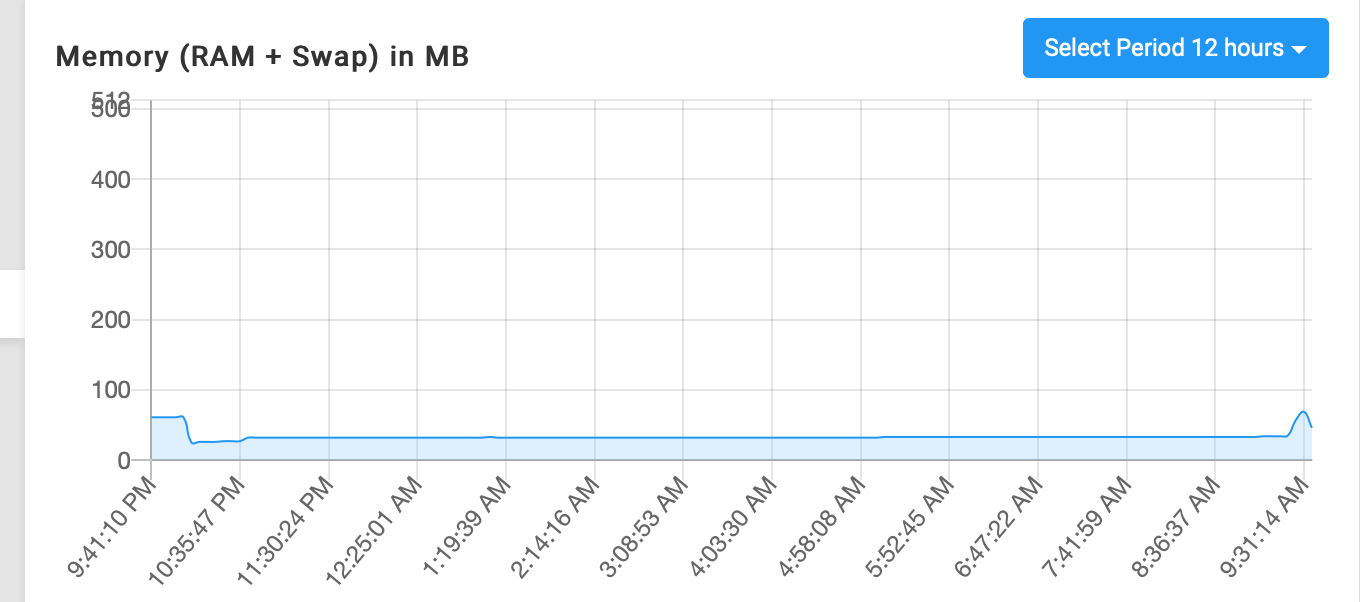
@james it's a Hetzner VPS (CPX51) and I admit, I'm trying to figure out the limits a bit, there are ~70 apps installed on that one, but none of those seem to be hogging a lot of RAM. Backups run at 1:00 in the morning, crash happened at ~8:00ish. I'll keep monitoring to figure out if there's a pattern, but so far I couldn't spot it.
system graphs:
[image: 1757515965695-fbd8f402-e1e2-4cd8-a331-3b3a134924d3-image-resized.png]
htop:
[image: 1757515744655-3ad7f6bc-c975-4dbd-925a-03eea8faf6c0-image-resized.png]