Has anyone used v10.1.0?
-
@girish
Thank you for your prompt response!
I will confirm it immediately. -
@portfield-slash yes, please. it's important to re-install and not update. Cloudron does not have code to update the redis provisioning from password to no-password.
-
@girish
I checked it immediately, but it doesn't seem to work.I have updated the details in Issue, so can you check it?
-
@portfield-slash it looks like you tried to update your existing instance? Did you install a new instance of redash? The update won't work.
@girish
After uninstalling with Cloudron's GUI, I also installed with GUI.
I have Cloudron installed on AWS EC2. Do I need to rebuild EC2? -
@girish
After uninstalling with Cloudron's GUI, I also installed with GUI.
I have Cloudron installed on AWS EC2. Do I need to rebuild EC2?@portfield-slash no, the app reinstall should do so it pulls in the new base image.
-
@portfield-slash no, the app reinstall should do so it pulls in the new base image.
@robi
Thank you for your reply.The Docker container was recreated, so it doesn't seem to be a problem.
-
@girish
After uninstalling with Cloudron's GUI, I also installed with GUI.
I have Cloudron installed on AWS EC2. Do I need to rebuild EC2?@portfield-slash no need to rebuild EC2/server. Are you able to reproduce this on our test server - https://my.demo.cloudron.io (username: cloudron password: cloudron) ?
-
@portfield-slash no need to rebuild EC2/server. Are you able to reproduce this on our test server - https://my.demo.cloudron.io (username: cloudron password: cloudron) ?
@girish When I try to create an instance of Redash on that demo cloudron instance it gets stuck in a starting state and never progresses past that and I can see in the log that the workers keep restarting:
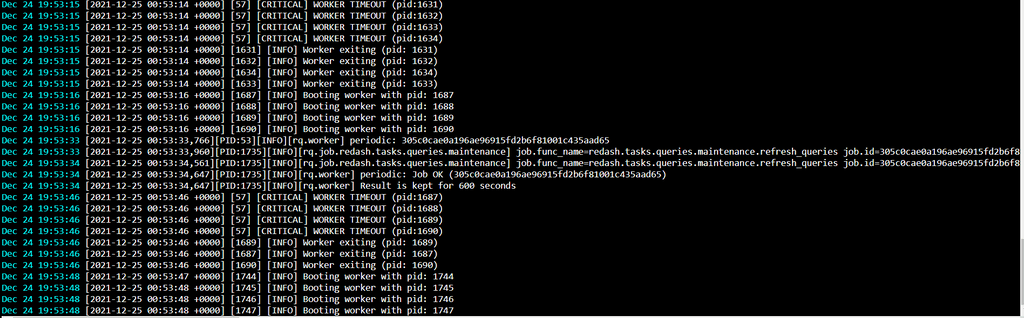
Not sure this is related to the problem at hand as I don't have this issue when install Redash on my own instance of cloudron.
-
@girish When I try to create an instance of Redash on that demo cloudron instance it gets stuck in a starting state and never progresses past that and I can see in the log that the workers keep restarting:
Not sure this is related to the problem at hand as I don't have this issue when install Redash on my own instance of cloudron.
@christophermag indeed, I can see that as well. It looks like there is some difference between the Cloudron versions. I am installing on latest dev where it seems to work fine but not on the stable release (7.0.4) which the demo and you guys are on. I will test on 7.0.4.
-
@christophermag indeed, I can see that as well. It looks like there is some difference between the Cloudron versions. I am installing on latest dev where it seems to work fine but not on the stable release (7.0.4) which the demo and you guys are on. I will test on 7.0.4.
-
I think
WORKER TIMEOUTis a gunicorn error.Add the
--timeoutparameter in the gunicorn settings and
Avoided the timeout by reloading the supervisor inside the container.I don't think it is recommended to change the settings in the container, so I think it is necessary to deal with it as a separate matter.
/etc/supervisor/conf.d/redash.conf
[program:web] directory=/app/code/redash command=/app/code/redash/bin/run gunicorn -b 0.0.0.0:5000 --name redash -w 4 --max-requests 1000 --timeout 300 redash.wsgi:app process_name=server user=cloudron numprocs=1 autostart=true autorestart=true stdout_logfile=/dev/stdout stdout_logfile_maxbytes=0 stderr_logfile=/dev/stderr stderr_logfile_maxbytes=0run
sudo supervisorctl reloadcommand. -
@ChristopherMag @portfield-slash I get the WORKER TIMEOUT error as well.
13:51:16 - [2022-01-11 21:51:16 +0000] [46] [CRITICAL] WORKER TIMEOUT (pid:64)It seems this is because the
queriesqueue is not processed at all. Per https://github.com/getredash/redash/blob/d8d7c78992e44a4b6d7fdd4c39ccc1c35cd8c7a9/redash/worker.py#L20 , they are many named queues . The Cloudron package only processes "periodic emails default" queues. I am struggling to find any docs or deployment code in redash that will help understand what the correct fix is. -
Making some progress here:
- https://github.com/getredash/redash/issues/5625
- https://github.com/getredash/redash/issues/5620
- https://discuss.redash.io/t/query-auto-update-does-not-work-redash-v10/9353
The issue is that we don't even process scheduled_queries because of pacakge mis-configuration. What the fix is, I am investigating.
-
 G girish referenced this topic on
G girish referenced this topic on
-
@ChristopherMag @portfield-slash I have pushed an update, can you please check? Atleast, I am now able to query sqlite files just fine. Also, seeing all the queued jobs being processed. The new package version is 4.0.0-1 (so, it has the same changelog as 4.0.0, in case you get confused)
-
@girish
Thank you for your support. I will confirm.It was confirmed that the connection test was successful.
I have also confirmed that I can execute queries.Thank you for your support.
If necessary, I will report on github that the event has been resolved.

-
@ChristopherMag @portfield-slash I have pushed an update, can you please check? Atleast, I am now able to query sqlite files just fine. Also, seeing all the queued jobs being processed. The new package version is 4.0.0-1 (so, it has the same changelog as 4.0.0, in case you get confused)
@girish I have updated and been using everything for the last two days and it has been working as expected. Good to go from me, thank you!