Backup fails due to long runtime - backup hangs
-
@chymian said in Backup fails due to long runtime - backup hangs:
the server is hosted with ssdnodes.com and the tend to oversubscribe there systems.
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
@timconsidine said in Backup fails due to long runtime - backup hangs:
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.And I did not see that as well, when I did my tests, before I bought a server for longer time period.
They had been very perfomant and well behaving, if not I wouldn't have moved cloudron over.
within the history of 9 month now, the also moved all server to new HW, because the overall performance was to poor – all good and fresh again.
now, 5 month after that platform-upgrade, I had these throughput-issues. and as I said, support fixed that asap for me, after I opened a ticket.so it seems, the performance is "detoriating over time" - that was, why I said "tend to oversubscribe" the hosts.
I'm running test and will setup scripts for measurement, reporting back to me, and before I close the ticket, I try to get a granted throughput-rate for my server, to prevent that from happening again.
I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
setup is quit easy, CLDRN with some 20+ apps & about 16 - 20GB in syncthing & nextcloud to get longer transfers for bigger tar-files (which have not failed).
if the whole pbl. is throughput depended, one can mimic that by setting that up on a VM with throttled disk-troughput, down to 11MBs and back that up with tar to S3.
as my tests showed, it was "never" the target, who did cause the pbl. because the latest one at 1blu.de is fast and I have seen up to 60Mbps input-rate. the RAID6-HD shows up to 560MBs – so that server is not the bottleneck. but it still happened, before ssdnodes where tuning the VM-troughput.the transfer of the files you can see in my second post took around 12 - 15 h, then it stalled and timed out. in that time, CLDRN was still responding and working normally, even so it was slow.
-
@timconsidine said in Backup fails due to long runtime - backup hangs:
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.And I did not see that as well, when I did my tests, before I bought a server for longer time period.
They had been very perfomant and well behaving, if not I wouldn't have moved cloudron over.
within the history of 9 month now, the also moved all server to new HW, because the overall performance was to poor – all good and fresh again.
now, 5 month after that platform-upgrade, I had these throughput-issues. and as I said, support fixed that asap for me, after I opened a ticket.so it seems, the performance is "detoriating over time" - that was, why I said "tend to oversubscribe" the hosts.
I'm running test and will setup scripts for measurement, reporting back to me, and before I close the ticket, I try to get a granted throughput-rate for my server, to prevent that from happening again.
I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
setup is quit easy, CLDRN with some 20+ apps & about 16 - 20GB in syncthing & nextcloud to get longer transfers for bigger tar-files (which have not failed).
if the whole pbl. is throughput depended, one can mimic that by setting that up on a VM with throttled disk-troughput, down to 11MBs and back that up with tar to S3.
as my tests showed, it was "never" the target, who did cause the pbl. because the latest one at 1blu.de is fast and I have seen up to 60Mbps input-rate. the RAID6-HD shows up to 560MBs – so that server is not the bottleneck. but it still happened, before ssdnodes where tuning the VM-troughput.the transfer of the files you can see in my second post took around 12 - 15 h, then it stalled and timed out. in that time, CLDRN was still responding and working normally, even so it was slow.
-
@timconsidine said in Backup fails due to long runtime - backup hangs:
I just signed up for some servers at ssdnodes.
Their prices are very aggressive so what you say makes sense.
However I am not seeing those problems so far in the time I have been with them.And I did not see that as well, when I did my tests, before I bought a server for longer time period.
They had been very perfomant and well behaving, if not I wouldn't have moved cloudron over.
within the history of 9 month now, the also moved all server to new HW, because the overall performance was to poor – all good and fresh again.
now, 5 month after that platform-upgrade, I had these throughput-issues. and as I said, support fixed that asap for me, after I opened a ticket.so it seems, the performance is "detoriating over time" - that was, why I said "tend to oversubscribe" the hosts.
I'm running test and will setup scripts for measurement, reporting back to me, and before I close the ticket, I try to get a granted throughput-rate for my server, to prevent that from happening again.
I might have a bash at replicating what you're doing and see if I can get similar issues.
But I am not familiar with the detail of what you're doing, so will need to review the messages here.Feel free to post your outline setup and I will have a bash at replicating to see if similar experience. Anything to narrow down the problem.
setup is quit easy, CLDRN with some 20+ apps & about 16 - 20GB in syncthing & nextcloud to get longer transfers for bigger tar-files (which have not failed).
if the whole pbl. is throughput depended, one can mimic that by setting that up on a VM with throttled disk-troughput, down to 11MBs and back that up with tar to S3.
as my tests showed, it was "never" the target, who did cause the pbl. because the latest one at 1blu.de is fast and I have seen up to 60Mbps input-rate. the RAID6-HD shows up to 560MBs – so that server is not the bottleneck. but it still happened, before ssdnodes where tuning the VM-troughput.the transfer of the files you can see in my second post took around 12 - 15 h, then it stalled and timed out. in that time, CLDRN was still responding and working normally, even so it was slow.
@chymian what region is your ssdnodes data center ?
Just out of interest.
Mine is London.
I just realised that different data centers may invalidate comparisonIndie app dev, huge fan of Cloudron PaaS, scratching my itches : communityapps.appx.uk
-
@chymian what region is your ssdnodes data center ?
Just out of interest.
Mine is London.
I just realised that different data centers may invalidate comparison@timconsidine said in Backup fails due to long runtime - backup hangs:
@chymian what region is your ssdnodes data center ?
mine is in amsterdam.
-
@timconsidine said in Backup fails due to long runtime - backup hangs:
@chymian what region is your ssdnodes data center ?
mine is in amsterdam.
@chymian Looking at my backups :
- 44Gb on nextcloud primary instance
- 10Gb on nextcloud secondary instance
- 5Gb on a website
- all the rest <1Gb
- 67 apps total
- ~89Gb total being backed up
- start @ 2021-09-08T03:00:02
- nextcloud started @ 2021-09-08T03:04:06
- nextcloud complete @ 2021-09-08T04:23:21
- complete @ 2021-09-08T05:06:25
- cloudron on london ssdnode 32Gb RAM 400Gb disk
- backup destination scaleway (france paris)
I think I may have had a backup failure message in the past, but it's so long ago and so infrequent that I don't recall it.
I'm not a pro sysadmin but this seems very reasonable to me.
I really feel for you, because not having reliable backups can be gut wrenching, but as many have said, it doesn't look like a cloudron issue.
And I don't think it is an ssdnodes issue.Any non-cloudron apps installed on the cloudron box ?
Something which can interfere with the process ? -
@timconsidine said in Backup fails due to long runtime - backup hangs:
@chymian what region is your ssdnodes data center ?
mine is in amsterdam.
@timconsidine
I think your test just reflects the situation when everything is working as supposed.as I mentioned, to really check the situation when it was not working, one has to throttle a VM's throughput down to 11MB/s, as it was, when the "stalling-behavior" of cloudron's backup was seen. for every other situation, we know it's working.
after I had contact with support and they tinkered with the host, it's also working on my VM as supposed.
but this does not mean, there is not a SW-glitch/race-condition, or something else in CLDRN in that edge-case, which makes backup unreliable.I'm on the same page as @robi mentioned here
It's about resilience and recovery. It's a software issue.
@nebulon, at the moment I don't have a dedi-host available to replicate that issue, nor that I would have enough time – sry.
but I have little script running per cron every 15min to check the throughput, to have a statistic at hand, when it happens again. In the last 6 days, it shows values between 45 - 85 MB/s, with an average of 71MB/s on 520 values.
which is somehow ok.cat /usr/local/bin/do_troughput_test#!/bin/bash # test disk-trougput with dd SOURCE=/root/throughput-testfile.img TARGET=/tmp/test.img LOG=/root/throughput-statistics.txt [ -f $SOURCE ] || { printf "No source file $SOURCE found, creating one\n" dd if=/dev/urandom of=$SOURCE bs=1024 count=5M status=none printf " done\n" } # clear caches echo "Clearing cache" echo 3 > /proc/sys/vm/drop_caches echo "removing target" rm -f $TARGET date | tee -a $LOG /usr/bin/time -a -o $LOG dd if=$SOURCE of=$TARGET bs=1024 count=5M conv=fdatasync,notrunc 2>&1 |grep -v records | tee -a $LOG -
I just backup (about 135GB in total) to a Hetzner Storage Box and I've never had any problems.
@jdaviescoates said in Backup fails due to long runtime - backup hangs:
I just backup (about 135GB in total) to a Hetzner Storage Box and I've never had any problems.
Until now.
Last night's backup is still running over 12 hours later (I just realised because I went to update an app and it said waiting for backup to finish...)
Seems like the logs is just this repeating forever from 03:22 until now:
2022-09-15T03:22:04.330Z box:shell backup-snapshot/app_737de757-d2b6-4357-ad48-2b3b33ce982d (stdout): 2022-09-15T03:22:04.329Z box:backupupload process: rss: 98.36MB heapUsed: 23.7MB heapTotal: 26.33MB external: 1.13MB@staff help!
")
-
@avatar1024 said in What do you use for your VPS?:
@jdaviescoates I had backup failing in the past and it was due to an issue with cifs mounting in some rare cases with Cloudron. Never had a problem since using a sshfs mount for backups.
Thanks. Turns out I'm not using CIFS mount any more either, but I'm using a mount point (Edit: ah, but I am still using CIFS, I just have the relevant stuff in /etc/fstab which using CIFS to mount my Storage Box to /mnt/backup)
In the end I just stopped the backup and restarted it again and it went smoothly so possibly just a small glitch somewhere...
-
@avatar1024 said in What do you use for your VPS?:
@jdaviescoates I had backup failing in the past and it was due to an issue with cifs mounting in some rare cases with Cloudron. Never had a problem since using a sshfs mount for backups.
Thanks. Turns out I'm not using CIFS mount any more either, but I'm using a mount point (Edit: ah, but I am still using CIFS, I just have the relevant stuff in /etc/fstab which using CIFS to mount my Storage Box to /mnt/backup)
In the end I just stopped the backup and restarted it again and it went smoothly so possibly just a small glitch somewhere...
@jdaviescoates You know, every single time I've had a backup glitch, on Cloudron and other platforms, I've always been able to trace it back to a character in a filename that the system did not like. Sometimes tracking that down took awhile, and it didn't always happen, but when it did, it was a funky odd character. Maybe it might be your situation, especially if you are backing up files which you've gotten elsewhere, like music, ebooks, other media files that already had their filenames.
A life lived in fear is a life half-lived
-
@jdaviescoates You know, every single time I've had a backup glitch, on Cloudron and other platforms, I've always been able to trace it back to a character in a filename that the system did not like. Sometimes tracking that down took awhile, and it didn't always happen, but when it did, it was a funky odd character. Maybe it might be your situation, especially if you are backing up files which you've gotten elsewhere, like music, ebooks, other media files that already had their filenames.
@scooke thanks but I don't think that's the case this time. It hung whilst doing a so far completely unused install of Moodle that has no content, and then worked fine next time ( took about 40 seconds to do that app next time). Worked fine again last night too.
My guess is a small network glitch somewhere or something.
-
Are there any insights or resulutions to this? Also am trying (for the 3rd time) to transfer a NextCloud-backup from a Public-Cloud Server to an on-prem instance at a client. Backup Size about 300 GB. The transfer initiates just fine but after a while just seems to get "stuck" at "64M@0MBps" Download speed for hours even though I can test that the connection exists and even run some small load-tests to check that transfer is possible.
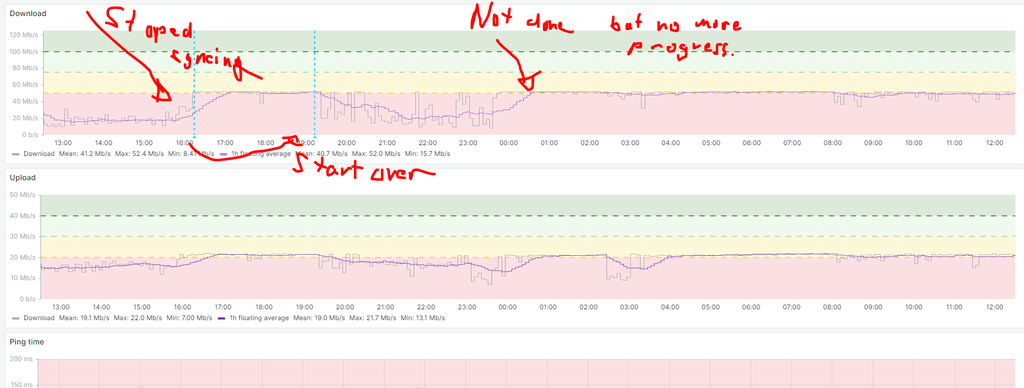
Is there some way to restart the import in append mode? After all it tried to import via rsync form a Backup. However if I restart the import it starts over again ignoring all the progress/downloads made before.
And advise here how to get the situation un-stuck?
At this point I'd even be ok with manually rsync-ing the contents of the App to the new system and then just rebuilding the App there from scratch.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login