Backups frequently crashing lately - "reason":"Internal Error"
-
The last week or so I've noticed the backups are crashing about 25% of the time, and then most times when invoking the backup manually it works fine again. I've bumped up the backup memory from 4 GB to 6 GB and still see the issues, doesn't seem like the frequency of the issue has gone down at all. The memory (heap) used in the logs seems like there's plenty left, unless I'm reading it incorrectly. If it's memory though, why is it needing more than 2 GB memory increase when it's been very reliable up until the past week or so, without any real changes made in the last week (no new apps or anything like that)?
Any ideas why this may be happening? Logs are below:
Jun 12 08:17:18 box:shell backup-snapshot/box (stdout): 2021-06-12T15:17:18.570Z box:backupupload v8 heap : used 72767888 total: 114642944 max: 5704253440 Jun 12 08:17:19 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9301M@14MBps (box)"} Jun 12 08:17:29 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9457M@14MBps (box)"} Jun 12 08:17:39 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9619M@14MBps (box)"} Jun 12 08:17:48 box:shell backup-snapshot/box (stdout): 2021-06-12T15:17:48.569Z box:backupupload process: rss: 958672896 heapTotal: 110710784 heapUsed: 71391640 external: 298550073 Jun 12 08:17:48 box:shell backup-snapshot/box (stdout): 2021-06-12T15:17:48.569Z box:backupupload v8 heap : used 71397072 total: 110710784 max: 5704253440 Jun 12 08:17:49 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9762M@14MBps (box)"} Jun 12 08:17:59 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9915M@14MBps (box)"} Jun 12 08:18:07 box:shell backup-snapshot/box code: null, signal: SIGKILL Jun 12 08:18:07 box:taskworker Task took 1086.741 seconds Jun 12 08:18:07 box:tasks setCompleted - 10692: {"result":null,"error":{"stack":"BoxError: Backuptask crashed\n at /home/yellowtent/box/src/backups.js:895:29\n at f (/home/yellowtent/box/node_modules/once/once.js:25:25)\n at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:69:9)\n at ChildProcess.emit (events.js:315:20)\n at ChildProcess.EventEmitter.emit (domain.js:467:12)\n at Process.ChildProcess._handle.onexit (internal/child_process.js:277:12)","name":"BoxError","reason":"Internal Error","details":{},"message":"Backuptask crashed"}} Jun 12 08:18:07 box:tasks 10692: {"percent":100,"result":null,"error":{"stack":"BoxError: Backuptask crashed\n at /home/yellowtent/box/src/backups.js:895:29\n at f (/home/yellowtent/box/node_modules/once/once.js:25:25)\n at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:69:9)\n at ChildProcess.emit (events.js:315:20)\n at ChildProcess.EventEmitter.emit (domain.js:467:12)\n at Process.ChildProcess._handle.onexit (internal/child_process.js:277:12)","name":"BoxError","reason":"Internal Error","details":{},"message":"Backuptask crashed"}}Any help would be appreciated. I'm going to be away tomorrow until Tuesday afternoon so hopefully the backups will be okay in my absence as I won't have internet access.

--
Dustin Dauncey
www.d19.ca -
The last week or so I've noticed the backups are crashing about 25% of the time, and then most times when invoking the backup manually it works fine again. I've bumped up the backup memory from 4 GB to 6 GB and still see the issues, doesn't seem like the frequency of the issue has gone down at all. The memory (heap) used in the logs seems like there's plenty left, unless I'm reading it incorrectly. If it's memory though, why is it needing more than 2 GB memory increase when it's been very reliable up until the past week or so, without any real changes made in the last week (no new apps or anything like that)?
Any ideas why this may be happening? Logs are below:
Jun 12 08:17:18 box:shell backup-snapshot/box (stdout): 2021-06-12T15:17:18.570Z box:backupupload v8 heap : used 72767888 total: 114642944 max: 5704253440 Jun 12 08:17:19 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9301M@14MBps (box)"} Jun 12 08:17:29 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9457M@14MBps (box)"} Jun 12 08:17:39 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9619M@14MBps (box)"} Jun 12 08:17:48 box:shell backup-snapshot/box (stdout): 2021-06-12T15:17:48.569Z box:backupupload process: rss: 958672896 heapTotal: 110710784 heapUsed: 71391640 external: 298550073 Jun 12 08:17:48 box:shell backup-snapshot/box (stdout): 2021-06-12T15:17:48.569Z box:backupupload v8 heap : used 71397072 total: 110710784 max: 5704253440 Jun 12 08:17:49 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9762M@14MBps (box)"} Jun 12 08:17:59 box:tasks 10692: {"percent":98.36842105263167,"message":"Uploading backup 9915M@14MBps (box)"} Jun 12 08:18:07 box:shell backup-snapshot/box code: null, signal: SIGKILL Jun 12 08:18:07 box:taskworker Task took 1086.741 seconds Jun 12 08:18:07 box:tasks setCompleted - 10692: {"result":null,"error":{"stack":"BoxError: Backuptask crashed\n at /home/yellowtent/box/src/backups.js:895:29\n at f (/home/yellowtent/box/node_modules/once/once.js:25:25)\n at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:69:9)\n at ChildProcess.emit (events.js:315:20)\n at ChildProcess.EventEmitter.emit (domain.js:467:12)\n at Process.ChildProcess._handle.onexit (internal/child_process.js:277:12)","name":"BoxError","reason":"Internal Error","details":{},"message":"Backuptask crashed"}} Jun 12 08:18:07 box:tasks 10692: {"percent":100,"result":null,"error":{"stack":"BoxError: Backuptask crashed\n at /home/yellowtent/box/src/backups.js:895:29\n at f (/home/yellowtent/box/node_modules/once/once.js:25:25)\n at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:69:9)\n at ChildProcess.emit (events.js:315:20)\n at ChildProcess.EventEmitter.emit (domain.js:467:12)\n at Process.ChildProcess._handle.onexit (internal/child_process.js:277:12)","name":"BoxError","reason":"Internal Error","details":{},"message":"Backuptask crashed"}}Any help would be appreciated. I'm going to be away tomorrow until Tuesday afternoon so hopefully the backups will be okay in my absence as I won't have internet access.
@d19dotca hm since you seem to be receiving SIGKILL signal, this may be that the system as a whole runs out of memory and the kernel starts killing processes to still be able to function.
Checksudo journalctl --systemto get more info why SIGKILL was triggered. -
@d19dotca hm since you seem to be receiving SIGKILL signal, this may be that the system as a whole runs out of memory and the kernel starts killing processes to still be able to function.
Checksudo journalctl --systemto get more info why SIGKILL was triggered.@nebulon said in Backups frequently crashing lately - "reason":"Internal Error":
sudo journalctl --system
I noticed the following when searching that command for
mysqlsince I've had my eye on what appear to be multiple mysql processes running for mysql:$ sudo journalctl --system | grep mysql Jun 15 15:17:08 my kernel: mysqld invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 Jun 15 15:17:08 my kernel: CPU: 1 PID: 3208437 Comm: mysqld Not tainted 5.4.0-74-generic #83-Ubuntu Jun 15 15:17:08 my kernel: [3208414] 112 3208414 523222 51792 933888 8595 0 mysqld Jun 15 15:17:08 my kernel: [2845320] 107 2845320 546273 200311 2052096 0 0 mysqld Jun 15 15:17:08 my kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/docker/7891541a56374e19c56f6829d9452f210d8446a629fa792c20c9d9db30d36a62,task=mysqld,pid=2845320,uid=107 Jun 15 15:17:08 my kernel: Out of memory: Killed process 2845320 (mysqld) total-vm:2185092kB, anon-rss:801244kB, file-rss:0kB, shmem-rss:0kB, UID:107 pgtables:2004kB oom_score_adj:0 Jun 15 15:17:08 my kernel: oom_reaper: reaped process 2845320 (mysqld), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kBSo it seems there was indeed an OOM error on the 15th. This also happens to be around the time of the backup which I received a backup failure notification most recently. I backup every day at 8 AM and 8 PM, and 8 AM Pacific Time is 15:00 UTC.
Any suggestions
-
There's also this at that time stamp which appears related:
Jun 15 15:17:08 my kernel: mysqld invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 Jun 15 15:17:08 my kernel: CPU: 1 PID: 3208437 Comm: mysqld Not tainted 5.4.0-74-generic #83-Ubuntu Jun 15 15:17:08 my kernel: Hardware name: Vultr HFC, BIOS Jun 15 15:17:08 my kernel: Call Trace: Jun 15 15:17:08 my kernel: dump_stack+0x6d/0x8b Jun 15 15:17:08 my kernel: dump_header+0x4f/0x1eb Jun 15 15:17:08 my kernel: oom_kill_process.cold+0xb/0x10 Jun 15 15:17:08 my kernel: out_of_memory.part.0+0x1df/0x3d0 Jun 15 15:17:08 my kernel: out_of_memory+0x6d/0xd0 Jun 15 15:17:08 my kernel: __alloc_pages_slowpath+0xd5e/0xe50 Jun 15 15:17:08 my kernel: __alloc_pages_nodemask+0x2d0/0x320 Jun 15 15:17:08 my kernel: alloc_pages_current+0x87/0xe0 Jun 15 15:17:08 my kernel: __page_cache_alloc+0x72/0x90 Jun 15 15:17:08 my kernel: pagecache_get_page+0xbf/0x300 Jun 15 15:17:08 my kernel: filemap_fault+0x6b2/0xa50 Jun 15 15:17:08 my kernel: ? unlock_page_memcg+0x12/0x20 Jun 15 15:17:08 my kernel: ? page_add_file_rmap+0xff/0x1a0 Jun 15 15:17:08 my kernel: ? xas_find+0x143/0x1c0 Jun 15 15:17:08 my kernel: ? xas_load+0xd/0x80 Jun 15 15:17:08 my kernel: ? xas_find+0x17f/0x1c0 Jun 15 15:17:08 my kernel: ? filemap_map_pages+0x24c/0x380 Jun 15 15:17:08 my kernel: ext4_filemap_fault+0x32/0x50 Jun 15 15:17:08 my kernel: __do_fault+0x3c/0x130 Jun 15 15:17:08 my kernel: do_fault+0x24b/0x640 Jun 15 15:17:08 my kernel: __handle_mm_fault+0x4c5/0x7a0 Jun 15 15:17:08 my kernel: handle_mm_fault+0xca/0x200 Jun 15 15:17:08 my kernel: do_user_addr_fault+0x1f9/0x450 Jun 15 15:17:08 my kernel: __do_page_fault+0x58/0x90 Jun 15 15:17:08 my kernel: ? __x64_sys_clock_nanosleep+0xc6/0x130 Jun 15 15:17:08 my kernel: do_page_fault+0x2c/0xe0 Jun 15 15:17:08 my kernel: do_async_page_fault+0x39/0x70 Jun 15 15:17:08 my kernel: async_page_fault+0x34/0x40 Jun 15 15:17:08 my kernel: RIP: 0033:0x55ba68ab8bd0 Jun 15 15:17:08 my kernel: Code: Bad RIP value. Jun 15 15:17:08 my kernel: RSP: 002b:00007f326e53dce8 EFLAGS: 00010297 Jun 15 15:17:08 my kernel: RAX: 0000000000000000 RBX: 000055ba6a211c30 RCX: 0000000000000000 Jun 15 15:17:08 my kernel: RDX: 000000a98cc45ffe RSI: 000000001557995c RDI: 0000000000000001 Jun 15 15:17:08 my kernel: RBP: 00007f326e53dd60 R08: 00007fffdc183090 R09: 00007f326e53dcb8 Jun 15 15:17:08 my kernel: R10: 00007f326e53dcb0 R11: 00000000000b1c93 R12: 000055ba6a5fec60 Jun 15 15:17:08 my kernel: R13: 0000000000221dcd R14: 000055ba6a618840 R15: 000000a98cc45ffe Jun 15 15:17:08 my kernel: Mem-Info: Jun 15 15:17:08 my kernel: active_anon:827554 inactive_anon:988487 isolated_anon:0 Jun 15 15:17:08 my kernel: Node 0 active_anon:3310216kB inactive_anon:3953948kB active_file:1552kB inactive_file:1616kB unevictable:18536kB isolated(anon):0kB isolated(file):164kB mapped:738452kB dirty:0kB writeback:0kB shmem:1322856kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB unstable:0kB all_unreclaimable? no Jun 15 15:17:08 my kernel: Node 0 DMA free:15900kB min:132kB low:164kB high:196kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15908kB mlocked:0kB kernel_stack:0kB pagetables:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Jun 15 15:17:08 my kernel: lowmem_reserve[]: 0 2912 7859 7859 7859 Jun 15 15:17:08 my kernel: Node 0 DMA32 free:44604kB min:24996kB low:31244kB high:37492kB active_anon:1403704kB inactive_anon:1377064kB active_file:424kB inactive_file:568kB unevictable:0kB writepending:0kB present:3129200kB managed:3063664kB mlocked:0kB kernel_stack:9772kB pagetables:31576kB bounce:0kB free_pcp:1252kB local_pcp:540kB free_cma:0kB Jun 15 15:17:08 my kernel: lowmem_reserve[]: 0 0 4946 4946 4946 Jun 15 15:17:08 my kernel: Node 0 Normal free:42164kB min:42452kB low:53064kB high:63676kB active_anon:1906512kB inactive_anon:2576884kB active_file:1088kB inactive_file:1300kB unevictable:18536kB writepending:0kB present:5242880kB managed:5073376kB mlocked:18536kB kernel_stack:29876kB pagetables:56760kB bounce:0kB free_pcp:3284kB local_pcp:1036kB free_cma:0kB Jun 15 15:17:08 my kernel: lowmem_reserve[]: 0 0 0 0 0 Jun 15 15:17:08 my kernel: Node 0 DMA: 1*4kB (U) 1*8kB (U) 1*16kB (U) 0*32kB 2*64kB (U) 1*128kB (U) 1*256kB (U) 0*512kB 1*1024kB (U) 1*2048kB (M) 3*4096kB (M) = 15900kB Jun 15 15:17:08 my kernel: Node 0 DMA32: 148*4kB (UMEH) 639*8kB (UMEH) 1599*16kB (UEH) 416*32kB (UEH) 2*64kB (H) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 44728kB Jun 15 15:17:08 my kernel: Node 0 Normal: 3836*4kB (UMEH) 1802*8kB (UMEH) 483*16kB (UMEH) 137*32kB (UMEH) 9*64kB (UE) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 42448kB Jun 15 15:17:08 my kernel: Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB Jun 15 15:17:08 my kernel: 381652 total pagecache pages Jun 15 15:17:08 my kernel: 48101 pages in swap cache Jun 15 15:17:08 my kernel: Swap cache stats: add 569228, delete 521127, find 77806133/77924760 Jun 15 15:17:08 my kernel: Free swap = 0kB Jun 15 15:17:08 my kernel: Total swap = 1004540kB Jun 15 15:17:08 my kernel: 2097018 pages RAM Jun 15 15:17:08 my kernel: 0 pages HighMem/MovableOnly Jun 15 15:17:08 my kernel: 58781 pages reserved Jun 15 15:17:08 my kernel: 0 pages cma reserved Jun 15 15:17:08 my kernel: 0 pages hwpoisoned Jun 15 15:17:08 my kernel: Tasks state (memory values in pages):[... bunch of services listed but hiding them here because the overall text is too long to be posted in the forum, the forum blocks me from posting it]
Jun 15 15:17:08 my kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/docker/7891541a56374e19c56f6829d9452f210d8446a629fa792c20c9d9db30d36a62,task=mysqld,pid=2845320,uid=107 Jun 15 15:17:08 my kernel: Out of memory: Killed process 2845320 (mysqld) total-vm:2185092kB, anon-rss:801244kB, file-rss:0kB, shmem-rss:0kB, UID:107 pgtables:2004kB oom_score_adj:0 Jun 15 15:17:08 my kernel: oom_reaper: reaped process 2845320 (mysqld), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB--
Dustin Dauncey
www.d19.ca -
There's also this at that time stamp which appears related:
Jun 15 15:17:08 my kernel: mysqld invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 Jun 15 15:17:08 my kernel: CPU: 1 PID: 3208437 Comm: mysqld Not tainted 5.4.0-74-generic #83-Ubuntu Jun 15 15:17:08 my kernel: Hardware name: Vultr HFC, BIOS Jun 15 15:17:08 my kernel: Call Trace: Jun 15 15:17:08 my kernel: dump_stack+0x6d/0x8b Jun 15 15:17:08 my kernel: dump_header+0x4f/0x1eb Jun 15 15:17:08 my kernel: oom_kill_process.cold+0xb/0x10 Jun 15 15:17:08 my kernel: out_of_memory.part.0+0x1df/0x3d0 Jun 15 15:17:08 my kernel: out_of_memory+0x6d/0xd0 Jun 15 15:17:08 my kernel: __alloc_pages_slowpath+0xd5e/0xe50 Jun 15 15:17:08 my kernel: __alloc_pages_nodemask+0x2d0/0x320 Jun 15 15:17:08 my kernel: alloc_pages_current+0x87/0xe0 Jun 15 15:17:08 my kernel: __page_cache_alloc+0x72/0x90 Jun 15 15:17:08 my kernel: pagecache_get_page+0xbf/0x300 Jun 15 15:17:08 my kernel: filemap_fault+0x6b2/0xa50 Jun 15 15:17:08 my kernel: ? unlock_page_memcg+0x12/0x20 Jun 15 15:17:08 my kernel: ? page_add_file_rmap+0xff/0x1a0 Jun 15 15:17:08 my kernel: ? xas_find+0x143/0x1c0 Jun 15 15:17:08 my kernel: ? xas_load+0xd/0x80 Jun 15 15:17:08 my kernel: ? xas_find+0x17f/0x1c0 Jun 15 15:17:08 my kernel: ? filemap_map_pages+0x24c/0x380 Jun 15 15:17:08 my kernel: ext4_filemap_fault+0x32/0x50 Jun 15 15:17:08 my kernel: __do_fault+0x3c/0x130 Jun 15 15:17:08 my kernel: do_fault+0x24b/0x640 Jun 15 15:17:08 my kernel: __handle_mm_fault+0x4c5/0x7a0 Jun 15 15:17:08 my kernel: handle_mm_fault+0xca/0x200 Jun 15 15:17:08 my kernel: do_user_addr_fault+0x1f9/0x450 Jun 15 15:17:08 my kernel: __do_page_fault+0x58/0x90 Jun 15 15:17:08 my kernel: ? __x64_sys_clock_nanosleep+0xc6/0x130 Jun 15 15:17:08 my kernel: do_page_fault+0x2c/0xe0 Jun 15 15:17:08 my kernel: do_async_page_fault+0x39/0x70 Jun 15 15:17:08 my kernel: async_page_fault+0x34/0x40 Jun 15 15:17:08 my kernel: RIP: 0033:0x55ba68ab8bd0 Jun 15 15:17:08 my kernel: Code: Bad RIP value. Jun 15 15:17:08 my kernel: RSP: 002b:00007f326e53dce8 EFLAGS: 00010297 Jun 15 15:17:08 my kernel: RAX: 0000000000000000 RBX: 000055ba6a211c30 RCX: 0000000000000000 Jun 15 15:17:08 my kernel: RDX: 000000a98cc45ffe RSI: 000000001557995c RDI: 0000000000000001 Jun 15 15:17:08 my kernel: RBP: 00007f326e53dd60 R08: 00007fffdc183090 R09: 00007f326e53dcb8 Jun 15 15:17:08 my kernel: R10: 00007f326e53dcb0 R11: 00000000000b1c93 R12: 000055ba6a5fec60 Jun 15 15:17:08 my kernel: R13: 0000000000221dcd R14: 000055ba6a618840 R15: 000000a98cc45ffe Jun 15 15:17:08 my kernel: Mem-Info: Jun 15 15:17:08 my kernel: active_anon:827554 inactive_anon:988487 isolated_anon:0 Jun 15 15:17:08 my kernel: Node 0 active_anon:3310216kB inactive_anon:3953948kB active_file:1552kB inactive_file:1616kB unevictable:18536kB isolated(anon):0kB isolated(file):164kB mapped:738452kB dirty:0kB writeback:0kB shmem:1322856kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB unstable:0kB all_unreclaimable? no Jun 15 15:17:08 my kernel: Node 0 DMA free:15900kB min:132kB low:164kB high:196kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15908kB mlocked:0kB kernel_stack:0kB pagetables:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Jun 15 15:17:08 my kernel: lowmem_reserve[]: 0 2912 7859 7859 7859 Jun 15 15:17:08 my kernel: Node 0 DMA32 free:44604kB min:24996kB low:31244kB high:37492kB active_anon:1403704kB inactive_anon:1377064kB active_file:424kB inactive_file:568kB unevictable:0kB writepending:0kB present:3129200kB managed:3063664kB mlocked:0kB kernel_stack:9772kB pagetables:31576kB bounce:0kB free_pcp:1252kB local_pcp:540kB free_cma:0kB Jun 15 15:17:08 my kernel: lowmem_reserve[]: 0 0 4946 4946 4946 Jun 15 15:17:08 my kernel: Node 0 Normal free:42164kB min:42452kB low:53064kB high:63676kB active_anon:1906512kB inactive_anon:2576884kB active_file:1088kB inactive_file:1300kB unevictable:18536kB writepending:0kB present:5242880kB managed:5073376kB mlocked:18536kB kernel_stack:29876kB pagetables:56760kB bounce:0kB free_pcp:3284kB local_pcp:1036kB free_cma:0kB Jun 15 15:17:08 my kernel: lowmem_reserve[]: 0 0 0 0 0 Jun 15 15:17:08 my kernel: Node 0 DMA: 1*4kB (U) 1*8kB (U) 1*16kB (U) 0*32kB 2*64kB (U) 1*128kB (U) 1*256kB (U) 0*512kB 1*1024kB (U) 1*2048kB (M) 3*4096kB (M) = 15900kB Jun 15 15:17:08 my kernel: Node 0 DMA32: 148*4kB (UMEH) 639*8kB (UMEH) 1599*16kB (UEH) 416*32kB (UEH) 2*64kB (H) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 44728kB Jun 15 15:17:08 my kernel: Node 0 Normal: 3836*4kB (UMEH) 1802*8kB (UMEH) 483*16kB (UMEH) 137*32kB (UMEH) 9*64kB (UE) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 42448kB Jun 15 15:17:08 my kernel: Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB Jun 15 15:17:08 my kernel: 381652 total pagecache pages Jun 15 15:17:08 my kernel: 48101 pages in swap cache Jun 15 15:17:08 my kernel: Swap cache stats: add 569228, delete 521127, find 77806133/77924760 Jun 15 15:17:08 my kernel: Free swap = 0kB Jun 15 15:17:08 my kernel: Total swap = 1004540kB Jun 15 15:17:08 my kernel: 2097018 pages RAM Jun 15 15:17:08 my kernel: 0 pages HighMem/MovableOnly Jun 15 15:17:08 my kernel: 58781 pages reserved Jun 15 15:17:08 my kernel: 0 pages cma reserved Jun 15 15:17:08 my kernel: 0 pages hwpoisoned Jun 15 15:17:08 my kernel: Tasks state (memory values in pages):[... bunch of services listed but hiding them here because the overall text is too long to be posted in the forum, the forum blocks me from posting it]
Jun 15 15:17:08 my kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/docker/7891541a56374e19c56f6829d9452f210d8446a629fa792c20c9d9db30d36a62,task=mysqld,pid=2845320,uid=107 Jun 15 15:17:08 my kernel: Out of memory: Killed process 2845320 (mysqld) total-vm:2185092kB, anon-rss:801244kB, file-rss:0kB, shmem-rss:0kB, UID:107 pgtables:2004kB oom_score_adj:0 Jun 15 15:17:08 my kernel: oom_reaper: reaped process 2845320 (mysqld), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB@d19dotca looks like the system simply runs out of memory and then kills in this case the mysql service. Generally linux will kill a bit at random in such occasions to keep the overall system at least up.
In your case the system itself runs out of memory, regardless what you have set within Cloudron as constraints. The only quick fix is to give the system more physical memory or constrain apps on the system if possible through the Cloudron dashboard. The backup tasks unfortunately always put strain on the whole system in spikes.
-
@d19dotca looks like the system simply runs out of memory and then kills in this case the mysql service. Generally linux will kill a bit at random in such occasions to keep the overall system at least up.
In your case the system itself runs out of memory, regardless what you have set within Cloudron as constraints. The only quick fix is to give the system more physical memory or constrain apps on the system if possible through the Cloudron dashboard. The backup tasks unfortunately always put strain on the whole system in spikes.
@nebulon Hmm, odd. I mean I agree because I'm definitely seeing OOM messages, it's just strange to be because I had a system that had 15 GB of memory earlier, and moved to a Vultr HF system with 8 GB of memory, but that's because I was only ever using at most 5.5 GB to 6 GB of memory on the previous server. When I look at the
freeoutput, I see this currently (keep in mind I rebooted this server about 10 hours ago last night):free -h total used free shared buff/cache available Mem: 7.8Gi 4.7Gi 713Mi 1.2Gi 2.4Gi 1.7Gi Swap: 980Mi 611Mi 369MiWhen I had seen it before though the used column for mem was around 5.8 or 6 GB, with about 1 GB available and a couple GB in buff/cache.
Is it possible this is related to this? I have found when searching for most memory consuming processes, I see mysql service running twice, I think one is the system Mysql and the other is the container Cloudron mysql:
top - 16:00:10 up 9:33, 1 user, load average: 1.87, 1.39, 1.37 Tasks: 597 total, 1 running, 596 sleeping, 0 stopped, 0 zombie %Cpu(s): 32.5 us, 13.3 sy, 0.0 ni, 51.5 id, 0.9 wa, 0.0 hi, 1.8 si, 0.0 st MiB Mem : 7961.9 total, 609.2 free, 4790.5 used, 2562.2 buff/cache MiB Swap: 981.0 total, 369.5 free, 611.5 used. 1689.7 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12397 107 20 0 2102888 702920 15400 S 12.3 8.6 9:37.08 mysqld 16340 yellowt+ 20 0 1129500 274684 7052 S 0.3 3.4 0:16.30 ruby2.7 16339 yellowt+ 20 0 1129500 269572 6376 S 1.3 3.3 0:13.81 ruby2.7 15539 yellowt+ 20 0 407068 213124 8592 S 0.3 2.6 0:37.18 ruby2.7 15538 yellowt+ 20 0 453524 204424 9188 S 0.0 2.5 0:07.67 ruby2.7 741 mysql 20 0 2091000 145968 7792 S 2.3 1.8 2:55.45 mysqld 16575 yellowt+ 20 0 10.9g 113880 14364 S 1.0 1.4 0:49.92 node 792858 www-data 20 0 387836 113620 86300 S 4.3 1.4 0:02.37 /usr/sbin/apach 12441 d19dotca 20 0 1735140 107084 8228 S 2.0 1.3 7:35.25 gitea 783769 www-data 20 0 387664 106884 80312 S 4.0 1.3 0:01.54 /usr/sbin/apach 798528 www-data 20 0 375736 103844 88708 S 0.0 1.3 0:02.40 /usr/sbin/apach 788798 www-data 20 0 375344 102656 87908 S 0.0 1.3 0:02.28 /usr/sbin/apach 785412 www-data 20 0 375832 101188 86132 S 0.0 1.2 0:03.25 /usr/sbin/apach 792899 www-data 20 0 386972 100312 73128 S 13.0 1.2 0:03.37 /usr/sbin/apach 12574 yellowt+ 20 0 112904 99640 6400 S 0.0 1.2 0:15.71 spamd child 806155 www-data 20 0 386616 99132 72180 S 11.0 1.2 0:02.18 /usr/sbin/apach 780713 www-data 20 0 381024 96296 77424 S 2.3 1.2 0:02.13 /usr/sbin/apach 801099 www-data 20 0 388996 95872 66616 S 12.6 1.2 0:02.59 /usr/sbin/apach 772941 www-data 20 0 381084 94500 73932 S 3.0 1.2 0:02.49 /usr/sbin/apach 792901 www-data 20 0 377220 94468 77340 S 0.0 1.2 0:01.98 /usr/sbin/apach 758844 www-data 20 0 381120 93600 72176 S 2.0 1.1 0:02.18 /usr/sbin/apach 778111 www-data 20 0 374936 92216 77248 S 0.0 1.1 0:01.81 /usr/sbin/apach(remember, UID
107is the main user for each of the Cloudron containers)The container MySQL is consuming around 700 MB of physical memory, while the main mysql service is consuming around 145 MB, so roughly 1 GB total is consumed by MySQL currently. Should there be multiple instances of MySQL running though on Ubuntu? I feel like there always was but I can't be certain of that at the moment.
I guess I can temporarily reduce the memory limits on various apps and services, but I'd prefer not to if I can help it. I agree it's memory related, but I guess I don't quite get why this is an issue when there's no real difference to how I was running my current Cloudron than I was on the last server which had more memory but never used much more than 5-6 GB of memory at a time. I suppose I could also just reduce the memory for the backup process? Maybe that'll be the easier workaround for now. Thoughts though on why memory seems to be an issue at the moment based on that top output for example?
-
Side note: Just so I'm sure of what's going on, I noticed when I start a backup process (just testing right now), I see the root node service go crazy high in memory but sporadically, it keeps changing from around 300 MB in physical memory to just under 900 MB in physical memory. This is because of the backup process, right?
top - 16:08:33 up 9:42, 1 user, load average: 2.65, 2.07, 1.66 Tasks: 597 total, 1 running, 596 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.7 us, 6.1 sy, 32.5 ni, 59.1 id, 0.2 wa, 0.0 hi, 1.3 si, 0.1 st MiB Mem : 7961.9 total, 124.0 free, 5531.6 used, 2306.2 buff/cache MiB Swap: 981.0 total, 228.0 free, 753.0 used. 956.4 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 823023 root 35 15 1737404 893500 24260 S 118.3 11.0 1:41.76 node 12397 107 20 0 2102888 696664 12424 S 0.3 8.5 9:49.96 mysqld 16340 yellowt+ 20 0 1129500 255608 3544 S 0.0 3.1 0:16.42 ruby2.7 16339 yellowt+ 20 0 1129500 253392 7048 S 0.0 3.1 0:14.00 ruby2.7 15539 yellowt+ 20 0 407068 185000 4676 S 0.0 2.3 0:37.64 ruby2.7 15538 yellowt+ 20 0 453524 177680 5332 S 0.0 2.2 0:07.70 ruby2.7 741 mysql 20 0 2092024 130360 5316 S 0.3 1.6 3:03.02 mysqld 16575 yellowt+ 20 0 10.9g 109224 11820 S 0.0 1.3 0:50.66 node -
Can you check how much memory you are giving the backup task? This is in advanced settings of the backup configuration.
The default would be 400Mb and it will use that amount, since there a fair amount of data piping happening, especially if disk and network I/O are good.
-
Can you check how much memory you are giving the backup task? This is in advanced settings of the backup configuration.
The default would be 400Mb and it will use that amount, since there a fair amount of data piping happening, especially if disk and network I/O are good.
@nebulon said in Backups frequently crashing lately - "reason":"Internal Error":
The default would be 400Mb and it will use that amount, since there a fair amount of data piping happening, especially if disk and network I/O are good.
Well since I thought it was the memory for the backup task initially which has been an issue in the past for many users, I had increased it to 6 GB of memory (which is admittedly a lot on an 8 GB server), but I had it initially at 4 GB when I was seeing the issue. I've had it at 4 GB for many months though. I've lowered it to 2 GB for the moment to test and see if that helps at all, but I'm worried the trigger was mysqldump commands and I'm not sure if the backup task memory would impact that at all.
This is the current configuration as of this morning for troubleshooting purposes:
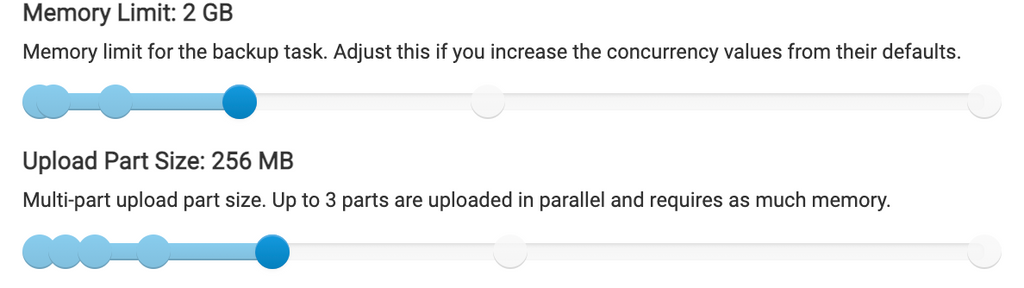
-
Just encountered the issue again.

Here are the latest logs:
Jun 17 03:13:17 my kernel: redis-server invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 Jun 17 03:13:17 my kernel: CPU: 1 PID: 6436 Comm: redis-server Not tainted 5.4.0-74-generic #83-Ubuntu Jun 17 03:13:17 my kernel: Hardware name: Vultr HFC, BIOS Jun 17 03:13:17 my kernel: Call Trace: Jun 17 03:13:17 my kernel: dump_stack+0x6d/0x8b Jun 17 03:13:17 my kernel: dump_header+0x4f/0x1eb Jun 17 03:13:17 my kernel: oom_kill_process.cold+0xb/0x10 Jun 17 03:13:17 my kernel: out_of_memory.part.0+0x1df/0x3d0 Jun 17 03:13:17 my kernel: out_of_memory+0x6d/0xd0 Jun 17 03:13:17 my kernel: __alloc_pages_slowpath+0xd5e/0xe50 Jun 17 03:13:17 my kernel: __alloc_pages_nodemask+0x2d0/0x320 Jun 17 03:13:17 my kernel: alloc_pages_current+0x87/0xe0 Jun 17 03:13:17 my kernel: __page_cache_alloc+0x72/0x90 Jun 17 03:13:17 my kernel: pagecache_get_page+0xbf/0x300 Jun 17 03:13:17 my kernel: filemap_fault+0x6b2/0xa50 Jun 17 03:13:17 my kernel: ? unlock_page_memcg+0x12/0x20 Jun 17 03:13:17 my kernel: ? page_add_file_rmap+0xff/0x1a0 Jun 17 03:13:17 my kernel: ? xas_load+0xd/0x80 Jun 17 03:13:17 my kernel: ? xas_find+0x17f/0x1c0 Jun 17 03:13:17 my kernel: ? filemap_map_pages+0x24c/0x380 Jun 17 03:13:17 my kernel: ext4_filemap_fault+0x32/0x50 Jun 17 03:13:17 my kernel: __do_fault+0x3c/0x130 Jun 17 03:13:17 my kernel: do_fault+0x24b/0x640 Jun 17 03:13:17 my kernel: __handle_mm_fault+0x4c5/0x7a0 Jun 17 03:13:17 my kernel: handle_mm_fault+0xca/0x200 Jun 17 03:13:17 my kernel: do_user_addr_fault+0x1f9/0x450 Jun 17 03:13:17 my kernel: __do_page_fault+0x58/0x90 Jun 17 03:13:17 my kernel: do_page_fault+0x2c/0xe0 Jun 17 03:13:17 my kernel: do_async_page_fault+0x39/0x70 Jun 17 03:13:17 my kernel: async_page_fault+0x34/0x40 Jun 17 03:13:17 my kernel: RIP: 0033:0x5642ded5def4 Jun 17 03:13:17 my kernel: Code: Bad RIP value. Jun 17 03:13:17 my kernel: RSP: 002b:00007ffe39d1f480 EFLAGS: 00010293 Jun 17 03:13:17 my kernel: RAX: 0000000000000001 RBX: 0000000000000000 RCX: 00005642dedb5a14 Jun 17 03:13:17 my kernel: RDX: 0000000000000001 RSI: 00007f6c13408823 RDI: 0000000000000002 Jun 17 03:13:17 my kernel: RBP: 0000000000000000 R08: 0000000000000000 R09: 00007ffe39d1f3d8 Jun 17 03:13:17 my kernel: R10: 00007ffe39d1f3d0 R11: 0000000000000000 R12: 00007ffe39d1f648 Jun 17 03:13:17 my kernel: R13: 0000000000000002 R14: 00007f6c1341f020 R15: 0000000000000000 Jun 17 03:13:17 my kernel: Mem-Info: Jun 17 03:13:17 my kernel: active_anon:961079 inactive_anon:871527 isolated_anon:0 Jun 17 03:13:17 my kernel: Node 0 active_anon:3844316kB inactive_anon:3486108kB active_file:624kB inactive_file:464kB unevictable:18540kB isolated(anon):0kB isolated(file):20kB mapped:900656kB dirty:0kB writeback:0kB shmem:1207700kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB unstable:0kB all_unreclaimable? no Jun 17 03:13:17 my kernel: Node 0 DMA free:15900kB min:132kB low:164kB high:196kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15908kB mlocked:0kB kernel_stack:0kB pagetables:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Jun 17 03:13:17 my kernel: lowmem_reserve[]: 0 2911 7858 7858 7858 Jun 17 03:13:17 my kernel: Node 0 DMA32 free:44284kB min:24988kB low:31232kB high:37476kB active_anon:1420788kB inactive_anon:1398328kB active_file:0kB inactive_file:360kB unevictable:0kB writepending:0kB present:3129200kB managed:3063664kB mlocked:0kB kernel_stack:9504kB pagetables:29712kB bounce:0kB free_pcp:1560kB local_pcp:540kB free_cma:0kB Jun 17 03:13:17 my kernel: lowmem_reserve[]: 0 0 4946 4946 4946 Jun 17 03:13:17 my kernel: Node 0 Normal free:42004kB min:42460kB low:53072kB high:63684kB active_anon:2423528kB inactive_anon:2087780kB active_file:588kB inactive_file:808kB unevictable:18540kB writepending:0kB present:5242880kB managed:5073392kB mlocked:18540kB kernel_stack:29040kB pagetables:53096kB bounce:0kB free_pcp:3512kB local_pcp:676kB free_cma:0kB Jun 17 03:13:17 my kernel: lowmem_reserve[]: 0 0 0 0 0 Jun 17 03:13:17 my kernel: Node 0 DMA: 1*4kB (U) 1*8kB (U) 1*16kB (U) 0*32kB 2*64kB (U) 1*128kB (U) 1*256kB (U) 0*512kB 1*1024kB (U) 1*2048kB (M) 3*4096kB (M) = 15900kB Jun 17 03:13:17 my kernel: Node 0 DMA32: 3172*4kB (UME) 1384*8kB (UE) 744*16kB (UME) 242*32kB (UME) 15*64kB (UME) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 44368kB Jun 17 03:13:17 my kernel: Node 0 Normal: 157*4kB (UME) 2012*8kB (UMEH) 976*16kB (UMEH) 291*32kB (UME) 4*64kB (M) 2*128kB (M) 1*256kB (M) 0*512kB 0*1024kB 0*2048kB 0*4096kB = 42420kB Jun 17 03:13:17 my kernel: Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB Jun 17 03:13:17 my kernel: 337832 total pagecache pages Jun 17 03:13:17 my kernel: 33532 pages in swap cache Jun 17 03:13:17 my kernel: Swap cache stats: add 413059, delete 379528, find 3909879/3976154 Jun 17 03:13:17 my kernel: Free swap = 0kB Jun 17 03:13:17 my kernel: Total swap = 1004540kB Jun 17 03:13:17 my kernel: 2097018 pages RAM Jun 17 03:13:17 my kernel: 0 pages HighMem/MovableOnly Jun 17 03:13:17 my kernel: 58777 pages reserved Jun 17 03:13:17 my kernel: 0 pages cma reserved Jun 17 03:13:17 my kernel: 0 pages hwpoisoned Jun 17 03:13:17 my kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=ac3d3b89315a33f079b879cebf2fa7d68e0512640f9a7ab16e1b9c79b192fa1b,mems_allowed=0,global_oom,task_memcg=/system.slice/box-task-10731.service,task=node,pid=1757378,uid=0 Jun 17 03:13:17 my kernel: Out of memory: Killed process 1757378 (node) total-vm:2615204kB, anon-rss:1725444kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:8244kB oom_score_adj:0 Jun 17 03:13:17 my kernel: oom_reaper: reaped process 1757378 (node), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB Jun 17 03:13:17 my sudo[1757377]: pam_unix(sudo:session): session closed for user root Jun 17 03:13:17 my systemd[1]: box-task-10731.service: Main process exited, code=exited, status=50/n/a Jun 17 03:13:17 my systemd[1]: box-task-10731.service: Failed with result 'exit-code'.This time it wasn't MySQL but was redis apparently?
The system memory output is below too:
free -h total used free shared buff/cache available Mem: 7.8Gi 4.5Gi 237Mi 1.2Gi 3.1Gi 1.8Gi Swap: 980Mi 969Mi 11Mi--
Dustin Dauncey
www.d19.ca -
Just encountered the issue again.
Here are the latest logs:
Jun 17 03:13:17 my kernel: redis-server invoked oom-killer: gfp_mask=0x100cca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 Jun 17 03:13:17 my kernel: CPU: 1 PID: 6436 Comm: redis-server Not tainted 5.4.0-74-generic #83-Ubuntu Jun 17 03:13:17 my kernel: Hardware name: Vultr HFC, BIOS Jun 17 03:13:17 my kernel: Call Trace: Jun 17 03:13:17 my kernel: dump_stack+0x6d/0x8b Jun 17 03:13:17 my kernel: dump_header+0x4f/0x1eb Jun 17 03:13:17 my kernel: oom_kill_process.cold+0xb/0x10 Jun 17 03:13:17 my kernel: out_of_memory.part.0+0x1df/0x3d0 Jun 17 03:13:17 my kernel: out_of_memory+0x6d/0xd0 Jun 17 03:13:17 my kernel: __alloc_pages_slowpath+0xd5e/0xe50 Jun 17 03:13:17 my kernel: __alloc_pages_nodemask+0x2d0/0x320 Jun 17 03:13:17 my kernel: alloc_pages_current+0x87/0xe0 Jun 17 03:13:17 my kernel: __page_cache_alloc+0x72/0x90 Jun 17 03:13:17 my kernel: pagecache_get_page+0xbf/0x300 Jun 17 03:13:17 my kernel: filemap_fault+0x6b2/0xa50 Jun 17 03:13:17 my kernel: ? unlock_page_memcg+0x12/0x20 Jun 17 03:13:17 my kernel: ? page_add_file_rmap+0xff/0x1a0 Jun 17 03:13:17 my kernel: ? xas_load+0xd/0x80 Jun 17 03:13:17 my kernel: ? xas_find+0x17f/0x1c0 Jun 17 03:13:17 my kernel: ? filemap_map_pages+0x24c/0x380 Jun 17 03:13:17 my kernel: ext4_filemap_fault+0x32/0x50 Jun 17 03:13:17 my kernel: __do_fault+0x3c/0x130 Jun 17 03:13:17 my kernel: do_fault+0x24b/0x640 Jun 17 03:13:17 my kernel: __handle_mm_fault+0x4c5/0x7a0 Jun 17 03:13:17 my kernel: handle_mm_fault+0xca/0x200 Jun 17 03:13:17 my kernel: do_user_addr_fault+0x1f9/0x450 Jun 17 03:13:17 my kernel: __do_page_fault+0x58/0x90 Jun 17 03:13:17 my kernel: do_page_fault+0x2c/0xe0 Jun 17 03:13:17 my kernel: do_async_page_fault+0x39/0x70 Jun 17 03:13:17 my kernel: async_page_fault+0x34/0x40 Jun 17 03:13:17 my kernel: RIP: 0033:0x5642ded5def4 Jun 17 03:13:17 my kernel: Code: Bad RIP value. Jun 17 03:13:17 my kernel: RSP: 002b:00007ffe39d1f480 EFLAGS: 00010293 Jun 17 03:13:17 my kernel: RAX: 0000000000000001 RBX: 0000000000000000 RCX: 00005642dedb5a14 Jun 17 03:13:17 my kernel: RDX: 0000000000000001 RSI: 00007f6c13408823 RDI: 0000000000000002 Jun 17 03:13:17 my kernel: RBP: 0000000000000000 R08: 0000000000000000 R09: 00007ffe39d1f3d8 Jun 17 03:13:17 my kernel: R10: 00007ffe39d1f3d0 R11: 0000000000000000 R12: 00007ffe39d1f648 Jun 17 03:13:17 my kernel: R13: 0000000000000002 R14: 00007f6c1341f020 R15: 0000000000000000 Jun 17 03:13:17 my kernel: Mem-Info: Jun 17 03:13:17 my kernel: active_anon:961079 inactive_anon:871527 isolated_anon:0 Jun 17 03:13:17 my kernel: Node 0 active_anon:3844316kB inactive_anon:3486108kB active_file:624kB inactive_file:464kB unevictable:18540kB isolated(anon):0kB isolated(file):20kB mapped:900656kB dirty:0kB writeback:0kB shmem:1207700kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB unstable:0kB all_unreclaimable? no Jun 17 03:13:17 my kernel: Node 0 DMA free:15900kB min:132kB low:164kB high:196kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB writepending:0kB present:15992kB managed:15908kB mlocked:0kB kernel_stack:0kB pagetables:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Jun 17 03:13:17 my kernel: lowmem_reserve[]: 0 2911 7858 7858 7858 Jun 17 03:13:17 my kernel: Node 0 DMA32 free:44284kB min:24988kB low:31232kB high:37476kB active_anon:1420788kB inactive_anon:1398328kB active_file:0kB inactive_file:360kB unevictable:0kB writepending:0kB present:3129200kB managed:3063664kB mlocked:0kB kernel_stack:9504kB pagetables:29712kB bounce:0kB free_pcp:1560kB local_pcp:540kB free_cma:0kB Jun 17 03:13:17 my kernel: lowmem_reserve[]: 0 0 4946 4946 4946 Jun 17 03:13:17 my kernel: Node 0 Normal free:42004kB min:42460kB low:53072kB high:63684kB active_anon:2423528kB inactive_anon:2087780kB active_file:588kB inactive_file:808kB unevictable:18540kB writepending:0kB present:5242880kB managed:5073392kB mlocked:18540kB kernel_stack:29040kB pagetables:53096kB bounce:0kB free_pcp:3512kB local_pcp:676kB free_cma:0kB Jun 17 03:13:17 my kernel: lowmem_reserve[]: 0 0 0 0 0 Jun 17 03:13:17 my kernel: Node 0 DMA: 1*4kB (U) 1*8kB (U) 1*16kB (U) 0*32kB 2*64kB (U) 1*128kB (U) 1*256kB (U) 0*512kB 1*1024kB (U) 1*2048kB (M) 3*4096kB (M) = 15900kB Jun 17 03:13:17 my kernel: Node 0 DMA32: 3172*4kB (UME) 1384*8kB (UE) 744*16kB (UME) 242*32kB (UME) 15*64kB (UME) 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 44368kB Jun 17 03:13:17 my kernel: Node 0 Normal: 157*4kB (UME) 2012*8kB (UMEH) 976*16kB (UMEH) 291*32kB (UME) 4*64kB (M) 2*128kB (M) 1*256kB (M) 0*512kB 0*1024kB 0*2048kB 0*4096kB = 42420kB Jun 17 03:13:17 my kernel: Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB Jun 17 03:13:17 my kernel: 337832 total pagecache pages Jun 17 03:13:17 my kernel: 33532 pages in swap cache Jun 17 03:13:17 my kernel: Swap cache stats: add 413059, delete 379528, find 3909879/3976154 Jun 17 03:13:17 my kernel: Free swap = 0kB Jun 17 03:13:17 my kernel: Total swap = 1004540kB Jun 17 03:13:17 my kernel: 2097018 pages RAM Jun 17 03:13:17 my kernel: 0 pages HighMem/MovableOnly Jun 17 03:13:17 my kernel: 58777 pages reserved Jun 17 03:13:17 my kernel: 0 pages cma reserved Jun 17 03:13:17 my kernel: 0 pages hwpoisoned Jun 17 03:13:17 my kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=ac3d3b89315a33f079b879cebf2fa7d68e0512640f9a7ab16e1b9c79b192fa1b,mems_allowed=0,global_oom,task_memcg=/system.slice/box-task-10731.service,task=node,pid=1757378,uid=0 Jun 17 03:13:17 my kernel: Out of memory: Killed process 1757378 (node) total-vm:2615204kB, anon-rss:1725444kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:8244kB oom_score_adj:0 Jun 17 03:13:17 my kernel: oom_reaper: reaped process 1757378 (node), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB Jun 17 03:13:17 my sudo[1757377]: pam_unix(sudo:session): session closed for user root Jun 17 03:13:17 my systemd[1]: box-task-10731.service: Main process exited, code=exited, status=50/n/a Jun 17 03:13:17 my systemd[1]: box-task-10731.service: Failed with result 'exit-code'.This time it wasn't MySQL but was redis apparently?
The system memory output is below too:
free -h total used free shared buff/cache available Mem: 7.8Gi 4.5Gi 237Mi 1.2Gi 3.1Gi 1.8Gi Swap: 980Mi 969Mi 11Mi@d19dotca as mentioned, I think the only option for now is to either increase "physical" memory on the server or decrease the memory limit for the backup task. Also I guess from your screenshot you might want to decrease part-size, since from your memory paste and part size of 256MB, a single part, loaded into memory, would force the server to kill something to free up some memory.
Of course decreasing part-size usually means slower backups or if you have huge files, some object storages will hit part-number limits then...
-
@d19dotca as mentioned, I think the only option for now is to either increase "physical" memory on the server or decrease the memory limit for the backup task. Also I guess from your screenshot you might want to decrease part-size, since from your memory paste and part size of 256MB, a single part, loaded into memory, would force the server to kill something to free up some memory.
Of course decreasing part-size usually means slower backups or if you have huge files, some object storages will hit part-number limits then...
@nebulon Okay, I've further lowered the backup config and will hope that works for now. I just don't quite get why memory is an issue when my server never seems to go much beyond 5 GB used out of 8 GB. Nothing really changed outside of moving to Vultr, and even then that was about 1.5 months ago and this issue only started in the past week or so.
--
Dustin Dauncey
www.d19.ca -
@nebulon Okay, I've further lowered the backup config and will hope that works for now. I just don't quite get why memory is an issue when my server never seems to go much beyond 5 GB used out of 8 GB. Nothing really changed outside of moving to Vultr, and even then that was about 1.5 months ago and this issue only started in the past week or so.
@d19dotca but your screenpastes do show the server getting low on memory
237Mifree is quite low given your part-size setting. Whatever shared/buff/availalbe is shown there, if the kernel decides to kill a task means those other bits are deemed more important and can't be freed up.
Especially during backup the system I/O will use quite a bit of memory for buffering.I acknowledge that this is not ideal to keep such a large amount of memory around just for the backup task, so I think the alternative is to restrict the backup task heavily and keep backup objects small (meaning maybe not using tarball strategy if you do). The tradeoff will be slower backups though.
-
@d19dotca but your screenpastes do show the server getting low on memory
237Mifree is quite low given your part-size setting. Whatever shared/buff/availalbe is shown there, if the kernel decides to kill a task means those other bits are deemed more important and can't be freed up.
Especially during backup the system I/O will use quite a bit of memory for buffering.I acknowledge that this is not ideal to keep such a large amount of memory around just for the backup task, so I think the alternative is to restrict the backup task heavily and keep backup objects small (meaning maybe not using tarball strategy if you do). The tradeoff will be slower backups though.
@nebulon Okay I've not had a backup crash in the last two days approximately now since severely limiting the backup memory from what it used to be. I still don't understand why it's suddenly crashing when it's been configured this way for so long now and only started recently happening with no new apps or memory changes (that I'm aware of anyways), but I'll keep an eye on it. Thanks for the help Nebulon, looks like limiting the backup memory is working for now.
-
Hi @nebulon - I see recently that there are a few
puma: cluster workercommands being run which seem to be taking up a decent chunk of memory... any ideas if this is Cloudron-related? I haven't noticedpumabefore. Wondering if this is related to the memory issues I've been having recently too.ubuntu@my:~$ ps aux --sort -rss | head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND uuidd 10044 4.4 2.0 2617076 300100 ? Sl 09:13 0:22 /usr/sbin/mysqld ubuntu 13987 0.3 1.8 1129480 279584 pts/0 Sl 09:14 0:01 puma: cluster worker 1: 17 [code] ubuntu 13982 0.2 1.6 1129480 253660 pts/0 Sl 09:14 0:00 puma: cluster worker 0: 17 [code] ubuntu 13717 2.6 1.6 406624 251220 pts/0 Sl 09:14 0:11 sidekiq 6.2.1 code [0 of 2 busy] ubuntu 13716 2.2 1.6 453504 243064 pts/0 Sl 09:14 0:09 puma 5.3.2 (tcp://127.0.0.1:3000) [code] yellowt+ 11728 1.9 1.1 1592140 177712 pts/0 Sl 09:13 0:09 /home/git/gitea/gitea web -c /run/gitea/app.ini -p 3000 mysql 834 1.0 1.0 2482488 161512 ? Ssl 09:12 0:05 /usr/sbin/mysqld root 845 2.5 0.8 3316204 132860 ? Ssl 09:12 0:13 /usr/bin/dockerd -H fd:// --log-driver=journald --exec-opt native.cgroupdriver=cgroupfs --storage-driver=overlay2 ubuntu 14525 1.4 0.8 11457536 122692 pts/0 Sl+ 09:14 0:05 /usr/local/node-14.15.4/bin/node /app/code/app.js
Edit: I believe I've confirmed now that the
pumaandsidekiqcommands/services are related to Mastodon. When I stop Mastodon, those services go away too.I realized this issue started happening right around the time of the latest Mastodon update which was ~17 days ago. Now I'm starting to wonder if this latest 1.6.2 version release is related... https://forum.cloudron.io/post/32335
--
Dustin Dauncey
www.d19.ca -
Hi @nebulon - I see recently that there are a few
puma: cluster workercommands being run which seem to be taking up a decent chunk of memory... any ideas if this is Cloudron-related? I haven't noticedpumabefore. Wondering if this is related to the memory issues I've been having recently too.ubuntu@my:~$ ps aux --sort -rss | head USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND uuidd 10044 4.4 2.0 2617076 300100 ? Sl 09:13 0:22 /usr/sbin/mysqld ubuntu 13987 0.3 1.8 1129480 279584 pts/0 Sl 09:14 0:01 puma: cluster worker 1: 17 [code] ubuntu 13982 0.2 1.6 1129480 253660 pts/0 Sl 09:14 0:00 puma: cluster worker 0: 17 [code] ubuntu 13717 2.6 1.6 406624 251220 pts/0 Sl 09:14 0:11 sidekiq 6.2.1 code [0 of 2 busy] ubuntu 13716 2.2 1.6 453504 243064 pts/0 Sl 09:14 0:09 puma 5.3.2 (tcp://127.0.0.1:3000) [code] yellowt+ 11728 1.9 1.1 1592140 177712 pts/0 Sl 09:13 0:09 /home/git/gitea/gitea web -c /run/gitea/app.ini -p 3000 mysql 834 1.0 1.0 2482488 161512 ? Ssl 09:12 0:05 /usr/sbin/mysqld root 845 2.5 0.8 3316204 132860 ? Ssl 09:12 0:13 /usr/bin/dockerd -H fd:// --log-driver=journald --exec-opt native.cgroupdriver=cgroupfs --storage-driver=overlay2 ubuntu 14525 1.4 0.8 11457536 122692 pts/0 Sl+ 09:14 0:05 /usr/local/node-14.15.4/bin/node /app/code/app.js
Edit: I believe I've confirmed now that the
pumaandsidekiqcommands/services are related to Mastodon. When I stop Mastodon, those services go away too.I realized this issue started happening right around the time of the latest Mastodon update which was ~17 days ago. Now I'm starting to wonder if this latest 1.6.2 version release is related... https://forum.cloudron.io/post/32335
@d19dotca if it aligns time-wise this is quite possible. Maybe mastodon has memory spikes as well which could align with the memory requirement of the backup process then. Not sure what could be done though, if the memory is indeed used for backups and the app components.
-
@d19dotca if it aligns time-wise this is quite possible. Maybe mastodon has memory spikes as well which could align with the memory requirement of the backup process then. Not sure what could be done though, if the memory is indeed used for backups and the app components.
@nebulon So I stopped the Mastodon app, and things seem a bit better but I find the memory still runs low, it's only a matter of maybe 12 hours and the
freememory is less than 300 MB. I don't think that used to be the case. You mentioning that the free memory was low got me intrigued as to what was taking up the memory. With all apps and services running except for Mastodon, and soon after a reboot, the following is the memory usage by service:ubuntu@my:~$ ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END \ { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 20 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' 3942MB /usr/sbin/apach 1769MB node 1030MB ruby2.7 717MB supervisord 511MB mysqld 468MB containerd-shim 263MB spamd 220MB redis-server 207MB postmaster 164MB nginx 132MB dockerd 114MB mongod 94MB uwsgi 59MB containerd 57MB systemd-udevd 38MB carbon-cache 35MB snapd 35MB imap 34MB pidproxy 33MB radicaleIs the memory usage for
nodesounding about right with it being under 2 GB? Do you have any concerns with the memory usage above as the top 20 memory-consuming tasks?For context, after a reboot, my server memory is as follows (I'll update tomorrow morning/afternoon when it's low again):
ubuntu@my:~$ free -h total used free shared buff/cache available Mem: 14Gi 4.0Gi 4.8Gi 449Mi 5.5Gi 9.6Gi Swap: 4.0Gi 0B 4.0Gi--
Dustin Dauncey
www.d19.ca -
@nebulon So I stopped the Mastodon app, and things seem a bit better but I find the memory still runs low, it's only a matter of maybe 12 hours and the
freememory is less than 300 MB. I don't think that used to be the case. You mentioning that the free memory was low got me intrigued as to what was taking up the memory. With all apps and services running except for Mastodon, and soon after a reboot, the following is the memory usage by service:ubuntu@my:~$ ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END \ { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 20 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' 3942MB /usr/sbin/apach 1769MB node 1030MB ruby2.7 717MB supervisord 511MB mysqld 468MB containerd-shim 263MB spamd 220MB redis-server 207MB postmaster 164MB nginx 132MB dockerd 114MB mongod 94MB uwsgi 59MB containerd 57MB systemd-udevd 38MB carbon-cache 35MB snapd 35MB imap 34MB pidproxy 33MB radicaleIs the memory usage for
nodesounding about right with it being under 2 GB? Do you have any concerns with the memory usage above as the top 20 memory-consuming tasks?For context, after a reboot, my server memory is as follows (I'll update tomorrow morning/afternoon when it's low again):
ubuntu@my:~$ free -h total used free shared buff/cache available Mem: 14Gi 4.0Gi 4.8Gi 449Mi 5.5Gi 9.6Gi Swap: 4.0Gi 0B 4.0Gi@d19dotca my shell foo is not that great, but is it possible that your listing would combine all processes with the same name? If that is the case then maybe this is ok, otherwise I wonder which is that single node process and also that single supervisord should hardly take up that much.
-
@d19dotca my shell foo is not that great, but is it possible that your listing would combine all processes with the same name? If that is the case then maybe this is ok, otherwise I wonder which is that single node process and also that single supervisord should hardly take up that much.
@nebulon Oh sorry, yes that was a command I found online which I thought was neat, haha. It just combines processes with the same name which I think is useful at times, so it's basically a summary of all MySQL services, all Node servers, etc.
Thanks for the assistance by the way - I know I'm deviating a bit from the original concern so that's okay - we can probably mark this resolved now since limiting the backup task memory was sufficient for now. It just has me wondering about memory usage overall on my system now. haha. I'll maybe file a new post if I need a bit more insight later to memory stuff. Thanks again for the help!
")
For reference, here is the current status of those commands:
ubuntu@my:~$ free -h total used free shared buff/cache available Mem: 14Gi 5.3Gi 797Mi 925Mi 8.2Gi 7.8Gi Swap: 4.0Gi 3.0Mi 4.0Gi(there was 2.2 GB free when I woke up this morning but little left now because it just completed a backup, so hoping that memory gets put back - but wondering if maybe this is why it's going to low in "free" memory (even though plenty left in "available" memory).
ubuntu@my:~$ ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END \ > { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 20 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}' 5793MB /usr/sbin/apach 1958MB node 1070MB ruby2.7 903MB mysqld 716MB supervisord 476MB containerd-shim 327MB spamd 236MB redis-server 179MB postmaster 170MB nginx 139MB mongod 133MB dockerd 121MB uwsgi 81MB imap 65MB systemd-udevd 61MB containerd 59MB imap-login 44MB radicale 39MB carbon-cache 36MB snapdDefinitely a lot more Apache-related memory usage (which I guess is just all the containers running Apache like all the WordPress sites for example and makes sense as most of the apps running are WordPress apps in Cloudron). MySQL memory also almost doubled, but since so many are WordPress sites and if they're getting busier I suspect that means more MySQL usage which means MySQL will use more memory, so I think that all checks out still.
One thing I'm not sure I fully understand yet (but maybe this is a bit outside the scope of Cloudron) is the memory part... so last night I had 4.0 GB used and 4.8 GB in the free column, now it's 5.3 GB used but the free memory dropped by about 4 GB to 797 MB from 4.8 GB last night. That's where I get a bit confused and unsure why that goes so low when the memory usage only went up a bit. I believe it basically becomes "reserved" and then used in the "buff/cache" and when no longer used it's still reserved so becomes "available", is that right do you think?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login