Since I added a storage volume to my infrastructure, I've been getting this backup error message very regularly
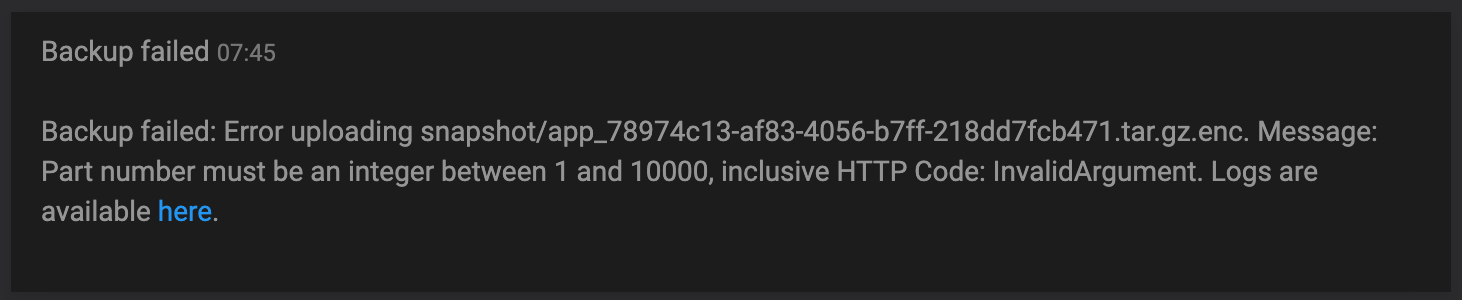
-
Please use the code tag for the log messages - they’re unreadable without.
@necrevistonnezr oh, my bad, i'll correct it rn. Thanks
-
I understand correctly: You’re trying a 100+ GB backup via an encrypted tar.gz archive of an Emby instance (which already contains highly compressed movie files, probably, that cannot be compressed further)?
-
I have something like 200gb of Emby data (and it's growing every day) you're right about that. On top we have a lot of music and a lot of youtube videos. Some files are in MP3 but the majority are in .WAV and for videos we're on .MP4.
Do you have any idea what I should do to be able to restore the backups system?
-
I’m also getting backup failed errors much more often lately. No volumes attached though. Backing up to backblaze. Latest fails happened two nights in a row on 5/23 and 5/24, worked fine on 5/25.
2024-05-23T05:06:29.143Z box:shell backup-snapshot/app_56523b4e-70f6-4323-98b9-559b87e74173: /usr/bin/sudo -S -E --close-from=4 /home/yellowtent/box/src/scripts/backupupload.js snapshot/app_56523b4e-70f6-4323-98b9-559b87e74173 tgz {"localRoot":"/home/yellowtent/appsdata/56523b4e-70f6-4323-98b9-559b87e74173","layout":[]} errored BoxError: backup-snapshot/app_56523b4e-70f6-4323-98b9-559b87e74173 exited with code 1 signal null 2024-05-23T05:06:29.148Z box:tasks setCompleted - 12664: {"result":null,"error":{"stack":"BoxError: Backuptask crashed\n at runBackupUpload (/home/yellowtent/box/src/backuptask.js:163:15)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)\n at async uploadAppSnapshot (/home/yellowtent/box/src/backuptask.js:360:5)\n at async backupAppWithTag (/home/yellowtent/box/src/backuptask.js:382:5)\n at async fullBackup (/home/yellowtent/box/src/backuptask.js:503:29)","name":"BoxError","reason":"Internal Error","details":{},"message":"Backuptask crashed"}} 2024-05-23T05:06:29.148Z box:taskworker Task took 381.54 seconds 2024-05-23T05:06:29.149Z box:tasks update 12664: {"percent":100,"result":null,"error":{"stack":"BoxError: Backuptask crashed\n at runBackupUpload (/home/yellowtent/box/src/backuptask.js:163:15)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)\n at async uploadAppSnapshot (/home/yellowtent/box/src/backuptask.js:360:5)\n at async backupAppWithTag (/home/yellowtent/box/src/backuptask.js:382:5)\n at async fullBackup (/home/yellowtent/box/src/backuptask.js:503:29)","name":"BoxError","reason":"Internal Error","details":{},"message":"Backuptask crashed"}} BoxError: Backuptask crashed@girish please see last section of the logs above in case there is indeed a bug in the code. However, I believe my issue is network related and differs from yours @Dont-Worry
-
I have something like 200gb of Emby data (and it's growing every day) you're right about that. On top we have a lot of music and a lot of youtube videos. Some files are in MP3 but the majority are in .WAV and for videos we're on .MP4.
Do you have any idea what I should do to be able to restore the backups system?
-
I have something like 200gb of Emby data (and it's growing every day) you're right about that. On top we have a lot of music and a lot of youtube videos. Some files are in MP3 but the majority are in .WAV and for videos we're on .MP4.
Do you have any idea what I should do to be able to restore the backups system?
@Dont-Worry said in Since I added a storage volume to my infrastructure, I've been getting this backup error message very regularly:
I have something like 200gb of Emby data (and it's growing every day) you're right about that. On top we have a lot of music and a lot of youtube videos. Some files are in MP3 but the majority are in .WAV and for videos we're on .MP4.
Using the encrypted tar backend for this mass of - already compressed - data is asking for trouble, IMHO. As girish pointed out, you end up with a single file of huge proportions, from the docs:
"The tgz format stores all the backup information in a single tarball whereas the rsync format stores all backup information as files inside a directory."
I could be wrong but many B2C providers will probably have difficulties supporting a 200 GB + file?!
-
Thank you for your answer @necrevistonnezr
@girish To answer your question, I am using AWS for backups. I tried to use OVH when the problem started but idk why i cant connect OVH Object Storage with my cloudron.@necrevistonnezr When you say "Using the encrypted tar backend for this mass of - already compressed - data is asking for trouble, IMHO.". I don't think 200gb is a huuuge mass of data (especially for AWS that is not a B2C focused provider). For our Company this is a little bit concerning if we cannot backup anything above 100gb.... Because we use cloudron for Entertainment (Emby), but also for business purposes (Files storages, apps ...) and we planned to use cloudron for long term purposes and forcasted more than 5 to 10 TB of data in a year. There is any way to Backup large amount of data w/cloudron in an automated way, as the system usually worked ?
-
Use the rsync backend?
-
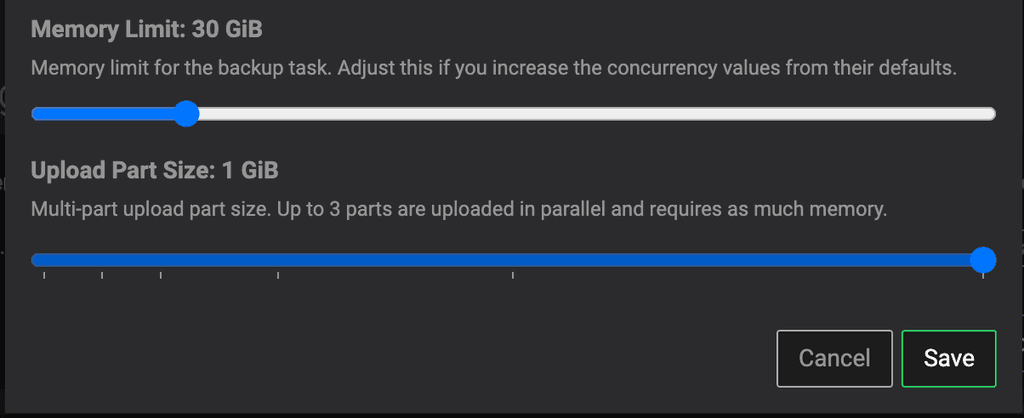
The problem has been solved. I have increased the size of the packages which are sent to the S3 and the whole was less than 10,000 packages so it was getting in. I read the documentation and really been over all my Cloudron panel many times, but I really didn't think about reviewing the advanced configurations of my backup, that is the thing I do not often change.
This solution works in the short term, but according to my calculations, once it reaches 10Tb, the maximum cut proposed by Cloudron, namely the cut by 1gb per package, will not be enough. Would it be possible to increase the maximum in the Cloudron application for people who use and consider Cloudron as a long-term mid-scale solution ?
This would not change anything if it was adjustable, but for people like us, who will have to deploy Cloudron on a powerful infrastructure, the double could be supported without any problem (2gb/Package).
-
The problem has been solved. I have increased the size of the packages which are sent to the S3 and the whole was less than 10,000 packages so it was getting in. I read the documentation and really been over all my Cloudron panel many times, but I really didn't think about reviewing the advanced configurations of my backup, that is the thing I do not often change.
This solution works in the short term, but according to my calculations, once it reaches 10Tb, the maximum cut proposed by Cloudron, namely the cut by 1gb per package, will not be enough. Would it be possible to increase the maximum in the Cloudron application for people who use and consider Cloudron as a long-term mid-scale solution ?
This would not change anything if it was adjustable, but for people like us, who will have to deploy Cloudron on a powerful infrastructure, the double could be supported without any problem (2gb/Package).
-
@Dont-Worry Thanks for the follow-up. Can you tell me which region of OVH Object Storage you are using?
@girish I am using Graveline for OVH Object Storage. First I choosed Roubaix, but it wasn't in the Cloudron list so I created a new bucket in Graveline. But it never worked. Now it is still working on the old AWS S3 bucket.
Didn't found any way to make the backup to an OVH bucket work. -
@girish I am using Graveline for OVH Object Storage. First I choosed Roubaix, but it wasn't in the Cloudron list so I created a new bucket in Graveline. But it never worked. Now it is still working on the old AWS S3 bucket.
Didn't found any way to make the backup to an OVH bucket work. -
@girish Can you please expand the doc page to cover what the "advanced settings" in the backups section offers and how they can be best used/optimized for a few use-cases like (general-use, heavy media use, etc.). Thank you!
@humptydumpty I think the issue is that there are too many providers, each with their own region. Back in the day, we hardcoded this and the advanced setting was not even exposed to the user because we thought it's impossible for the user to guess correct values. We ended up exposing the values because we couldn't figure a way to guess values . Even now, I have no concrete values to suggest for each provider, they keep changing (since upstream providers are also deploying updates) and each network/app/cpu is different. It's a bit of trial and error
 . But I will discuss internally and add something to the docs to help users.
. But I will discuss internally and add something to the docs to help users. -
 G girish has marked this topic as solved on
G girish has marked this topic as solved on
-
@Dont-Worry thanks, I have added RBX to the region list.
@girish Thank you very much !
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login