Java support for LAMP?
-
I'm wondering if it's possible to add Java support to the LAMP app.
Reason: Filerun supports full-text-indexing and -search via Apache Tika and it seems quite easy...: https://docs.filerun.com/doku.php?id=file_indexing&rev=1592721884
Apache Tika is used for extracting text contents from non-plain-text files, such as PDFs or office files.
Note: Your server needs to have Java support, in order to run Apache Tika.
You can read more about Apache Tika here: https://tika.apache.orgRunning Tika in command line mode:
- Download the tika-app-[*].jar (note the app part in the file's name) file from here: https://tika.apache.org/download.html
- Set the path to the tika-app-[*].jar file inside FileRun's control panel
That's it!
-
I'm wondering if it's possible to add Java support to the LAMP app.
Reason: Filerun supports full-text-indexing and -search via Apache Tika and it seems quite easy...: https://docs.filerun.com/doku.php?id=file_indexing&rev=1592721884
Apache Tika is used for extracting text contents from non-plain-text files, such as PDFs or office files.
Note: Your server needs to have Java support, in order to run Apache Tika.
You can read more about Apache Tika here: https://tika.apache.orgRunning Tika in command line mode:
- Download the tika-app-[*].jar (note the app part in the file's name) file from here: https://tika.apache.org/download.html
- Set the path to the tika-app-[*].jar file inside FileRun's control panel
That's it!
-
Here is what FileRun shows in the search config for Tika:
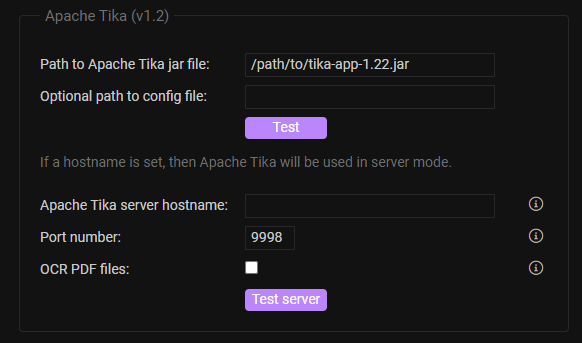
So it can either run as an app, which means you need java to run the .jar
OR
You can run it as a server, if it were a Cloudron App.
(we can try this by using a surrogate java App and find the internal IP 172.x.x.x:9998 ) -
@necrevistonnezr would the idea be to use the "Install Apache Tika (Command line mode)" ?
@girish said in Java support for LAMP?:
@necrevistonnezr would the idea be to use the "Install Apache Tika (Command line mode)" ?
As @robi explained - Running the jar as an app seems a lot easier(?)
-
So I got to try this..
Installed Metabase, which has java, and from it's CLI ran the tika server which started on localhost:9998
So far so good, then I went to the FileRun LAMP App and tried to connect:
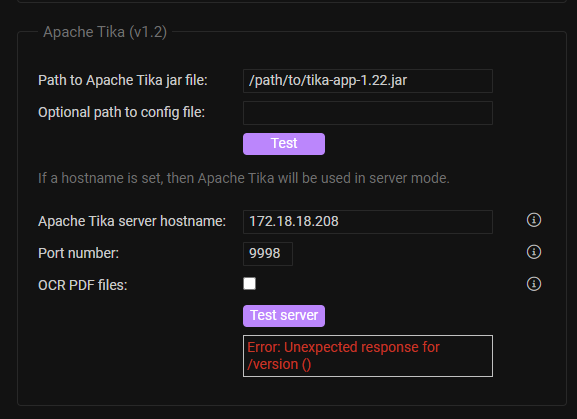
Then to the LAMP Terminal:root@7cc9dc8b-e60f-4150-80f1-ff18d13dd924:/app/code# telnet 172.18.18.208 9998 Trying 172.18.18.208... telnet: Unable to connect to remote host: Connection refused root@7cc9dc8b-e60f-4150-80f1-ff18d13dd924:/app/code# ping 172.18.18.208 bash: /usr/bin/ping: Operation not permittedRight, needs to listen on the right host/IP
Back to Metabase Terminal (you can run it with --help for all the options):
# java -jar tika-server-standard-2.3.0.jar -h 172.18.18.208 &You can find the IP via
ifconfig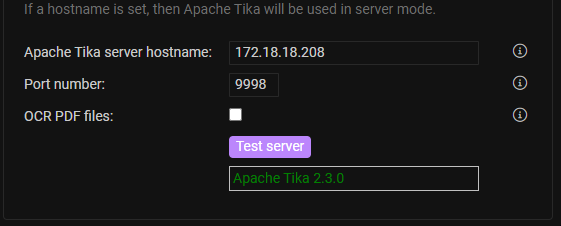
Not sure how to get any search results, as it seems to expect elastic search nodes for any indexing.. so Tika doesn't seem useful on it's own???
I was hoping for plain text file search results too, but that doesn't appear to be happening either.
-
So I got to try this..
Installed Metabase, which has java, and from it's CLI ran the tika server which started on localhost:9998
So far so good, then I went to the FileRun LAMP App and tried to connect:
Then to the LAMP Terminal:root@7cc9dc8b-e60f-4150-80f1-ff18d13dd924:/app/code# telnet 172.18.18.208 9998 Trying 172.18.18.208... telnet: Unable to connect to remote host: Connection refused root@7cc9dc8b-e60f-4150-80f1-ff18d13dd924:/app/code# ping 172.18.18.208 bash: /usr/bin/ping: Operation not permittedRight, needs to listen on the right host/IP
Back to Metabase Terminal (you can run it with --help for all the options):
# java -jar tika-server-standard-2.3.0.jar -h 172.18.18.208 &You can find the IP via
ifconfigNot sure how to get any search results, as it seems to expect elastic search nodes for any indexing.. so Tika doesn't seem useful on it's own???
I was hoping for plain text file search results too, but that doesn't appear to be happening either.
@robi from https://docs.filerun.com/file_indexing
Please note that old/existing files will not be automatically indexed. If you wish to index these files, please see the available utility command lines.
To test the configuration, run the following from the FileRun server's command line:cd /path/to/filerun/cron php process_search_index_queue.phpIt will show the progress of processing the search indexing queue. It will extract file contents using Apache Tika and send it to Elasticsearch for indexing.
So it seems, you need both Tika and Elastic

Existing files need to be indexed via command lineThere‘s a docker with elastic and tika included : https://docs.filerun.com/docker-tika
-
@robi from https://docs.filerun.com/file_indexing
Please note that old/existing files will not be automatically indexed. If you wish to index these files, please see the available utility command lines.
To test the configuration, run the following from the FileRun server's command line:cd /path/to/filerun/cron php process_search_index_queue.phpIt will show the progress of processing the search indexing queue. It will extract file contents using Apache Tika and send it to Elasticsearch for indexing.
So it seems, you need both Tika and Elastic
Existing files need to be indexed via command lineThere‘s a docker with elastic and tika included : https://docs.filerun.com/docker-tika
@necrevistonnezr yes, a bit disappointed that it's not even doing plain text search as it seems to indicate before setting up Tika for looking into PDFs and even OCR if ones add Tesseract.
Perhaps a different workflow can be had once its files are mounted via webDAV and a local search done.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login