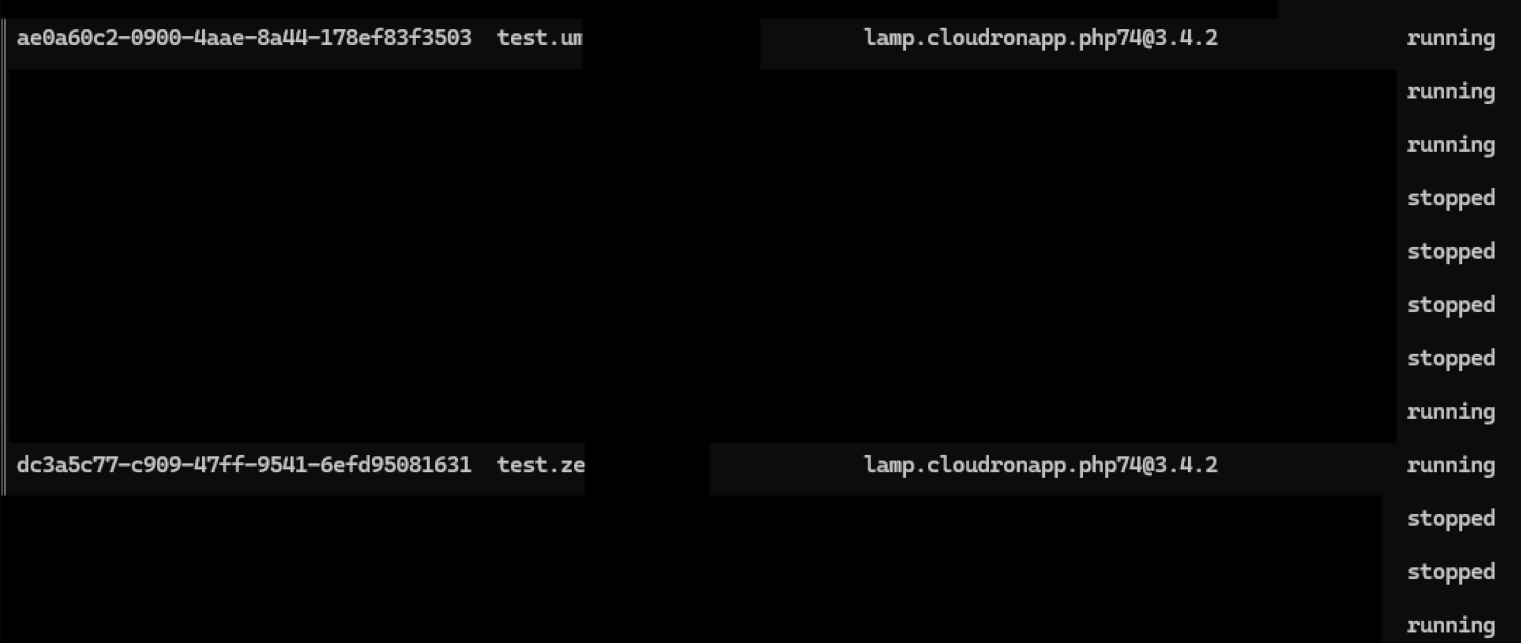
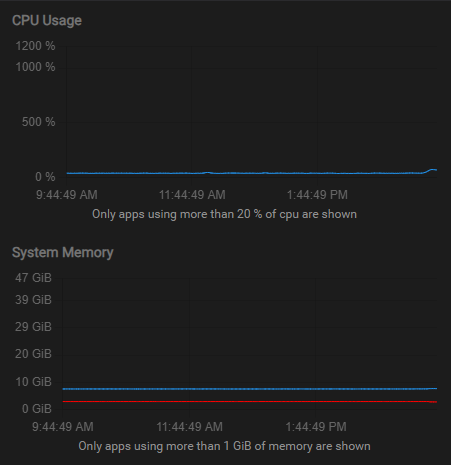
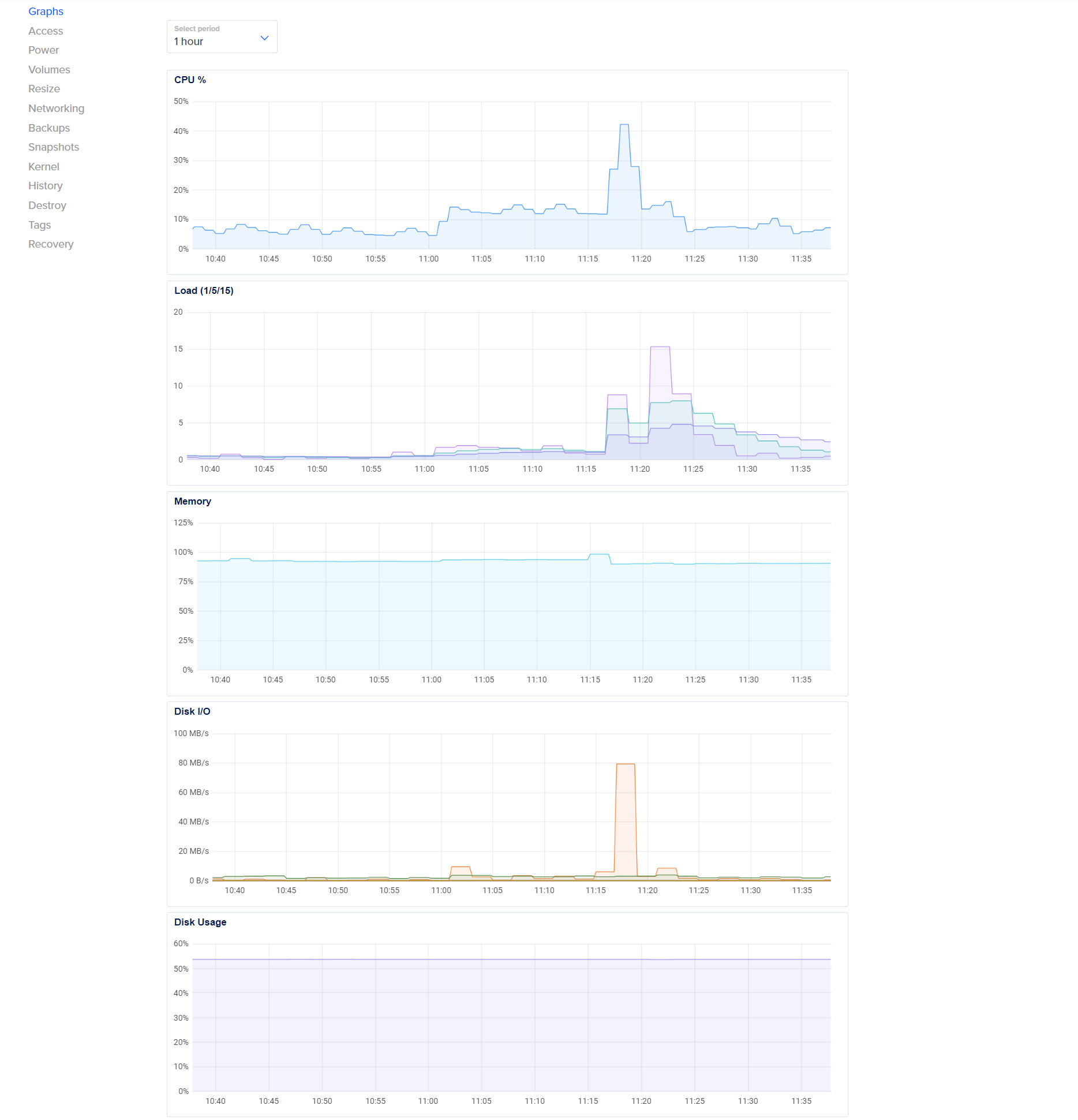
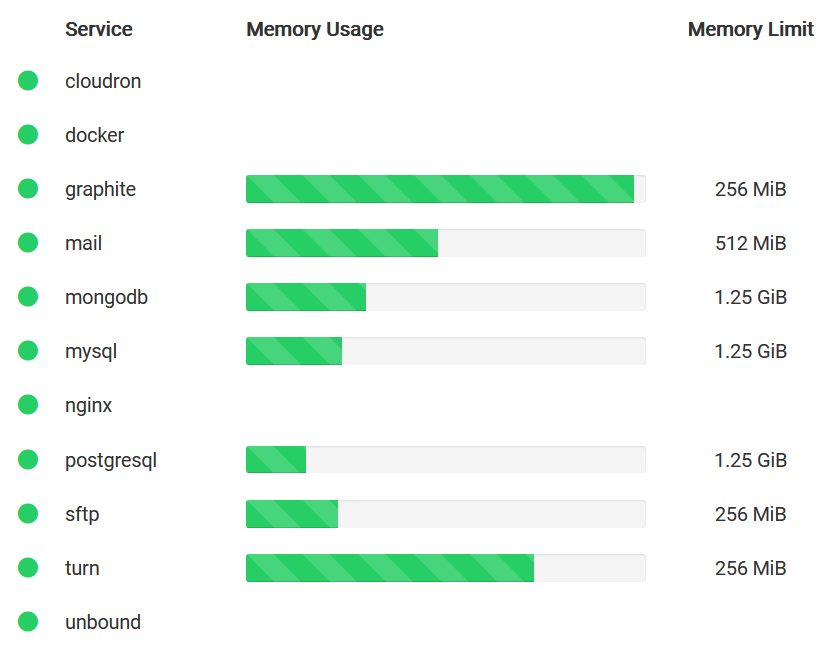
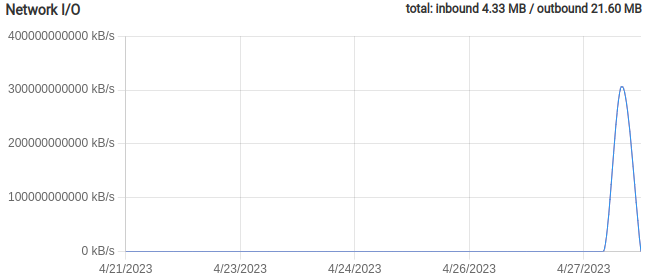
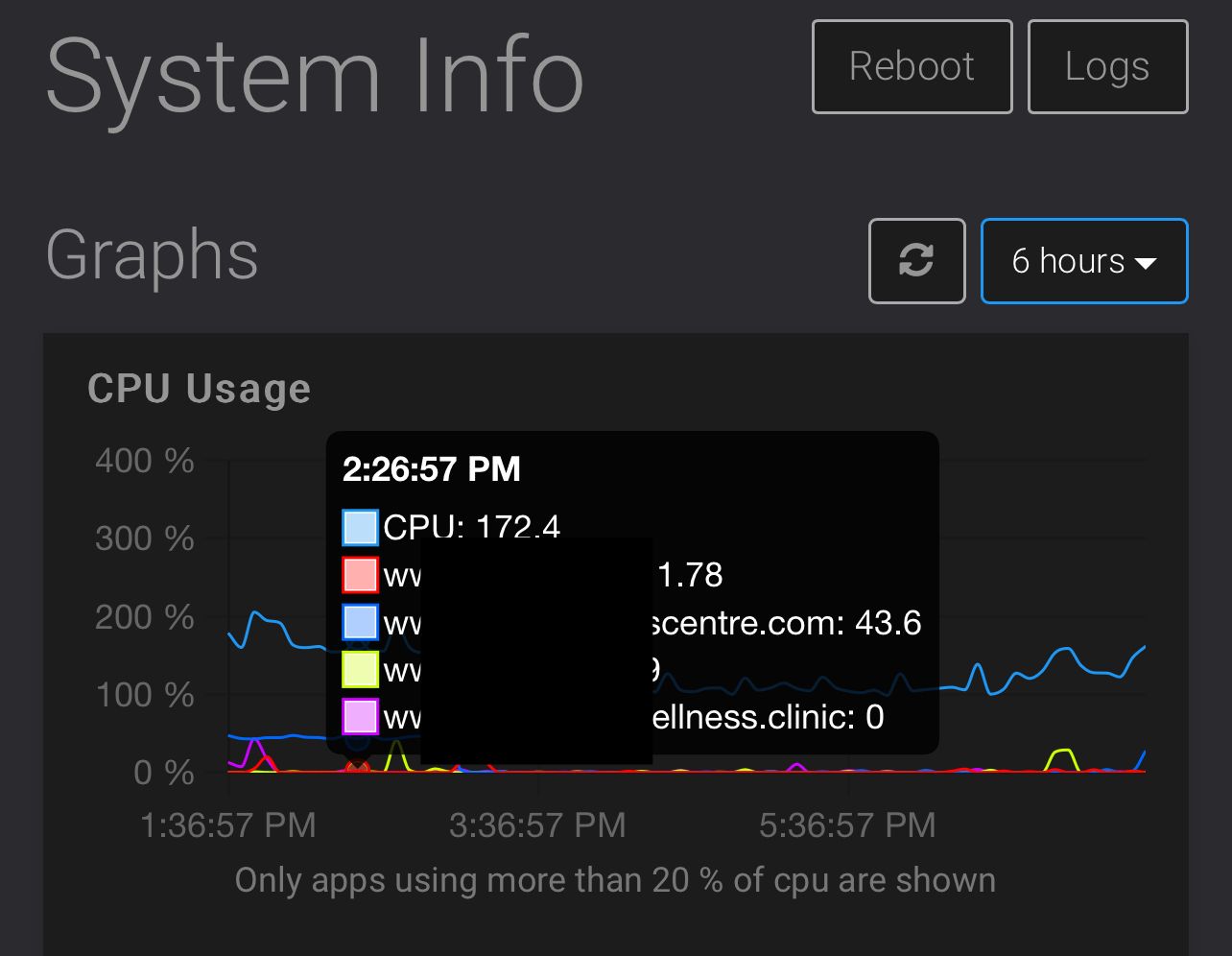
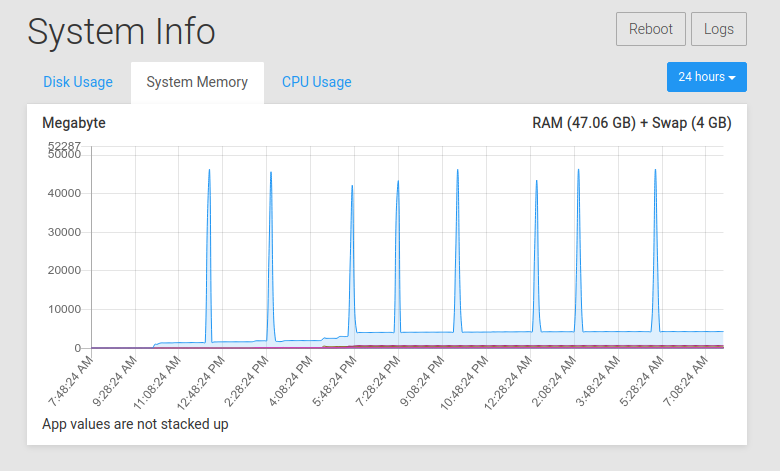
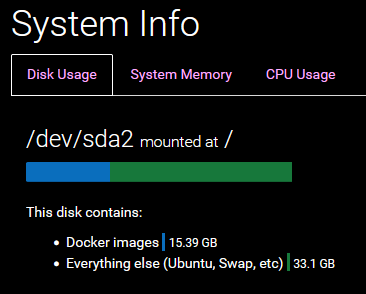
@mehdi said in Disk IO Tracker:
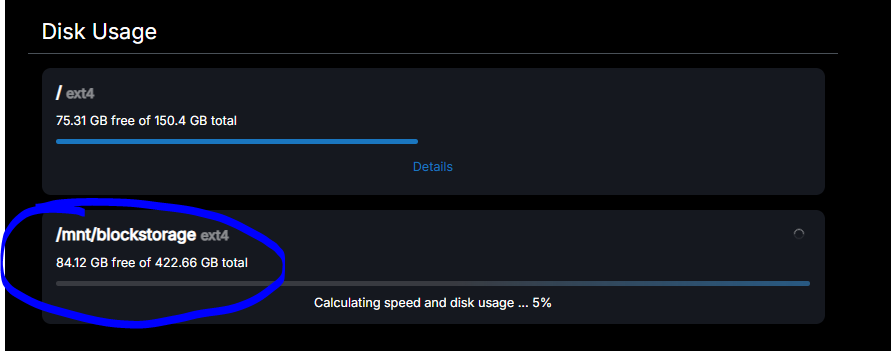
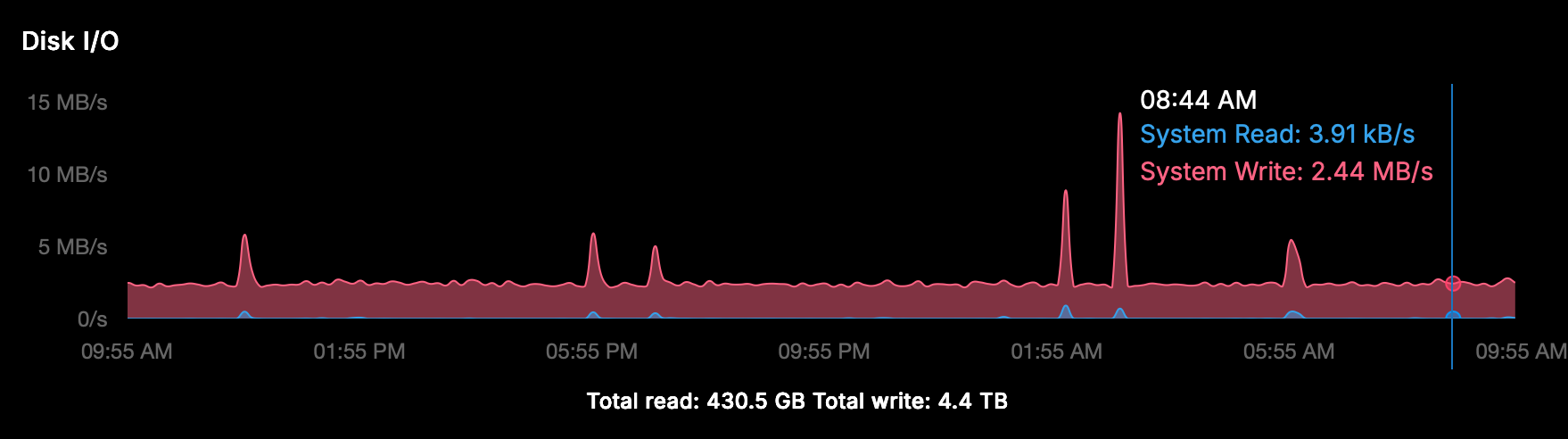
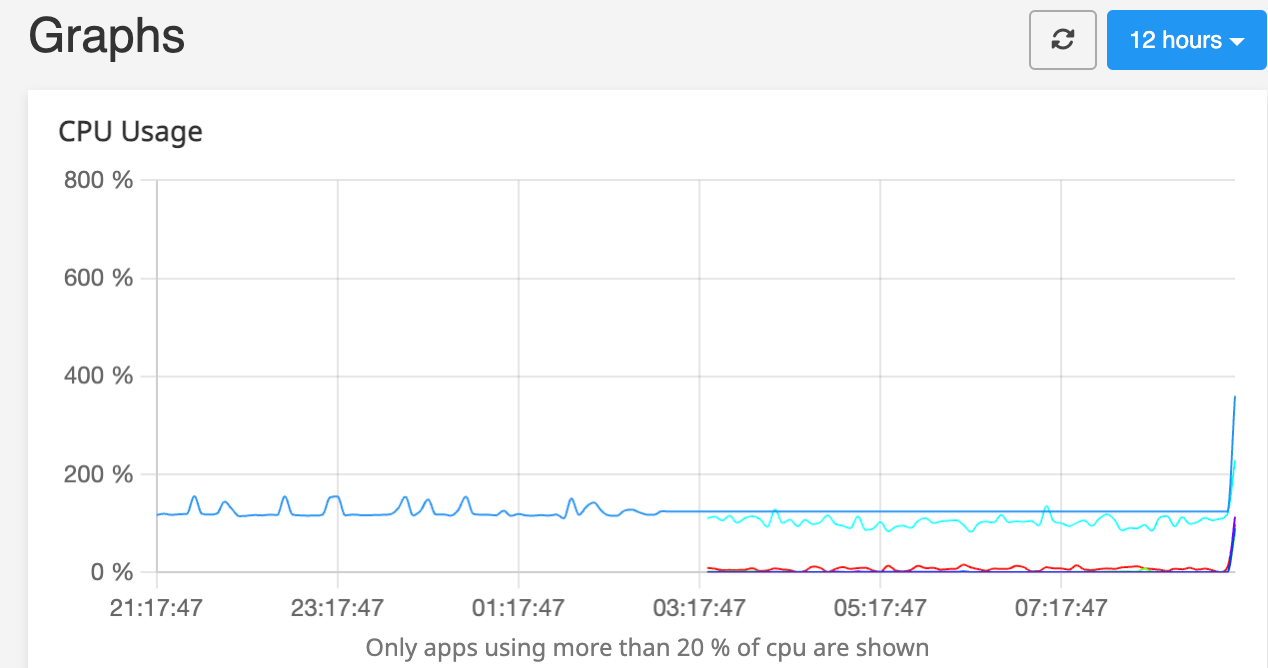
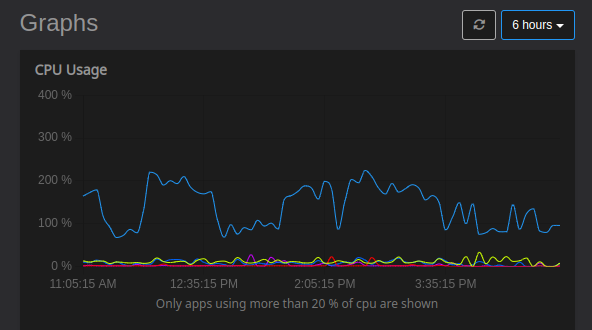
just trying to periodically write stuff and checking the performance, as suggested, would not be great IMO, as it would 1/ be influenced by what's already running on the system 2/ wear out SSDs for little benefit
Agreed, there are better ways, the example was more for the output or datapoints.
Aspects of BPF tools make this light on resources, but there's a whole stack of tools down the line, including 'iolatency'.