AI on Cloudron
-
I'm not sure if anyone here, power users, has realized that there already is AI tools and modules being added to Cloudron via several app carried and maintained by our fearless developers team here.
First I discover is in Joplin as I'm a Joplin power user (this app is amazing) and there exists several plugins to add to enhance the app and one of them is called Jarvis and offer SEVERAL AI features to use right inside your notes everywhere.
Then recently in the latest major release of NextCloud they've added an OpenAI integration module.
And just now, in a major release of ChatWoot: OpenAI integration : ( Reply suggestions, summarization, and ability to improve drafts ). This is just a beginning this app was already very much powerful and getting more and more almost by the day.
I guess, RocketChat and MatterMost* might quickly follow if it's not already done. (?)
Roughly, I know it can also be integrated into LibreOffice somehow.
What else, anyone?
-
I'm not sure if anyone here, power users, has realized that there already is AI tools and modules being added to Cloudron via several app carried and maintained by our fearless developers team here.
First I discover is in Joplin as I'm a Joplin power user (this app is amazing) and there exists several plugins to add to enhance the app and one of them is called Jarvis and offer SEVERAL AI features to use right inside your notes everywhere.
Then recently in the latest major release of NextCloud they've added an OpenAI integration module.
And just now, in a major release of ChatWoot: OpenAI integration : ( Reply suggestions, summarization, and ability to improve drafts ). This is just a beginning this app was already very much powerful and getting more and more almost by the day.
I guess, RocketChat and MatterMost* might quickly follow if it's not already done. (?)
Roughly, I know it can also be integrated into LibreOffice somehow.
What else, anyone?
@micmc said in AI on Cloudron:
What else, anyone?
There is some AI tagging of faces in the image applications, for example, Immich.
I think OCR (Optical Character Recognition) extraction of text from images could count as AI, too.
By the way, @micmc, thank you very much indeed for your brilliant links which are very worthwhile following.
-
We know Automatic1111 and Serge, there is also oobabooga, which is like a Serge rival, I suppose and which can install Llama2:
https://github.com/oobabooga/text-generation-webui
there is a video explaining how to do it here:
https://vid.puffyan.us/watch?v=SbuhznykQBg&quality=dash -
I guess you've come to realize the GPU power required to run a decent ML model
")
One might want to experience on a lower scale there already is models that work with consumer grade hardware. That you can install on your local PC, and since it runs on Docker theoretically it should run on a VPS as well as maybe even Cloudron then. I've not yet tested this on a VPS but I'm working on it.
Check out https://localai.io/ which does NOT require GPU and uses several GPT models as well, like llama.cpp, gpt4all.cpp and whisper.cpp and more... This site is very interesting for AI enthusiasts who want to learn more and tests things deeper, it's fascinating.
Enjoy!
@micmc said in AI on Cloudron:
I guess you've come to realize the GPU power required to run a decent ML model
I sure have! Some people have commented that Meta deliberately didn't release a 30b version of Llama2 as that would be just about possible to run on consumer grade hardware.
That 70b Llama2 I tried on huggingface chat and I loved it! I want to try and host it, and am trying to figure out how to go about doing that. This is what I am looking at. Maybe others here have some better ideas!
https://xethub.com/XetHub/Llama2
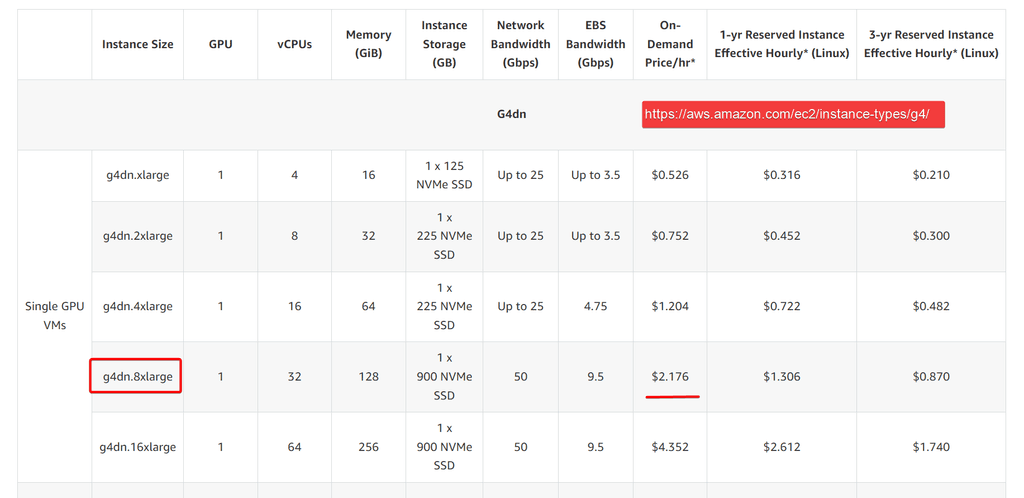
Is it relatively easy to just "turn on" a pre-saved instance when you are ready for a session and then go full-steam for a couple of hours, then when you are finished for the day, "turn off" and just pay the $4? It is a highly efficient.
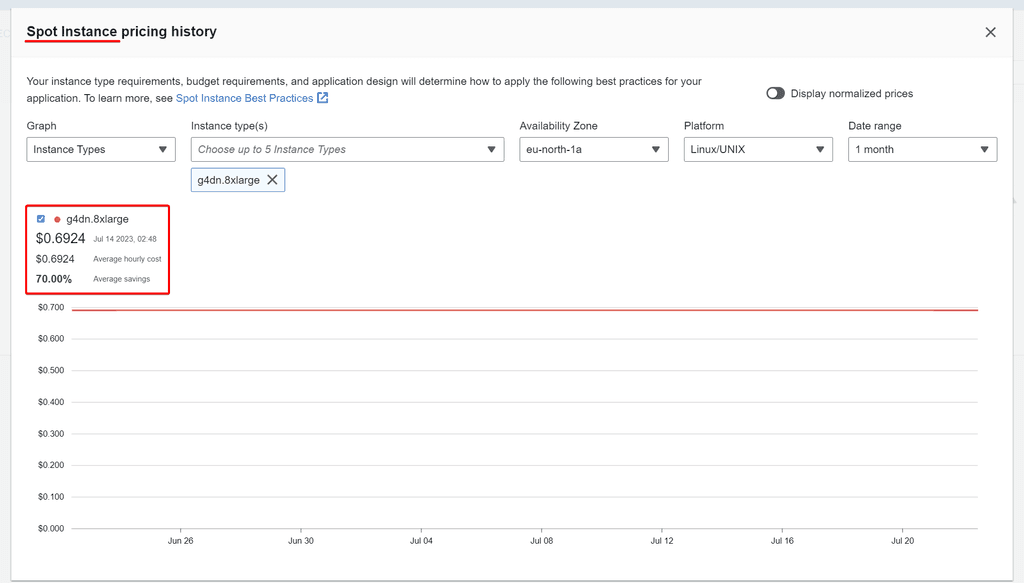
-
I was reading through localai.io github pages and it mentions this nifty tool for upscaling images (Upscayl). It converted a 640px image to 2560px and the detail improvement is insane. No more blurriness or pixelation, and it even enhances the colors to make it "pop". I used the ULTRASHARP mode. The first (default) mode in the list does the same job minus the color pop. Here are the images for comparison.
640px ring

2560px upscayle + compressed (TinyPNG; forum limits size to 4MB)

-
Talking about LocalAI.io There is now a OpenAI plugin that can be added to OnlyOffice in NextCloud.
You can use OpenAI API by putting your API key, but it can also be use, and this is what they even recommend, with a LocalAI instance running on the same server as NextCloud.I guess we should start looking if a local instance of LocalAI could be run smoothly on a LAMP instance on Cloudron, and even be added as an app to Cloudron since it is built to run on Docker already?
-
Talking about LocalAI.io There is now a OpenAI plugin that can be added to OnlyOffice in NextCloud.
You can use OpenAI API by putting your API key, but it can also be use, and this is what they even recommend, with a LocalAI instance running on the same server as NextCloud.I guess we should start looking if a local instance of LocalAI could be run smoothly on a LAMP instance on Cloudron, and even be added as an app to Cloudron since it is built to run on Docker already?
-
@robi said in AI on Cloudron:
@micmc https://forum.cloudron.io/topic/9399/how-to-run-ai-models-in-lamp-app
Exactly what we need to deepened right!
Thanks mate. -
Stackoverflow usage has plummeted with people switching to AI for solutions, so they have now launched Overflow AI:
-
I'm not sure if anyone here, power users, has realized that there already is AI tools and modules being added to Cloudron via several app carried and maintained by our fearless developers team here.
First I discover is in Joplin as I'm a Joplin power user (this app is amazing) and there exists several plugins to add to enhance the app and one of them is called Jarvis and offer SEVERAL AI features to use right inside your notes everywhere.
Then recently in the latest major release of NextCloud they've added an OpenAI integration module.
And just now, in a major release of ChatWoot: OpenAI integration : ( Reply suggestions, summarization, and ability to improve drafts ). This is just a beginning this app was already very much powerful and getting more and more almost by the day.
I guess, RocketChat and MatterMost* might quickly follow if it's not already done. (?)
Roughly, I know it can also be integrated into LibreOffice somehow.
What else, anyone?
@micmc said in AI on Cloudron:
Then recently in the latest major release of NextCloud they've added an OpenAI integration module.
Nextcloud have an article on this:
https://nextcloud.com/blog/ai-in-nextcloud-what-why-and-how/ -
Prompt Engineering World Championships:
https://app.openpipe.ai/world-champs/signupRoboCup 2023 - AI/Robot football:
https://www.robocup.org/
https://vid.puffyan.us/watch?v=vwIuQKKg-sY&quality=dash -
Nvidia reveal new chip:
https://nvidianews.nvidia.com/news/gh200-grace-hopper-superchip-with-hbm3e-memory -
Useful collection of AI prompts:
https://huggingface.co/datasets/fka/awesome-chatgpt-prompts -
Has anybody had success finetuning a language model so that it becomes an expert on local data? What free software tools were used and was it an enjoyable, fruitful process?
@LoudLemur said in AI on Cloudron:
Has anybody had success finetuning a language model so that it becomes an expert on local data? What free software tools were used and was it an enjoyable, fruitful process?
For my part, I'd been trying to play a little but not much yet, I'm actually busy working on developing and launching a SaaS Web UI through API connections to different LLM providers.
The service makes it very easy to anyone to create content (and well, much more like consulting with powerful coach bots in several fields) with a few clicks, and answering a few questions.
Local data labs is next... -
@LoudLemur said in AI on Cloudron:
Has anybody had success finetuning a language model so that it becomes an expert on local data? What free software tools were used and was it an enjoyable, fruitful process?
For my part, I'd been trying to play a little but not much yet, I'm actually busy working on developing and launching a SaaS Web UI through API connections to different LLM providers.
The service makes it very easy to anyone to create content (and well, much more like consulting with powerful coach bots in several fields) with a few clicks, and answering a few questions.
Local data labs is next... -
Fine-Tuned CodeLlama-34B now beats ChatGPT4 on HumanEval.
https://www.phind.com/blog/code-llama-beats-gpt4https://huggingface.co/sbeall/Phind-CodeLlama-34B-v1-q5_K_M-GGUF/tree/main
You can run it on Ollama today:
https://ollama.ai/library/phind-codellama/tagsOpenRouter allows you cheap access to Free Software Language Model APIs:
https://openrouter.ai/docs#models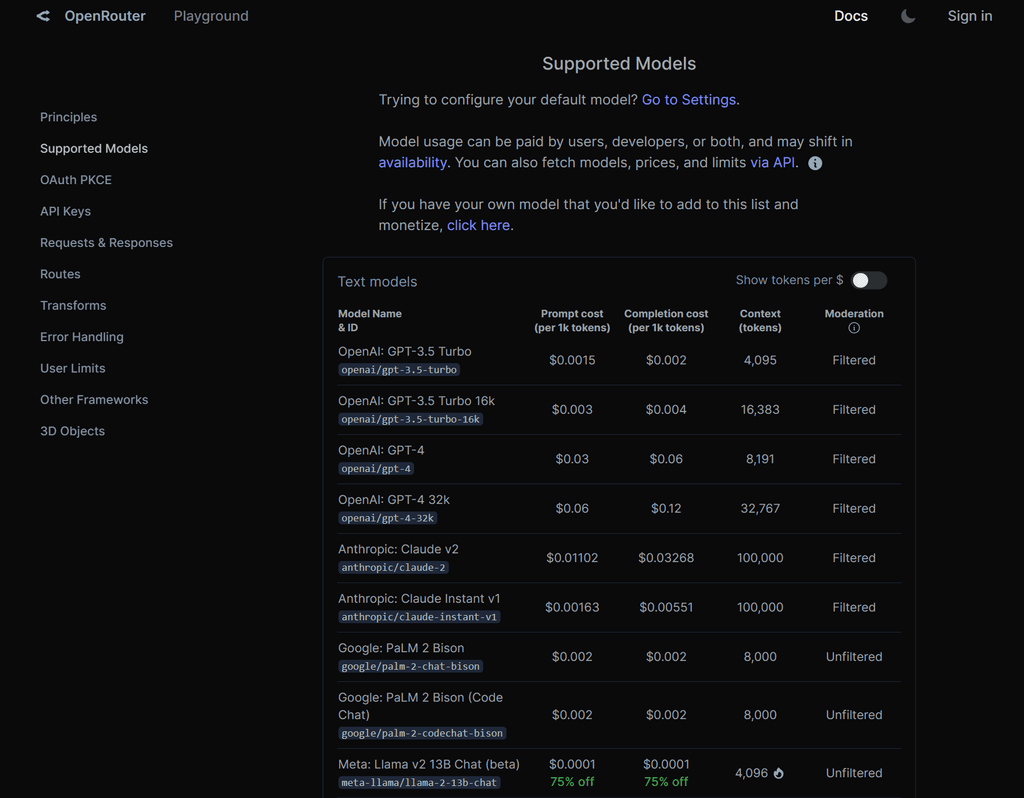
-
Falcon-180b (that is 180 billion parameter) Free Software model has now been released.
This is the chat version:https://huggingface.co/tiiuae/falcon-180B-chat
The open source dataset was created in the UAE through a process of web crawling and stringent filtering out of "adult" sites based on their URL. It is multi-modal friendly with image tagging.
The main site is being absolutely hammered at the moment. Archive:
https://archive.ph/trCCZThis is by far the largest Free Software model available at the moment, and it is outperforming Llama 2.
500GB download, 2.8TB storage after unpacking, 400 GB of memory will be needed to swiftly run inference o Falcon-180B.
"I think we are going to need a bigger boat."
-
Petals.dev
Run large language models, including Falcon-180b, bittorrent style:
https://petals.dev/ -
Falcon-180b (that is 180 billion parameter) Free Software model has now been released.
This is the chat version:https://huggingface.co/tiiuae/falcon-180B-chat
The open source dataset was created in the UAE through a process of web crawling and stringent filtering out of "adult" sites based on their URL. It is multi-modal friendly with image tagging.
The main site is being absolutely hammered at the moment. Archive:
https://archive.ph/trCCZThis is by far the largest Free Software model available at the moment, and it is outperforming Llama 2.
500GB download, 2.8TB storage after unpacking, 400 GB of memory will be needed to swiftly run inference o Falcon-180B.
"I think we are going to need a bigger boat."
@LoudLemur said in AI on Cloudron:
500GB download, 2.8TB storage after unpacking, 400 GB of memory will be needed to swiftly run inference o Falcon-180B.
I'm going to install 2 right away!

