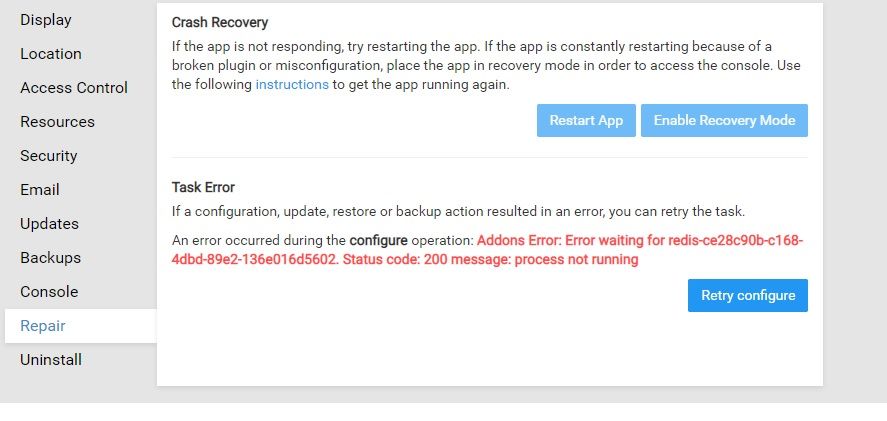
Some kind of redis error breaking the app
-
I tried server restart but didn't help. Can access the web terminal only from the logs and it is in constant reconnecting.
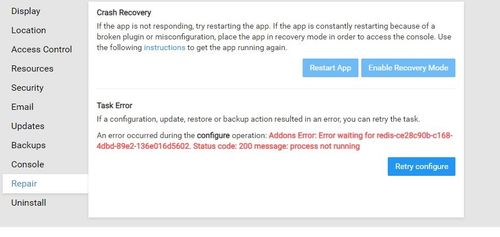
P.S. Just tried to recover from backup and it shows the same error.
@vova which app?
-
I tried server restart but didn't help. Can access the web terminal only from the logs and it is in constant reconnecting.
P.S. Just tried to recover from backup and it shows the same error.
@vova I had a similar problem about 20 hours ago; 10 of my 13 apps were down.
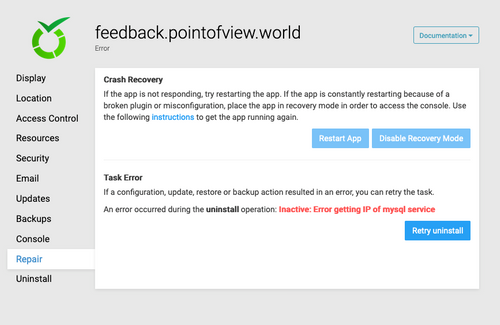
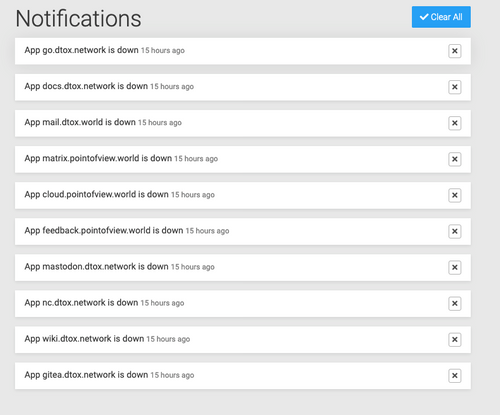
I got similar messages for Redis, MySQL and Postgres... couldn't recover from backups...the buttons froze. Reboot did not work.I am hosted on Hetzner; I went to the cloud console and did a "soft" server shutdown... followed by a "hard" shutdown...and then a Restart of the server.
In 5 minutes, 10 of the 13 apps had recovered gracefully. The remaining three should "error", so I reinstalled them from last backup (and lost some 18 hours of data!).
Hope this helps. -
@vova I'm having this redis problem as well with 10 apps. Did you solved it by running something or was it just a miracle?
-
@vova Can you try
docker restart redis-<the-id-in-the-screenshot>on your server? (in 5.2, there is a button to restart redis now). -
@girish If I try this, the server goes very slow and redis never finishes. I tries also redis restart from the services tab but it stays unresponding. Any suggestions?
@alex-adestech That was quite some debugging session
")
Wanted to leave some notes here... The server was an EC2 R5 xlarge instance. It worked well but when you resize any app, it will just hang. And the whole server will stop responding eventually. One curious thing was that server had 32GB and ~20GB was in buff/cache in free -m output. I have never seen kernel caching so much. We also found this backtrace in dmesg output:
INFO: task docker:111571 blocked for more than 120 seconds. "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. docker D 0000000000000000 0 111571 1 0x00000080 ffff881c01527ab0 0000000000000086 ffff881c332f5080 ffff881c01527fd8 ffff881c01527fd8 ffff881c01527fd8 ffff881c332f5080 ffff881c01527bf0 ffff881c01527bf8 7fffffffffffffff ffff881c332f5080 0000000000000000 Call Trace: [<ffffffff8163a909>] schedule+0x29/0x70 [<ffffffff816385f9>] schedule_timeout+0x209/0x2d0 [<ffffffff8108e4cd>] ? mod_timer+0x11d/0x240 [<ffffffff8163acd6>] wait_for_completion+0x116/0x170 [<ffffffff810b8c10>] ? wake_up_state+0x20/0x20 [<ffffffff810ab676>] __synchronize_srcu+0x106/0x1a0 [<ffffffff810ab190>] ? call_srcu+0x70/0x70 [<ffffffff81219ebf>] ? __sync_blockdev+0x1f/0x40 [<ffffffff810ab72d>] synchronize_srcu+0x1d/0x20 [<ffffffffa000318d>] __dm_suspend+0x5d/0x220 [dm_mod] [<ffffffffa0004c9a>] dm_suspend+0xca/0xf0 [dm_mod] [<ffffffffa0009fe0>] ? table_load+0x380/0x380 [dm_mod] [<ffffffffa000a174>] dev_suspend+0x194/0x250 [dm_mod] [<ffffffffa0009fe0>] ? table_load+0x380/0x380 [dm_mod] [<ffffffffa000aa25>] ctl_ioctl+0x255/0x500 [dm_mod] [<ffffffffa000ace3>] dm_ctl_ioctl+0x13/0x20 [dm_mod] [<ffffffff811f1ef5>] do_vfs_ioctl+0x2e5/0x4c0 [<ffffffff8128bc6e>] ? file_has_perm+0xae/0xc0 [<ffffffff811f2171>] SyS_ioctl+0xa1/0xc0 [<ffffffff816408d9>] ? do_async_page_fault+0x29/0xe0 [<ffffffff81645909>] system_call_fastpath+0x16/0x1bWhich led to this redhat article but the answer to that is locked. More debugging led to answers like this and this. The final answer was found here:
sudo sysctl -w vm.dirty_ratio=10 sudo sysctl -w vm.dirty_background_ratio=5With the explanation "By default Linux uses up to 40% of the available memory for file system caching. After this mark has been reached the file system flushes all outstanding data to disk causing all following IOs going synchronous. For flushing out this data to disk this there is a time limit of 120 seconds by default. In the case here the IO subsystem is not fast enough to flush the data withing". Crazy
After we put those settings, it actually worked (!). Still cannot believe that choosing AWS instance is that important.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login