We have started getting random repositories / users appear in our gitea instance, eg "AccidentInjuryLawyers". Before that, we had a sofa company. It looks like spam, I have to keep deleting them. How to prevent such signups?
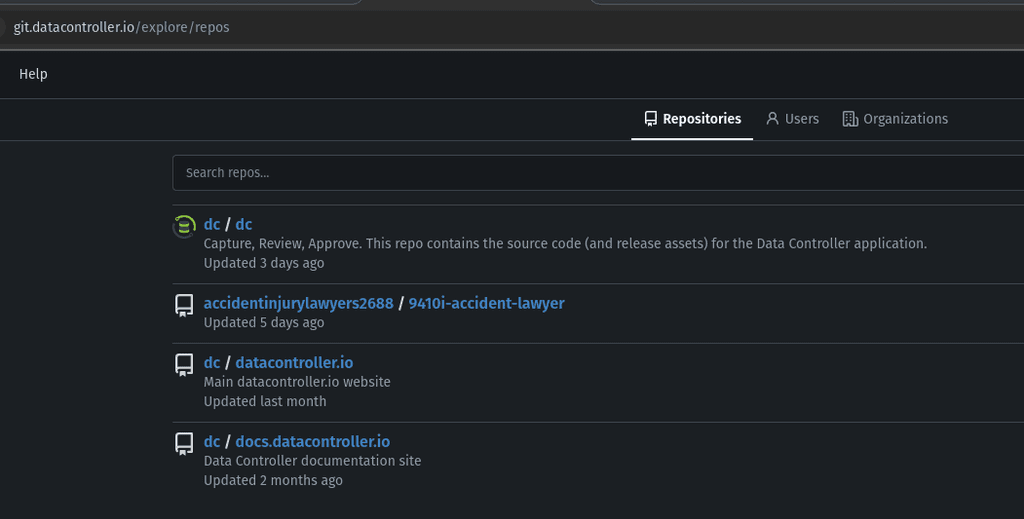
We have started getting random repositories / users appear in our gitea instance, eg "AccidentInjuryLawyers". Before that, we had a sofa company. It looks like spam, I have to keep deleting them. How to prevent such signups?
I found the logs - they were inside the container at /home/git/gitlab/log
Running grep -i "failed" revealed that the attack started in the early morning of 20th June. Somehow the list of usernames was known (probably relates to the issue in the link in my previous post) and signin requests are being made from random ip addresses.
First 5 entries shown below (this pattern has continued since):
./application_json.log:{"severity":"INFO","time":"2025-07-20T03:17:13.349Z","correlation_id":"xxx","meta.caller_id":"SessionsController#create","meta.feature_category":"system_access","meta.organization_id":1,"meta.remote_ip":"156.146.59.50","meta.client_id":"ip/156.146.59.50","message":"Failed Login: username=xxx1 ip=156.146.59.50"}
./application_json.log:{"severity":"INFO","time":"2025-07-20T03:18:20.163Z","correlation_id":"xxx","meta.caller_id":"SessionsController#create","meta.feature_category":"system_access","meta.organization_id":1,"meta.remote_ip":"193.176.84.35","meta.client_id":"ip/193.176.84.35","message":"Failed Login: username=xxx2 ip=193.176.84.35"}
./application_json.log:{"severity":"INFO","time":"2025-07-20T03:18:39.636Z","correlation_id":"xxx","meta.caller_id":"SessionsController#create","meta.feature_category":"system_access","meta.organization_id":1,"meta.remote_ip":"20.205.138.223","meta.client_id":"ip/20.205.138.223","message":"Failed Login: username=xxxx3 ip=20.205.138.223"}
./application_json.log:{"severity":"INFO","time":"2025-07-20T03:19:04.255Z","correlation_id":"xxx","meta.caller_id":"SessionsController#create","meta.feature_category":"system_access","meta.organization_id":1,"meta.remote_ip":"98.152.200.61","meta.client_id":"ip/98.152.200.61","message":"Failed Login: username=xxx4 ip=98.152.200.61"}
./application_json.log:{"severity":"INFO","time":"2025-07-20T03:21:03.314Z","correlation_id":"xxx","meta.caller_id":"SessionsController#create","meta.feature_category":"system_access","meta.organization_id":1,"meta.remote_ip":"200.34.32.138","meta.client_id":"ip/200.34.32.138","message":"Failed Login: username=xxx5 ip=200.34.32.138"}
Today our cloudron instance (on a hetzner dedicated machine) became unresponsive, both to web and ssh requests
Power cycling did not help. Booting into recovery mode, the last lines of the box.log are as follows:
2024-03-18T05:29:50.217Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:30:00.005Z box:disks checkDiskSpace: checking disk space
2024-03-18T05:30:00.042Z box:janitor Cleaning up expired tokens
2024-03-18T05:30:00.044Z box:eventlog cleanup: pruning events. creationTime: Tue Dec 19 2023 05:30:00 GMT+0000 (Coordinated Universal Time)
2024-03-18T05:30:00.046Z box:tasks startTask - starting task 6699 with options {}. logs at /home/yellowtent/platformdata/logs/tasks/6699.log
2024-03-18T05:30:00.046Z box:shell startTask spawn: /usr/bin/sudo -S -E /home/yellowtent/box/src/scripts/starttask.sh 6699 /home/yellowtent/platformdata/logs/tasks/6699.log 0 400
2024-03-18T05:30:00.054Z box:janitor Cleaned up 0 expired tokens
2024-03-18T05:30:00.126Z box:shell startTask (stderr): Running as unit: box-task-6699.service
2024-03-18T05:30:00.400Z box:disks checkDiskSpace: disk space checked. out of space: no
2024-03-18T05:30:00.431Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:30:10.217Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:30:20.210Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:30:30.215Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:30:40.208Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:30:50.202Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:31:00.211Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:31:10.202Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:31:20.227Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:31:25.823Z box:shell startTask (stderr): Finished with result: success
Main processes terminated with: code=exited/status=0
Service runtime: 1min 25.708s
CPU time consumed: 6.591s
2024-03-18T05:31:25.829Z box:shell startTask (stdout): Service box-task-6699 finished with exit code 0
2024-03-18T05:31:25.831Z box:tasks startTask: 6699 completed with code 0
2024-03-18T05:31:25.833Z box:tasks startTask: 6699 done. error: null
2024-03-18T05:31:30.205Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:31:40.216Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:31:50.204Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:32:00.209Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:32:10.220Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:32:20.208Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
2024-03-18T05:32:30.216Z box:apphealthmonitor app health: 43 running / 2 stopped / 0 unresponsive
df output:
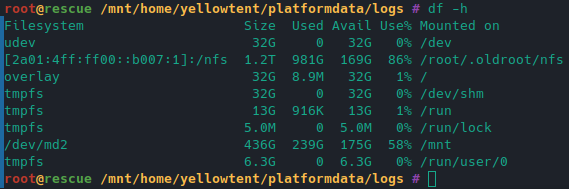
Any idea how we can further troubleshoot?
So it appears that unauthenticated users (or attackers) are able to brute force usernames due to the fact that the corresponding API endpoints are not authenticated: https://gitlab.com/gitlab-org/gitlab/-/issues/297473
Furthermore, the gitlab team do not plan to fix the issue:
To mitigate the risk from such attacks in the future we took the following measures:
Actions taken on the server:
Actions taken on the platform (cloudron):
Actions taken on the gitlab instance (cloudron container):
Suggestions (to the packaging team) for improvement:
/home/git/gitlab/log). Maybe even putting that location in the file explorer, to make log capture / analysis easier.Finally got things working again after taking the following steps:
Asking Hetzner to replace the machine (not drives) - although this didn't fix the issue, and may have been unnecessary
Opening the rescue system and running fsck -fy /dev/md2 per this guide: https://docs.hetzner.com/robot/dedicated-server/troubleshooting/filesystem-check
This seemed to fix a load of disk issues and now everything is running fine.
Just discovered a setting at the following path: /admin/application_settings/general#js-visibility-settings
Section: Restricted visibility levels
Setting: Public - If selected, only administrators are able to create public groups, projects, and snippets. Also, profiles are only visible to authenticated users.
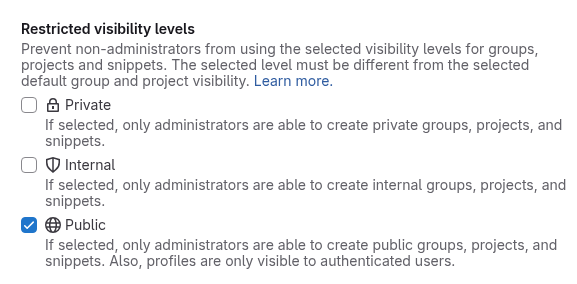
After checking this, and testing with CURL, the /api/v4/users/XXX endpoints now consistently return a 404 whether authenticated or not!!
I suspect this is the fix, but will wait and see if there are any more "Unlock Instructions" emails tonight / tomorrow.
Weirdly, after checking this checkbox and hitting save, it gets unchecked immediately after - but refreshing the page shows that it was indeed checked.
Another side note - we saw in our email logs that we were getting a large number of requests from a subdomain of https://academyforinternetresearch.org/
So it seems that this could be an issue on their radar.
Actually - I was able to fix this by taking two actions:
API keys now generate successfully.
Edit: it's definitely jitsi in Matrix, this is what we were presented with for our 3 way (successful) video call, with screen sharing:

Was just stock cloudron matrix, using the stock cloudron element web client on the customer side of the call.
We could not do a successful 3-way video call with this same customer, on the same browser, using the stock standalone cloudron jitsi instance.
We're on cloudron 7.2.5
We would love to see the following:
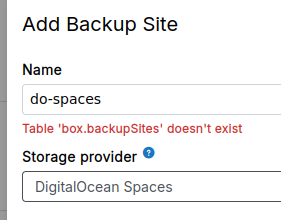
Our cloudron updated to v9 automatically, and ever since we've been getting "Table 'box.backupSites' doesn't exist" in our logs
The /backup-sites endpoint just spins (previous backup config not displayed) and when I try to add a new backup location we again get the error "Table 'box.backupSites' doesn't exist"
How to fix?
Thankyou! This fixed it up.
Running v1.104.4 since 5 days ago. Suddenly a large number of ourGitlab users have received the message below (both cloudron and external login accounts). There are no failed signin attempts in the log, that I can see. Did anyone else have this issue?
From: GitLab git.app@xxxx
Sent: xxxx
To: xxxxx
Subject: Unlock instructions
GitLab
Hello, xxxx!
Your GitLab account has been locked due to an excessive number of unsuccessful sign in attempts. You can wait for your account to automatically unlock in 10 minutes or you can click the link below to unlock now.
Unlock account
If you did not initiate these sign-in attempts, please reach out to your administrator or enable two-factor authentication (2FA) on your account.
--troubleshoot gave everything as "ok"
however:
root@my ~ # cloudron-support --check-db-migration
/usr/bin/cloudron-support: unrecognized option '--check-db-migration'
Running the start.sh fixed the backups page issue, and now the updates appear to be running (and the error is gone)
thankyou!
I found this thread which implies that it is a known issue in gitlab: https://gitlab.com/gitlab-org/gitlab/-/issues/297473
It was from my user but I also did this with one of the locked users and it was the same result (only shows successful logins). This was after the restart.
@oj the problem with the cloudron jitsi install is the lack of a TURN server, which means it is not possible to have video calls with customers on enterprise platforms (that require traffic over 443)
So, any major customer basically.