our case, we wouldn't mind having to manage the GPU drivers separately, we don't expect Cloudron to manage non-native additions.)
-
If we got past those first two questions, could we get a simple switch on the OpenWebUI Cloudron container to enable GPU support rather than having to set up our own custom container?
Cloudron isn't our virtualisation layer, we use VMWare in our case. So we can target our GPU usage to a Cloudron installation, we don't need to go further and manage it at the app level. (Actually making GPUs work in VMWare is a lot harder than it sounds, we found, but that's a separate problem.)
Of course I know nothing of how Cloudron is managing and segregating resources across its docker containers. Perhaps it is wishful thinking. But to be clear, we don't need fancy app level virtual GPU handling, we just want to use our GPU in one (or any) of the running apps. So I'm crossing fingers for good answers to the above questions.
(On a separate but interesting note, we've been hoping to do some Cloudron experimentation on this front. And they're not even hard experiments that we could do on a bare metal box, but we've been trying to do it in our data centre hosting environment on our existing systems as a proper proof of concept... However it's been a helluva job spinning up a pilot project with some older Dell servers we have running in a data centre with VMWare just to the point of being able to run GPUs at all, let alone getting as far as experimenting with Cloudron containers.
- We got some Tesla P40s running in some Dell r720xd's for our pilot project. Sourcing the right hardware including cards and power cables was hard enough.
- Then we didn't know what would fit where in which servers because none of it is officially supported or clearly documented.
- Then we found we had to upgrade our power supplies even though we thought the standard ones worked on paper.
- Then the hoops you have to jump through with both server firmware and BIOS/boot settings, and virtual machine BIOS and boot settings, and then VMWare updates and driver installations are CRAZY...
- We've finally got as far as making these things operational only to find that our VMWare Essentials licence doesn't provide virtual GPU support. This fact doesn't seem to be clearly written anywhere in the 1,000 documents we've read lately until you know exactly what to look for, and since BroadCom's recent purchase of VMWare the affordable licences we need seem to have disappeared.
So we still haven't booted a VMWare based Cloudron virtual machine in a data centre with an enterprise GPU in it yet... Our theory that low cost, flexibly hosted, easily backed up, privately hosted AI agents and learning data repositories should be available to smaller enterprises who care about privacy/security and cost enough to avoid the public clouds has encountered many challenges so far. However I think we're not far off - though for licensing reasons I think we might need to re-learn everything we know using a different hypervisor before the end - and I'd like to report back about how this all goes running on Cloudron in the very near future.)
If we installed the NVIDIA Ubuntu GPU drivers in the Cloudron OS and started the OpenWebUI container with the GPU switch, would it just work?
Not necessarily, it depends on the GPU. While it may seem like a good idea, results will be very random. Also,
nouveau(or whatever they're called now) drivers are the worst available out there. I've only had good results with nvidia official drivers.Does installing the GPU drivers interfere with Cloudron's upgrade processes? (In our case, we wouldn't mind having to manage the GPU drivers separately, we don't expect Cloudron to manage non-native additions.)
Yes. Nvidia drivers are a pain to manage and often need debugging.
-
-
If we installed the NVIDIA Ubuntu GPU drivers in the Cloudron OS and started the OpenWebUI container with the GPU switch, would it just work?
Not necessarily, it depends on the GPU. While it may seem like a good idea, results will be very random. Also,
nouveau(or whatever they're called now) drivers are the worst available out there. I've only had good results with nvidia official drivers.Does installing the GPU drivers interfere with Cloudron's upgrade processes? (In our case, we wouldn't mind having to manage the GPU drivers separately, we don't expect Cloudron to manage non-native additions.)
Yes. Nvidia drivers are a pain to manage and often need debugging.
There is progress to report...
@Lanhild said in ETA for GPU support? Could we contribute to help it along?:
If we installed the NVIDIA Ubuntu GPU drivers in the Cloudron OS and started the OpenWebUI container with the GPU switch, would it just work?
Not necessarily, it depends on the GPU.
Per above, we have some Nvidia Tesla P40s in our proof of concept environment.
The use case introduced in this thread is based on a desire to make low cost, truly private AI workloads accessible to small and medium business, hopefully using Cloudron as a management tool for OpenWebUI containers in particular, because Cloudron is so easy and nice. (An easy way to run AI RAG and even just vanilla inference even on low parameter LLMs will be invaluable to many businesses.)
In this use case, I don't believe there is a need to support consumer GPUs - I understand that would be an endless tail-chasing exercise.
Thanks to Nvidia's current near-monopoly in the server GPU space, I believe there is only a fairly small number of enterprise grade GPUs that that are likely to be used in a lot of real world scenarios. Though I don't claim to be an expert in this area or have any quotable evidence, my understanding from everything (a lot) that we've read and tested ourselves is that for the Nvidia GPUs, these all run with the same core Nvidia drivers and CUDA toolkit. If other hosting providers or businesses are anything like us, I guess they'll avoid non-standard hardware and software environments and frameworks as much as possible. By which I mean to suggest, officially supporting only a few general/wide/mainstream/standard conditions is likely to be very useful to a significant number of Cloudron users, even if we can't support everyone.
While it may seem like a good idea, results will be very random. Also,
nouveau(or whatever they're called now) drivers are the worst available out there. I've only had good results with nvidia official drivers.Cloudron installs in a 'fresh Ubuntu' server installation, so it appears the
nouveaudrivers are not installed, so there's no need to install them or worry about them in our case, or a general Nvidia support case I think.Does installing the GPU drivers interfere with Cloudron's upgrade processes? (In our case, we wouldn't mind having to manage the GPU drivers separately, we don't expect Cloudron to manage non-native additions.)
Yes. Nvidia drivers are a pain to manage and often need debugging.
We are not Linux experts and YMMV of course, but we have got our GPU up and running inside our Cloudron/Ubuntu virtual machine along with CUDA toolkit installed, and ultimately we didn't find this very difficult once we understood what to do. In the end we only ran a few standard installation commands.
There was an
apt updatecommand in the middle of the process that I suppose is going to cause some grief for Cloudron. (Since we're not Linux experts we didn't know how to only update the components needed for our drivers and not everything else. But I also note, we did not runapt upgrade.) But otherwise from what we can tell, the Nvidia drivers + CUDA software combination appears to be quite independent of anything connected to Cloudron. (For the moment we've disabled Cloudron automatic updates.)The much harder part was making everything work at the server hardware (Dell servers) and hypervisor (VMWare) level. I'm happy to say that we now have this working and know how to make it work again. Although we are not able to fully virtualise our GPUs with our current VMWare licence, we don't really want to do this anyway, and we've got the GPU running at the VM level using PCI Passthrough. There were plenty of high hurdles to jump to get there, so if anyone needs any pointers on that front, feel free to reach out (although this part is highly dependent on the hardware and hypervisor combination).
So, we are not quite up to testing OpenWebUI on Cloudron VM with a GPU running yet... Now we need to figure out how to start OpenWebUI inside Cloudron with GPU support.
-
Unfortunately I don't personally know much about Docker and also its relationship with Cloudron.
Is there an easy (or other) way to start Cloudron's OpenWebUI container with GPU support like this?
From https://github.com/open-webui/open-webui:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaI dug around inside the app container and noticed OpenWebUI seems to attempt some kind of GPU detection when it starts up anyway. However according to the log, it didn't find anything even though the GPU appears to be fully functional on the Ubuntu host.
Nov 10 21:38:13 2024/11/10 10:38:13 routes.go:1189: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/app/data/ollama-home/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]" Nov 10 21:38:13 time=2024-11-10T10:38:13.934Z level=INFO source=images.go:755 msg="total blobs: 0" Nov 10 21:38:13 time=2024-11-10T10:38:13.935Z level=INFO source=images.go:762 msg="total unused blobs removed: 0" Nov 10 21:38:13 time=2024-11-10T10:38:13.935Z level=INFO source=routes.go:1240 msg="Listening on 127.0.0.1:11434 (version 0.4.1)" Nov 10 21:38:13 time=2024-11-10T10:38:13.936Z level=INFO source=common.go:135 msg="extracting embedded files" dir=/tmp/ollama3567657881/runners Nov 10 21:38:14 time=2024-11-10T10:38:14.050Z level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cuda_v12 rocm cpu cpu_avx cpu_avx2 cuda_v11]" Nov 10 21:38:14 time=2024-11-10T10:38:14.050Z level=INFO source=gpu.go:221 msg="looking for compatible GPUs" Nov 10 21:38:14 time=2024-11-10T10:38:14.050Z level=WARN source=gpu.go:732 msg="unable to locate gpu dependency libraries" Nov 10 21:38:14 time=2024-11-10T10:38:14.052Z level=WARN source=gpu.go:732 msg="unable to locate gpu dependency libraries" Nov 10 21:38:14 time=2024-11-10T10:38:14.052Z level=WARN source=gpu.go:732 msg="unable to locate gpu dependency libraries" Nov 10 21:38:14 time=2024-11-10T10:38:14.059Z level=WARN source=gpu.go:732 msg="unable to locate gpu dependency libraries" Nov 10 21:38:14 time=2024-11-10T10:38:14.064Z level=INFO source=gpu.go:386 msg="no compatible GPUs were discovered" Nov 10 21:38:14 time=2024-11-10T10:38:14.064Z level=INFO source=types.go:123 msg="inference compute" id=0 library=cpu variant=avx compute="" driver=0.0 name="" total="192.6 GiB" available="189.4 GiB"I'm a dummy in this space. Do I need to make the container aware of the GPU in some special way, or if we can modify the container startup parameters, is it possible that's all we need to do?
-
There is progress to report...
@Lanhild said in ETA for GPU support? Could we contribute to help it along?:
If we installed the NVIDIA Ubuntu GPU drivers in the Cloudron OS and started the OpenWebUI container with the GPU switch, would it just work?
Not necessarily, it depends on the GPU.
Per above, we have some Nvidia Tesla P40s in our proof of concept environment.
The use case introduced in this thread is based on a desire to make low cost, truly private AI workloads accessible to small and medium business, hopefully using Cloudron as a management tool for OpenWebUI containers in particular, because Cloudron is so easy and nice. (An easy way to run AI RAG and even just vanilla inference even on low parameter LLMs will be invaluable to many businesses.)
In this use case, I don't believe there is a need to support consumer GPUs - I understand that would be an endless tail-chasing exercise.
Thanks to Nvidia's current near-monopoly in the server GPU space, I believe there is only a fairly small number of enterprise grade GPUs that that are likely to be used in a lot of real world scenarios. Though I don't claim to be an expert in this area or have any quotable evidence, my understanding from everything (a lot) that we've read and tested ourselves is that for the Nvidia GPUs, these all run with the same core Nvidia drivers and CUDA toolkit. If other hosting providers or businesses are anything like us, I guess they'll avoid non-standard hardware and software environments and frameworks as much as possible. By which I mean to suggest, officially supporting only a few general/wide/mainstream/standard conditions is likely to be very useful to a significant number of Cloudron users, even if we can't support everyone.
While it may seem like a good idea, results will be very random. Also,
nouveau(or whatever they're called now) drivers are the worst available out there. I've only had good results with nvidia official drivers.Cloudron installs in a 'fresh Ubuntu' server installation, so it appears the
nouveaudrivers are not installed, so there's no need to install them or worry about them in our case, or a general Nvidia support case I think.Does installing the GPU drivers interfere with Cloudron's upgrade processes? (In our case, we wouldn't mind having to manage the GPU drivers separately, we don't expect Cloudron to manage non-native additions.)
Yes. Nvidia drivers are a pain to manage and often need debugging.
We are not Linux experts and YMMV of course, but we have got our GPU up and running inside our Cloudron/Ubuntu virtual machine along with CUDA toolkit installed, and ultimately we didn't find this very difficult once we understood what to do. In the end we only ran a few standard installation commands.
There was an
apt updatecommand in the middle of the process that I suppose is going to cause some grief for Cloudron. (Since we're not Linux experts we didn't know how to only update the components needed for our drivers and not everything else. But I also note, we did not runapt upgrade.) But otherwise from what we can tell, the Nvidia drivers + CUDA software combination appears to be quite independent of anything connected to Cloudron. (For the moment we've disabled Cloudron automatic updates.)The much harder part was making everything work at the server hardware (Dell servers) and hypervisor (VMWare) level. I'm happy to say that we now have this working and know how to make it work again. Although we are not able to fully virtualise our GPUs with our current VMWare licence, we don't really want to do this anyway, and we've got the GPU running at the VM level using PCI Passthrough. There were plenty of high hurdles to jump to get there, so if anyone needs any pointers on that front, feel free to reach out (although this part is highly dependent on the hardware and hypervisor combination).
So, we are not quite up to testing OpenWebUI on Cloudron VM with a GPU running yet... Now we need to figure out how to start OpenWebUI inside Cloudron with GPU support.
@robw Thank you very much for this report. Your goal of making low cost, truly private AI workloads accessible to small and medium business, hopefully using Cloudron as a management tool for OpenWebUI containers in particular is worthy. I would love to be able to do this and thank you for pioneering in this area.
-
No worries @LoudLemur - Though we're on a learning curve with the Ubuntu/Docker/Cloudron/Nvidia GPU stack combination, this is very much a trial and error process. Do you have any tips for me about starting the container with different options? I don't even know where to look.
I figured out we might need to install the Nvidia Container Toolkit and/or the
nvidia-docker2package and hoped one of these would be a magic bullet without modifying how the container starts, but alas, no. -
Apologies for any silly questions while we're still on a learning curve....
I see the container startup options in
/app/code/run.shinside the container when it's running but I understand I can't edit this; it's a read only file system. I've read the Cheat Sheet. I suppose I need to create a new custom container of my own to modify the startup options. Is that right?For what it's worth, as far as I can tell without having tested it, OpenWebUI (whether or not in Docker) gracefully degrades to running CPU-only support if you try to start it with GPU functionality and a GPU is not found anyway. So I don't really know why they have different startup options, unless it's for the sake of explicitness, or because startup happens faster or more reliably if you specify the option precisely, or perhaps because some people would prefer to run on CPU only.
Anyway, I am now wondering whether or not it would be a good idea to deploy the Cloudron package with GPU support enabled on the startup script as default. What do you think, Cloudron team? Or if that's not a good idea, perhaps to offer two different apps to download as needed?
I think that adding the
--gpus=allswitch and the:cudatag to the image name to the startup options might be all that's required. (Assuming the Ubuntu host has the Nvidia driver and CUDA and the Docker CUDA toolkit properly installed, I think it'll work, and if not, I think it'll fall back to using CPU.)[Edit: Others have been confused about the optional GPU support container startup option too. Seemingly it is because it might be a good idea to run OpenWebUI without GPU support when it's running on the same host as another container that wants GPU support, e.g. to avoid resource contention.]
-
R robw referenced this topic on
-
Per this thread I was able to modify
/app/code/run.shin the web terminal (and also pull/push it via the Cloudron CLI) after usingcloudron debug --app {appurl}in the CLI, then run OpenWebUI during recovery mode by running/app/pkg/start.sh. The app started and my modifications torun.share intact. However the GPU still wasn't found. My problem is that I don't know if my changes torun.shhad any effect on the app at all. I can't see anything that I understand instart.shorrun.shwhich convince me that my changes were actually applied. -
I feel like that if GPU support works, having OpenWebUI and Ollama as separate packages would make maintenance easier.
@Lanhild said in ETA for GPU support? Could we contribute to help it along?:
I feel like that if GPU support works, having OpenWebUI and Ollama as separate packages would make maintenance easier.
I note this is a bit off topic for the thread... But... It's an interesting idea. Perhaps it depends on your use case.
I can't speak to Cloudron product maintenance of course, only guess. As we're still learning about the relationships between all the components in the stack (Cloudron, Docker, Ubuntu, GPU drivers - just Nvidia data center GPUs in my case at the moment, CUDA, Ollama, OpenWebUI, and throw in server hardware and hypervisors if you're in a virtualized hosting scenario), I have come to understand that complexity of dependencies between components is a real challenge.
Perhaps there are different end-user level configurations that need to be performed between Ollama and OpenWebUI (e.g. stuff like GPU support, single sign-on, access permissions), so it could be a good idea for the product team to separate them from that point of view because one might need more updates and testing than the other, or it might provide more flexibility.
But I wonder, in terms of end (Cloudron) user needs, wouldn't you need to be a pretty advanced user to care? I mean, I can think of several end-user cases where separating Ollama from OpenWebUI gives technical or management or performance benefits, like:
- If you're using your Ollama instance from different endpoints (possibly including outside Cloudron)
- If you want to share Ollama access between apps for performance reasons but separate user and data management on different OpenWebUI instances (e.g. if you have multiple OpenWebUI instances running on one or more Cloudron installations)
- If the cost of hosting resources like storage/compute/RAM is an optimisation concern (e.g. even installing multiple instances of a single app can eat up premium storage space, and sharing compute/RAM of Ollama transactions among multiple apps could have a measurable benefit with more than a few OpenWebUI front ends)
- If you already have a centrally managed non-Cloudron Ollama server but you want Cloudron for OpenWebUI front ends
- If you want to reduce risk of stuff breaking between updates
- And plenty of other stuff along those flexibility lines...
... but otherwise if I'm a regular simple Cloudron user with a GPU installed, I think I just want to one-click-download and have it working without any fuss. I'm guessing (though I don't know) that most Cloudron customers are running at a relatively small scale where simplicity is more important than performance and flexibility. (Please do correct me on that if needed.)
To be clear, it's probably a really good thing to offer in my company's case. But I think we might be in the minority here.
-
Ok some further updates...
TL;DR - We still need help getting Cloudron's OpenWebUI container to start with GPU enabled. This is our bottlneck. Otherwise everything else works.
Now that we've figured out how to make our Dell servers and VMWare hypervisor* reliably support GPU all the way through to virtual machines, but failing to get Cloudron apps working with GPU, we have been looking for low cost 'hosting ready' virtual server alternatives for OpenWebUI. (Windows Server hosting that we like for a lot of other workloads is not a preferred option in this case.) At the VM level we've now got an Ubuntu/Caddy/Webmin (or Cockpit)/Docker/NVIDIA+CUDA stack fully operational with OpenWebUI/Ollama, and it's arguably a commercially viable solution.
And I must say, now that it's running in a 'hosting ready' environment with a software stack that's very similar to what Cloudron offers, even with our older-generation GPU test platform (Tesla P40s), the speed results from tests in OpenWebUI are extremely pleasing. I don't have tokens-per-second stats yet, but I can report one query that took 3.75 minutes using CPU only on the same host hardware, took 13 seconds with a single Tesla P40 GPU behind it, and left room on the GPU's VRAM for other concurrent queries.
But our stack still doesn't do all the nice stuff that Cloudron does without a lot of extra work - mail, backups, user directory, easy multi-tenanting, app leve resource limiting, automatic DNS, automatic updates, super easy installation (our current virtual server installation guide is still ~70 active configuration steps which can't be fully automated), and more.
Finally realising that we could run vanilla Docker test on the Cloudron host without breaking Cloudron (duh!), we ran the Nvidia sample workload from our Cloudron Ubuntu host. It works. So we know our server is ready.
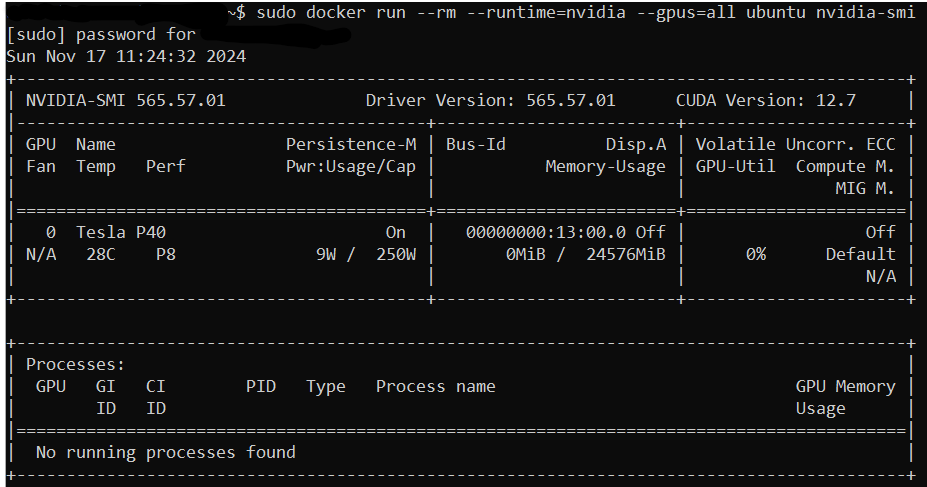
After initially avoiding running standalone Docker containers on our Cloudron Ubuntu host (because we didn't want to upset Cloudron), running the sample app made us realise we could run a test of OpenWebUI using vanilla Docker to test our system too... It also works.
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamatime=2024-11-17T11:40:46.328Z level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cpu_avx cpu_avx2 cuda_v11 cuda_v12 rocm_v60102 cpu]" time=2024-11-17T11:40:46.328Z level=INFO source=gpu.go:221 msg="looking for compatible GPUs" time=2024-11-17T11:40:47.791Z level=INFO source=types.go:123 msg="inference compute" id=GPU-2f9f15c7-39ba-5118-38fa-07ec8a1fa088 library=cuda variant=v12 compute=6.1 driver=12.7 name="Tesla P40" total="23.9 GiB" available="23.7 GiB" INFO : Started server process [1] INFO : Waiting for application startup. INFO : Application startup complete.So I'm now quite certain our only hurdle is figuring out how to make Cloudron's OpenWebUI start with GPU support. But for the life of me, as Cloudron+Docker learners, we can't figure it out, even for a non-persistent test run. Modifying
run.shdidn't help, and even while running in recovery mode started from the Cloudron CLI we can't see any way to make it work with modifications torun-compose.shor/app/pkg/start.shor theDockerfileor anything else.What can we do?
Please, can I repeat my offer to provide support (if needed) to get this done? At the very least , we could offer some $$ (and I hope the community might pitch in per my original post if more was needed), testing, notes from our own installation/test challenges, and an Nvidia GPU enabled virtual dev/test machine if required.
*Side note: I think VMWare used to offer a great hypervisor even for small scale, but now it's terrible for smaller customers (in my opinion). There are real alternatives these days, but hardly any that offer point-and-click container management. So virtual server layer container management tools that are as nice as Cloudron still have relevance beyond single server and home lab use cases, we think. Have I mentioned that we love Cloudron?
-
@Lanhild said in ETA for GPU support? Could we contribute to help it along?:
I feel like that if GPU support works, having OpenWebUI and Ollama as separate packages would make maintenance easier.
I note this is a bit off topic for the thread... But... It's an interesting idea. Perhaps it depends on your use case.
I can't speak to Cloudron product maintenance of course, only guess. As we're still learning about the relationships between all the components in the stack (Cloudron, Docker, Ubuntu, GPU drivers - just Nvidia data center GPUs in my case at the moment, CUDA, Ollama, OpenWebUI, and throw in server hardware and hypervisors if you're in a virtualized hosting scenario), I have come to understand that complexity of dependencies between components is a real challenge.
Perhaps there are different end-user level configurations that need to be performed between Ollama and OpenWebUI (e.g. stuff like GPU support, single sign-on, access permissions), so it could be a good idea for the product team to separate them from that point of view because one might need more updates and testing than the other, or it might provide more flexibility.
But I wonder, in terms of end (Cloudron) user needs, wouldn't you need to be a pretty advanced user to care? I mean, I can think of several end-user cases where separating Ollama from OpenWebUI gives technical or management or performance benefits, like:
- If you're using your Ollama instance from different endpoints (possibly including outside Cloudron)
- If you want to share Ollama access between apps for performance reasons but separate user and data management on different OpenWebUI instances (e.g. if you have multiple OpenWebUI instances running on one or more Cloudron installations)
- If the cost of hosting resources like storage/compute/RAM is an optimisation concern (e.g. even installing multiple instances of a single app can eat up premium storage space, and sharing compute/RAM of Ollama transactions among multiple apps could have a measurable benefit with more than a few OpenWebUI front ends)
- If you already have a centrally managed non-Cloudron Ollama server but you want Cloudron for OpenWebUI front ends
- If you want to reduce risk of stuff breaking between updates
- And plenty of other stuff along those flexibility lines...
... but otherwise if I'm a regular simple Cloudron user with a GPU installed, I think I just want to one-click-download and have it working without any fuss. I'm guessing (though I don't know) that most Cloudron customers are running at a relatively small scale where simplicity is more important than performance and flexibility. (Please do correct me on that if needed.)
To be clear, it's probably a really good thing to offer in my company's case. But I think we might be in the minority here.
@robw said in ETA for GPU support? Could we contribute to help it along?:
- If you already have a centrally managed non-Cloudron Ollama server but you want Cloudron for OpenWebUI front ends
Hey, that's my case
.Otherwise, I very much think that separating both of the Cloudron packages will be beneficial. Considering all the example use cases you listed, the need is more than justified.
A lot of companies that might deploy Cloudron for its ease of life features don't necessarily have a VPS with a GPU.
Also, (might help you to deepen your Cloudron knowledge) Cloudron packages usually are only one component/application.
Moreover, OpenWebUI is "just" a UI that supports connections to Ollama and isn't affiliated with it. Meaning that Ollama isn't a dependency of it at all.
-
@robw said in ETA for GPU support? Could we contribute to help it along?:
- If you already have a centrally managed non-Cloudron Ollama server but you want Cloudron for OpenWebUI front ends
Hey, that's my case
.Otherwise, I very much think that separating both of the Cloudron packages will be beneficial. Considering all the example use cases you listed, the need is more than justified.
A lot of companies that might deploy Cloudron for its ease of life features don't necessarily have a VPS with a GPU.
Also, (might help you to deepen your Cloudron knowledge) Cloudron packages usually are only one component/application.
Moreover, OpenWebUI is "just" a UI that supports connections to Ollama and isn't affiliated with it. Meaning that Ollama isn't a dependency of it at all.
@Lanhild said in ETA for GPU support? Could we contribute to help it along?:
A lot of companies that might deploy Cloudron for its ease of life features don't necessarily have a VPS with a GPU.
Also, (might help you to deepen your Cloudron knowledge) Cloudron packages usually are only one component/application.
Moreover, OpenWebUI is "just" a UI that supports connections to Ollama and isn't affiliated with it. Meaning that Ollama isn't a dependency of it at all.
Excellent points @Lanhild - you've convinced me.
And there are benefits on the Ollama side too. I would appreciate the benefit in using Cloudron to keep our Ollama installation automatically up to date on its own, for instance.
In fact, given our remaining inability to modify the existing Cloudron OpenWebUI app to run with our GPUs, for our small clients we are now thinking this way - I.e. using Cloudron just for the OpenWebUI component and letting them connect to our separately hosted Ollama. It's a bit less convenient than we were hoping, but at least we'll still have segregated data and user management for each client in OpenWebUI.
So now, I also want a Cloudron OpenWebUI app that does not come with bundled Ollama, so that I can be sure these customers don't hammer our CPUs and get frustrated by a slow user experiences.
-
R robw referenced this topic on
-
R robw referenced this topic on
-
R robw referenced this topic on
-
N nottheend referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login