Backup fails due to long runtime - backup hangs
-
another point I want to emphasize:
in this scenario, even if the backup of all apps had been uploaded, the whole backup got thrown away, due to the missing last pieces/stall. its a complete loss of that backup-run.
in a scenario with independent incremental backups per app, at least these could have been saved, and only the last piece where missing. -
@nebulon said in Backup fails due to long runtime - backup hangs:
@chymian I am not sure about the specific issue and why the upload stalls at some point. This is strange indeed. Is there any throttling happening for incoming connections over time with your latest storage product?
no, it's working very well. did some heavy load test and it behaves very performant.
For the incremental backup, this is only supported using the "rsync" strategy. Depending on the backend, it either uses hardlinks or server side copying to avoid duplicate uploads.
I had made some not so good experiences with rsync to s3, it's more suited to a real FS, or do you have other experiences. what works best with rsync & hardlinks?
Generally our aim is to rather upload more than optimize for storage space as such.
to be on the safe side, I see. but there that also puts more load on the server, which is not really necessary.
We have had various discussions already about using systems like borg backup and such, but so far have always decided that we will not use them, since we are no experts on those systems and we are talking about backups, where it is sometimes require to have deep knowledge about how exactly backups are stored on the backend in order to restore from broken setups (which is of course one of the main use-cases for backups) Problem is, if anything gets corrupted in state with a more complex backup system, it is very or impossible to recover.
I see your point but at some point, an system architect/admin has always go into trust mode and test some new software to develop further, besides that, i.e. restic is battle-proofed.
and with the overall check & repair functions, this could enhance the whole backup-security/relaybility.Already the encrypted tarball backup has a similar drawback, where say a few blocks of that tarball are corrupted, it is impossible to recover the rest,
that could be seen as a call to find another solution.
as mentioned, I have no exp. with borg, but restic and bareos and these have a validation function – which tar-balls don't have – which gives an extra layer of reliability.so from our perspective the simpler to understand and recover, the better, with the drawback of maybe using more space or slower backups overall. It is a tradeoff.
philosopher could look horns about that - for sure.
")
there will be a time, when the old system just cannot keep up with the development and a change is needed.
one point is the pure amount of data which hast to be backed up.Regarding btrfs and zfs, we actually started out with btrfs long ago.…
However in the end we had to step away from it, since in our experience while it works 99% of the time, if it does not, you might end up with a corrupted filesystem AND corrupted backup snapshots.I had the same experiences with the early versions of BTRFS, but that's long ago.
meanwhile even proxmox, which is definitely more on the conservative side of system-setups, are using it in PVE 7.x
with a ext4, we will never know about bitrod!Which is the worst case for a backup system of course. Problem is also that those corruptions might be unnoticed for a long time.
a nightly/weekly
scrubcan easily find and if possible repair them
but in compare to zfs, a sysadmin had to setup these cron-jobs manually, which most people didn't do/know – me included, which would had saved me some trouble in these days…Further with regards to filesystems, we have seen VPS provider specific characteristics, which is why we essentially only rely on ext4 as the most stable one.
don't know what you are refering to?
but maybe xfs, which also gained snapshot-features lately, and has a much better reputation then BTRFS, will be a choice.is cloudron still strictly tied to ext4, or can it be installed on xfs, btrfs on own responsability?
Having said all this, I guess we have to debug your system in order to see why it doesn't work for you.
I figured out at least one point so far:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems. after monitoring the HD-throughput for a few days, I realized, there are times, when it goes down.
support fixed the for me yesterday, and at least last night the backup run for the first time in a week without pbls.
that leaves the point, why - lets say on an not so highly performance system – the backup stalls completely – after having transferred all data – for hours till it runs into timeout?
the log is here@chymian said in Backup fails due to long runtime - backup hangs:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems. after monitoring the HD-throughput for a few days, I realized, there are times, when it goes down.
It sounds to me like that is your primary issue right there, i.e. using an unreliable VPS provider, not really anything to do with Cloudron itself.
-
@chymian said in Backup fails due to long runtime - backup hangs:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems. after monitoring the HD-throughput for a few days, I realized, there are times, when it goes down.
It sounds to me like that is your primary issue right there, i.e. using an unreliable VPS provider, not really anything to do with Cloudron itself.
@jdaviescoates said in Backup fails due to long runtime - backup hangs:
It sounds to me like that is your primary issue right there, i.e. using an unreliable VPS provider, not really anything to do with Cloudron itself.
It's about resilience and recovery. It's a software issue.
-
@nebulon said in Backup fails due to long runtime - backup hangs:
@chymian I am not sure about the specific issue and why the upload stalls at some point. This is strange indeed. Is there any throttling happening for incoming connections over time with your latest storage product?
no, it's working very well. did some heavy load test and it behaves very performant.
For the incremental backup, this is only supported using the "rsync" strategy. Depending on the backend, it either uses hardlinks or server side copying to avoid duplicate uploads.
I had made some not so good experiences with rsync to s3, it's more suited to a real FS, or do you have other experiences. what works best with rsync & hardlinks?
Generally our aim is to rather upload more than optimize for storage space as such.
to be on the safe side, I see. but there that also puts more load on the server, which is not really necessary.
We have had various discussions already about using systems like borg backup and such, but so far have always decided that we will not use them, since we are no experts on those systems and we are talking about backups, where it is sometimes require to have deep knowledge about how exactly backups are stored on the backend in order to restore from broken setups (which is of course one of the main use-cases for backups) Problem is, if anything gets corrupted in state with a more complex backup system, it is very or impossible to recover.
I see your point but at some point, an system architect/admin has always go into trust mode and test some new software to develop further, besides that, i.e. restic is battle-proofed.
and with the overall check & repair functions, this could enhance the whole backup-security/relaybility.Already the encrypted tarball backup has a similar drawback, where say a few blocks of that tarball are corrupted, it is impossible to recover the rest,
that could be seen as a call to find another solution.
as mentioned, I have no exp. with borg, but restic and bareos and these have a validation function – which tar-balls don't have – which gives an extra layer of reliability.so from our perspective the simpler to understand and recover, the better, with the drawback of maybe using more space or slower backups overall. It is a tradeoff.
philosopher could look horns about that - for sure.
there will be a time, when the old system just cannot keep up with the development and a change is needed.
one point is the pure amount of data which hast to be backed up.Regarding btrfs and zfs, we actually started out with btrfs long ago.…
However in the end we had to step away from it, since in our experience while it works 99% of the time, if it does not, you might end up with a corrupted filesystem AND corrupted backup snapshots.I had the same experiences with the early versions of BTRFS, but that's long ago.
meanwhile even proxmox, which is definitely more on the conservative side of system-setups, are using it in PVE 7.x
with a ext4, we will never know about bitrod!Which is the worst case for a backup system of course. Problem is also that those corruptions might be unnoticed for a long time.
a nightly/weekly
scrubcan easily find and if possible repair them
but in compare to zfs, a sysadmin had to setup these cron-jobs manually, which most people didn't do/know – me included, which would had saved me some trouble in these days…Further with regards to filesystems, we have seen VPS provider specific characteristics, which is why we essentially only rely on ext4 as the most stable one.
don't know what you are refering to?
but maybe xfs, which also gained snapshot-features lately, and has a much better reputation then BTRFS, will be a choice.is cloudron still strictly tied to ext4, or can it be installed on xfs, btrfs on own responsability?
Having said all this, I guess we have to debug your system in order to see why it doesn't work for you.
I figured out at least one point so far:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems. after monitoring the HD-throughput for a few days, I realized, there are times, when it goes down.
support fixed the for me yesterday, and at least last night the backup run for the first time in a week without pbls.
that leaves the point, why - lets say on an not so highly performance system – the backup stalls completely – after having transferred all data – for hours till it runs into timeout?
the log is here@chymian said in Backup fails due to long runtime - backup hangs:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems.
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
-
@chymian said in Backup fails due to long runtime - backup hangs:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems.
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
@timconsidine said in Backup fails due to long runtime - backup hangs:
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.And I did not see that as well, when I did my tests, before I bought a server for longer time period.
They had been very perfomant and well behaving, if not I wouldn't have moved cloudron over.
within the history of 9 month now, the also moved all server to new HW, because the overall performance was to poor – all good and fresh again.
now, 5 month after that platform-upgrade, I had these throughput-issues. and as I said, support fixed that asap for me, after I opened a ticket.so it seems, the performance is "detoriating over time" - that was, why I said "tend to oversubscribe" the hosts.
I'm running test and will setup scripts for measurement, reporting back to me, and before I close the ticket, I try to get a granted throughput-rate for my server, to prevent that from happening again.
I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
setup is quit easy, CLDRN with some 20+ apps & about 16 - 20GB in syncthing & nextcloud to get longer transfers for bigger tar-files (which have not failed).
if the whole pbl. is throughput depended, one can mimic that by setting that up on a VM with throttled disk-troughput, down to 11MBs and back that up with tar to S3.
as my tests showed, it was "never" the target, who did cause the pbl. because the latest one at 1blu.de is fast and I have seen up to 60Mbps input-rate. the RAID6-HD shows up to 560MBs – so that server is not the bottleneck. but it still happened, before ssdnodes where tuning the VM-troughput.the transfer of the files you can see in my second post took around 12 - 15 h, then it stalled and timed out. in that time, CLDRN was still responding and working normally, even so it was slow.
-
@timconsidine said in Backup fails due to long runtime - backup hangs:
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.And I did not see that as well, when I did my tests, before I bought a server for longer time period.
They had been very perfomant and well behaving, if not I wouldn't have moved cloudron over.
within the history of 9 month now, the also moved all server to new HW, because the overall performance was to poor – all good and fresh again.
now, 5 month after that platform-upgrade, I had these throughput-issues. and as I said, support fixed that asap for me, after I opened a ticket.so it seems, the performance is "detoriating over time" - that was, why I said "tend to oversubscribe" the hosts.
I'm running test and will setup scripts for measurement, reporting back to me, and before I close the ticket, I try to get a granted throughput-rate for my server, to prevent that from happening again.
I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
setup is quit easy, CLDRN with some 20+ apps & about 16 - 20GB in syncthing & nextcloud to get longer transfers for bigger tar-files (which have not failed).
if the whole pbl. is throughput depended, one can mimic that by setting that up on a VM with throttled disk-troughput, down to 11MBs and back that up with tar to S3.
as my tests showed, it was "never" the target, who did cause the pbl. because the latest one at 1blu.de is fast and I have seen up to 60Mbps input-rate. the RAID6-HD shows up to 560MBs – so that server is not the bottleneck. but it still happened, before ssdnodes where tuning the VM-troughput.the transfer of the files you can see in my second post took around 12 - 15 h, then it stalled and timed out. in that time, CLDRN was still responding and working normally, even so it was slow.
-
@timconsidine said in Backup fails due to long runtime - backup hangs:
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.And I did not see that as well, when I did my tests, before I bought a server for longer time period.
They had been very perfomant and well behaving, if not I wouldn't have moved cloudron over.
within the history of 9 month now, the also moved all server to new HW, because the overall performance was to poor – all good and fresh again.
now, 5 month after that platform-upgrade, I had these throughput-issues. and as I said, support fixed that asap for me, after I opened a ticket.so it seems, the performance is "detoriating over time" - that was, why I said "tend to oversubscribe" the hosts.
I'm running test and will setup scripts for measurement, reporting back to me, and before I close the ticket, I try to get a granted throughput-rate for my server, to prevent that from happening again.
I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
setup is quit easy, CLDRN with some 20+ apps & about 16 - 20GB in syncthing & nextcloud to get longer transfers for bigger tar-files (which have not failed).
if the whole pbl. is throughput depended, one can mimic that by setting that up on a VM with throttled disk-troughput, down to 11MBs and back that up with tar to S3.
as my tests showed, it was "never" the target, who did cause the pbl. because the latest one at 1blu.de is fast and I have seen up to 60Mbps input-rate. the RAID6-HD shows up to 560MBs – so that server is not the bottleneck. but it still happened, before ssdnodes where tuning the VM-troughput.the transfer of the files you can see in my second post took around 12 - 15 h, then it stalled and timed out. in that time, CLDRN was still responding and working normally, even so it was slow.
-
@chymian what region is your ssdnodes data center ?
Just out of interest.
Mine is London.
I just realised that different data centers may invalidate comparison@timconsidine said in Backup fails due to long runtime - backup hangs:
@chymian what region is your ssdnodes data center ?
mine is in amsterdam.
-
@timconsidine said in Backup fails due to long runtime - backup hangs:
@chymian what region is your ssdnodes data center ?
mine is in amsterdam.
@chymian Looking at my backups :
- 44Gb on nextcloud primary instance
- 10Gb on nextcloud secondary instance
- 5Gb on a website
- all the rest <1Gb
- 67 apps total
- ~89Gb total being backed up
- start @ 2021-09-08T03:00:02
- nextcloud started @ 2021-09-08T03:04:06
- nextcloud complete @ 2021-09-08T04:23:21
- complete @ 2021-09-08T05:06:25
- cloudron on london ssdnode 32Gb RAM 400Gb disk
- backup destination scaleway (france paris)
I think I may have had a backup failure message in the past, but it's so long ago and so infrequent that I don't recall it.
I'm not a pro sysadmin but this seems very reasonable to me.
I really feel for you, because not having reliable backups can be gut wrenching, but as many have said, it doesn't look like a cloudron issue.
And I don't think it is an ssdnodes issue.Any non-cloudron apps installed on the cloudron box ?
Something which can interfere with the process ? -
@timconsidine said in Backup fails due to long runtime - backup hangs:
@chymian what region is your ssdnodes data center ?
mine is in amsterdam.
@timconsidine
I think your test just reflects the situation when everything is working as supposed.as I mentioned, to really check the situation when it was not working, one has to throttle a VM's throughput down to 11MB/s, as it was, when the "stalling-behavior" of cloudron's backup was seen. for every other situation, we know it's working.
after I had contact with support and they tinkered with the host, it's also working on my VM as supposed.
but this does not mean, there is not a SW-glitch/race-condition, or something else in CLDRN in that edge-case, which makes backup unreliable.I'm on the same page as @robi mentioned here
It's about resilience and recovery. It's a software issue.
@nebulon, at the moment I don't have a dedi-host available to replicate that issue, nor that I would have enough time – sry.
but I have little script running per cron every 15min to check the throughput, to have a statistic at hand, when it happens again. In the last 6 days, it shows values between 45 - 85 MB/s, with an average of 71MB/s on 520 values.
which is somehow ok.cat /usr/local/bin/do_troughput_test#!/bin/bash # test disk-trougput with dd SOURCE=/root/throughput-testfile.img TARGET=/tmp/test.img LOG=/root/throughput-statistics.txt [ -f $SOURCE ] || { printf "No source file $SOURCE found, creating one\n" dd if=/dev/urandom of=$SOURCE bs=1024 count=5M status=none printf " done\n" } # clear caches echo "Clearing cache" echo 3 > /proc/sys/vm/drop_caches echo "removing target" rm -f $TARGET date | tee -a $LOG /usr/bin/time -a -o $LOG dd if=$SOURCE of=$TARGET bs=1024 count=5M conv=fdatasync,notrunc 2>&1 |grep -v records | tee -a $LOG -
I just backup (about 135GB in total) to a Hetzner Storage Box and I've never had any problems.
@jdaviescoates said in Backup fails due to long runtime - backup hangs:
I just backup (about 135GB in total) to a Hetzner Storage Box and I've never had any problems.
Until now.
Last night's backup is still running over 12 hours later (I just realised because I went to update an app and it said waiting for backup to finish...)
Seems like the logs is just this repeating forever from 03:22 until now:
2022-09-15T03:22:04.330Z box:shell backup-snapshot/app_737de757-d2b6-4357-ad48-2b3b33ce982d (stdout): 2022-09-15T03:22:04.329Z box:backupupload process: rss: 98.36MB heapUsed: 23.7MB heapTotal: 26.33MB external: 1.13MB@staff help!
")
-
@avatar1024 said in What do you use for your VPS?:
@jdaviescoates I had backup failing in the past and it was due to an issue with cifs mounting in some rare cases with Cloudron. Never had a problem since using a sshfs mount for backups.
Thanks. Turns out I'm not using CIFS mount any more either, but I'm using a mount point (Edit: ah, but I am still using CIFS, I just have the relevant stuff in /etc/fstab which using CIFS to mount my Storage Box to /mnt/backup)
In the end I just stopped the backup and restarted it again and it went smoothly so possibly just a small glitch somewhere...
-
@avatar1024 said in What do you use for your VPS?:
@jdaviescoates I had backup failing in the past and it was due to an issue with cifs mounting in some rare cases with Cloudron. Never had a problem since using a sshfs mount for backups.
Thanks. Turns out I'm not using CIFS mount any more either, but I'm using a mount point (Edit: ah, but I am still using CIFS, I just have the relevant stuff in /etc/fstab which using CIFS to mount my Storage Box to /mnt/backup)
In the end I just stopped the backup and restarted it again and it went smoothly so possibly just a small glitch somewhere...
@jdaviescoates You know, every single time I've had a backup glitch, on Cloudron and other platforms, I've always been able to trace it back to a character in a filename that the system did not like. Sometimes tracking that down took awhile, and it didn't always happen, but when it did, it was a funky odd character. Maybe it might be your situation, especially if you are backing up files which you've gotten elsewhere, like music, ebooks, other media files that already had their filenames.
A life lived in fear is a life half-lived
-
@jdaviescoates You know, every single time I've had a backup glitch, on Cloudron and other platforms, I've always been able to trace it back to a character in a filename that the system did not like. Sometimes tracking that down took awhile, and it didn't always happen, but when it did, it was a funky odd character. Maybe it might be your situation, especially if you are backing up files which you've gotten elsewhere, like music, ebooks, other media files that already had their filenames.
@scooke thanks but I don't think that's the case this time. It hung whilst doing a so far completely unused install of Moodle that has no content, and then worked fine next time ( took about 40 seconds to do that app next time). Worked fine again last night too.
My guess is a small network glitch somewhere or something.
-
Are there any insights or resulutions to this? Also am trying (for the 3rd time) to transfer a NextCloud-backup from a Public-Cloud Server to an on-prem instance at a client. Backup Size about 300 GB. The transfer initiates just fine but after a while just seems to get "stuck" at "64M@0MBps" Download speed for hours even though I can test that the connection exists and even run some small load-tests to check that transfer is possible.
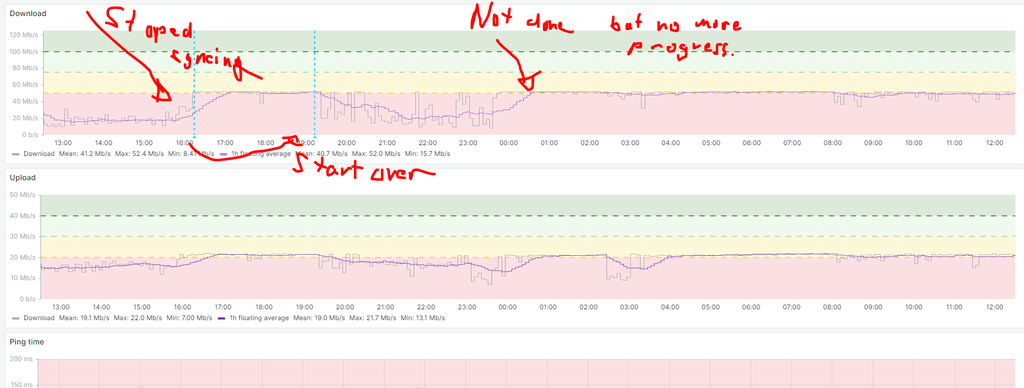
Is there some way to restart the import in append mode? After all it tried to import via rsync form a Backup. However if I restart the import it starts over again ignoring all the progress/downloads made before.
And advise here how to get the situation un-stuck?
At this point I'd even be ok with manually rsync-ing the contents of the App to the new system and then just rebuilding the App there from scratch.