That worked @girish
cloudron-support --troubleshoot found a certificate which does not exist and so removed a conf file
nginx started promptly
After which the Cloudron apps could be restarted just fine
Thank you once again for your help
T
THI_Staff
@THI_Staff
Posts
-
Nginx reverseproxy error after Cloudron upgrade to v8.3.1; Cloudron apps running but can't be stopped/restarted -
Nginx reverseproxy error after Cloudron upgrade to v8.3.1; Cloudron apps running but can't be stopped/restartedUnderstood @girish I'll give that a try Monday morning UK time
I'm always cautious with these kind of things to avoid surprised, but sometimes you've just got to try things out and then work forward to fix things -
Nginx reverseproxy error after Cloudron upgrade to v8.3.1; Cloudron apps running but can't be stopped/restartedI can do @girish But what's the impact of that? Stopping nginx will presumably take all our websites down for a period? And after re-running cloundron-support --troubleshoot and seeing the new output, presumably I then run systemctl start nginx to restart all websites, right? Though there is some inherent risk here by stopping nginx because it's at server level. I need to check with the customer about the timing of this test / troubleshooting exercise; doing this at the weekend might not suit, Monday might be better
Thank you again; I appreciate your support and advice
-
Nginx reverseproxy error after Cloudron upgrade to v8.3.1; Cloudron apps running but can't be stopped/restartedPS: The log file /var/log/nginx/error.log has these 2 interesting lines:
2025/04/10 01:10:00 [emerg] 1665953#1665953: cannot load certificate "/home/yellowtent/platformdata/nginx/cert/_.<our_website>.<our_cloudron_domain>.cert": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/home/yellowtent/platformdata/nginx/cert/_.<our_website>.<our_cloudron_domain>.cert','r') error:2006D080:BIO routines:BIO_new_file:no such file) 2025/04/10 11:45:13 [error] 3689898#3689898: *2550325 open() "/home/yellowtent/box/dashboard/dist/.git/config" failed (2: No such file or directory), client: <IP_address>, server: my.<our_cloudron_domain>, request: "GET /.git/config HTTP/1.1", host: "my.<our_cloudron_domain>"No other errors / entries to suggest why the reported error happens.
-
Nginx reverseproxy error after Cloudron upgrade to v8.3.1; Cloudron apps running but can't be stopped/restarted@nebulon Thank you for that.
Looks good to me. Though not sure about the 2 "To Be Filled By O.E.M.", should they be actual values?
root@server:~# cloudron-support --troubleshoot Vendor: To Be Filled By O.E.M. Product: To Be Filled By O.E.M. Linux: 5.4.0-148-generic Ubuntu: focal 20.04 Processor: AMD Ryzen 5 5600X 6-Core Processor x 12 RAM: 65814680KB Disk: /dev/md0 414G [OK] node version is correct [OK] IPv6 is enabled in kernel. No public IPv6 address [OK] docker is running [OK] docker version is correct [OK] MySQL is running [OK] nginx is running [OK] dashboard cert is valid [OK] dashboard is reachable via loopback [OK] box v8.3.1 is running [OK] netplan is good [OK] DNS is resolving via systemd-resolved [OK] Dashboard is reachable via domain name Domain <our_cloudron_domain> expiry check skipped because whois is not installed. Run 'apt install whois' to check [OK] unbound is runningAfter logging on via SSH I was greeted by this:
1 updates could not be installed automatically. For more details, see /var/log/unattended-upgrades/unattended-upgrades.log *** System restart required ***That log file includes this interesting line:
2025-04-02 05:36:52,930 WARNING Could not figure out development release: Distribution data outdated. Please check for an update for distro-info-data. See /usr/share/doc/distro-info-data/README.Debian for details.Forums on the net, like this one https://askubuntu.com/questions/1489441/unattended-upgrade-message-could-not-figure-out-development-release-distributi, cover the same point and suggest the following:
You need to upgrade just that one package distro-info-data, as in: sudo apt install --only-upgrade distro-info-data. I encountered this too in a 22.04 server setup similar to yours (keeps up only with security updates). Turns out the warning message is exactly what it says, that is, we just needed to check for an update to distro-info-data and install it if available. The issue, if you could call it that, was that the necessary update was only published in version 0.52ubuntu0.5 on Oct 24, after this question was asked, and two weeks or so after the warning started appearing in servers like yours and mine.Is that worthwhile doing? I'm not a Ubuntu expert, but common sense says it can only help. Saying that our platform version is v8.3.1 (Ubuntu 20.04 TLS - not 22.04).
The 1 update from unattended-upgrades.log which could not be automatically installed could be this:
2025-04-10 06:15:21,756 INFO Package shim-signed is kept back because a related package is kept back or due to local apt_preferences(5).Re: "System restart required", our server uptime is 2 years, so clearly I've not done a restart since taking over looking after this VPS (virtual private server).
Any thoughts please? Thank you again.
THI Staff
-
Nginx reverseproxy error after Cloudron upgrade to v8.3.1; Cloudron apps running but can't be stopped/restartedHi All
Could you help with the following issue please?
Short version
Following a successful Cloudron platform upgrade, all our apps now display the following error:
Error : Nginx Error - Error reloading nginx: reverseproxy exited with code 1 signal nullThe apps / services run ok; the only issues are 1) no backups were taken since the Cloudron platform upgrade, likely due to the app error status and 2) the apps can't be stopped / restarted likely due to the same error.
The underlying cause must be related to certificates, I would guess, so upon checking the renew certificates log I found these telling lines:
Apr 08 02:15:47 box:shell nginx: [emerg] cannot load certificate "/home/yellowtent/platformdata/nginx/cert/_.<our_website>.<our_cloudron_domain>.cert": BIO_new_file() failed (SSL: error:02001002:system library:fopen:No such file or directory:fopen('/home/yellowtent/platformdata/nginx/cert/_.<our_website>.<our_cloudron_domain>.cert','r') error:2006D080:BIO routines:BIO_new_file:no such file) Apr 08 02:15:47 box:shell reverseproxy: /usr/bin/sudo -S /home/yellowtent/box/src/scripts/restartservice.sh nginx errored BoxError: reverseproxy exited with code 1 signal null Apr 08 02:15:47 at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:137:19) Apr 08 02:15:47 at ChildProcess.emit (node:events:519:28) Apr 08 02:15:47 at ChildProcess._handle.onexit (node:internal/child_process:294:12) { Apr 08 02:15:47 reason: 'Shell Error', Apr 08 02:15:47 details: {}, Apr 08 02:15:47 code: 1, Apr 08 02:15:47 signal: null Apr 08 02:15:47 } Apr 08 02:15:47 box:taskworker Task took 347.55 seconds Apr 08 02:15:47 box:tasks setCompleted - 8714: {"result":null,"error":{"stack":"BoxError: Error reloading nginx: reverseproxy exited with code 1 signal null\n at reload (/home/yellowtent/box/src/reverseproxy.js:188:22)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)\n at async checkCerts (/home/yellowtent/box/src/reverseproxy.js:698:9)","name":"BoxError","reason":"Nginx Error","details":{},"message":"Error reloading nginx: reverseproxy exited with code 1 signal null"}}Interestingly <our_website> is the only domain set up with manual DNS configuration in Cloudron, but this has been the case for years and it worked/works, until the latest Cloudron platform upgrade. But sure, the renew certificates log above is correct, there is no cert file at /home/yellowtent/platformdata/nginx/cert/_.<our_website>.<our_cloudron_domain>.cert but it should not be looking for one locally on our server, should it?
Longer version
The Cloudron platform upgrade from v8.2.4 to v8.3.1 was successful on 29/03/2025. Our last Cloudron app backups are from 29/03/2025 as well.Our Cloudron apps now have a status of:
Error : Nginx Error - Error reloading nginx: reverseproxy exited with code 1 signal nullStarting up development instances of Cloudron apps (which are not running normally) gets a status of "Starting - Configuring reverse proxy", which after it sticks around for way too long, errors out with the same message as above. Trying to repair the app with the "Retry start app task" leads nowhere other than the same error being displayed again. And we can't stop any of these apps either, but they are nevertheless running.
All the renew certificates logs since 29/03/2025 have an error red x next to them; the relevant log output is mentioned above. Why is the reverse proxy getting stuck looking for the certificate of <our_website> which we have on manual DNS setup in Cloudron? And how do we tell it to not check this certificate any more? I'm guessing this is where the issue is.
Funny enough, according to the Cloudron event log, the certificate install for www.<our_website> succeeded on 01/04/2025 (proving the manual DNS setup has worked for years), this is 3 days after the Cloudron platform upgrade on 29/03/2025 but obviously the reverse proxy doesn't know / isn't happy with the certificate for <our_website> for whatever reason.
Can you advise how we fix this please? Thank you in advance.
THI Staff
-
WordPress app container stuck on updating from package version 3.7.2 to 3.7.3@girish said in WordPress app container stuck on updating from package version 3.7.2 to 3.7.3:
This happens with apps which contains files that change their size when the backup is going on. ... Maybe you have some plugin that writes to somewhere periodically?
Thank you @girish Great advice and just the clue we needed. We figured out what that was, stopped it and then we could take a WP backup manually; and then we were also able to update to the latest packaged WP version 3.8.0
Thank you once again; your prompt help is much appreciated
You can mark this ticket as resolved; cheers!
")
-
WordPress app container stuck on updating from package version 3.7.2 to 3.7.3Thank you @joseph for your reply
I did that; clicked on X to stop the current upgrade process (stuck on backing up); went to repair and clicked Retry task to get the app container back to a healthy, non-error state.
But... what it gets stuck on is the backup process; I tried twice to create a new backup and the process gets stuck at the same exact point 4304M into the backup, which I guess you must have expected would happen and why you suggested taking a server snapshot and then "skipping the backup" when I try upgrading the WP container to the next release. I guess you must also be hoping that post a successful update to the next packaged WP releases, the backup process will start working again, right? Is this common behaviour / have you seen this before with other apps and their upgrades?
-
PeerTube not responding after successful upgrade to v2.17.0Thank you @nebulon for your reply
I cloned another PeerTube app from a v2.16.0 backup, it upgraded ok to v2.17.0 but this instance gets stuck on Starting
Some lines from the Logs which seem relevant
Jul 18 23:11:41 2024-07-18 22:11:41,764 CRIT Supervisor is running as root. Privileges were not dropped because no user is specified in the config file. If you intend to run as root, you can set user=root in the config file to avoid this message...
Jul 18 23:11:41 ==> Changing ownership
Jul 18 23:11:41 Could not connect to Redis at redis-d6625bc3-17a7-40ec-9b21-50eb3bf74b7e:6379: Connection refused
Jul 18 23:11:43 2024-07-18 22:11:43,973 INFO success: redis entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)<30>1 2024-07-18T22:11:43Z server redis-d6625bc3-17a7-40ec-9b21-50eb3bf74b7e 189870 redis-d6625bc3-17a7-40ec-9b21-50eb3bf74b7e - 2024-07-18 22:11:43,973 INFO success: redis-service entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
Jul 18 23:11:47 ==> Installing OIDC plugin
...
Jul 18 23:11:48 [<domain-name-removed>.com:443] 2024-07-18 22:11:48.518 info: Installing plugin peertube-plugin-auth-openid-connect.
Jul 18 23:11:50 => Healtheck error: Error: connect ECONNREFUSED 172.18.18.171:80
Jul 18 23:11:50 [<domain-name-removed>.com:443] 2024-07-18 22:11:50.438 error: Cannot install plugin peertube-plugin-auth-openid-connect, removing it... { <30>1 2024-07-18T22:11:50Z server d6625bc3-17a7-40ec-9b21-50eb3bf74b7e 189870 d6625bc3-17a7-40ec-9b21-50eb3bf74b7e - "err": { <30>1 2024-07-18T22:11:50Z server d6625bc3-17a7-40ec-9b21-50eb3bf74b7e 189870 d6625bc3-17a7-40ec-9b21-50eb3bf74b7e - "err": {
Jul 18 23:11:50 "stack": "Error: Command failed: yarn add peertube-plugin-auth-openid-connect@0.1.1\nwarning package.json: No license field\nwarning No license field\nerror /app/data/storage/plugins/node_modules/ffi-napi: Command failed.Eventually it gets to this part:
Jul 18 23:13:17 => Healtheck error: Error: Timeout of 7000ms exceeded
Jul 18 23:13:27 => Healtheck error: Error: Timeout of 7000ms exceeded
Jul 18 23:13:37 => Healtheck error: Error: Timeout of 7000ms exceeded
Jul 18 23:13:43 => Healtheck error: Error: connect EHOSTUNREACH 172.18.18.171:80
Jul 18 23:13:53 => Healtheck error: Error: connect EHOSTUNREACH 172.18.18.171:80
Jul 18 23:14:03 => Healtheck error: Error: connect EHOSTUNREACH 172.18.18.171:80Not sure where to take this next; no point restoring the original PeerTube app back to the v2.16.0 backup and upgrade again to v2.17.0 which is did successfully (and so did the new cloned instance); clearly something in v2.17.0 doesn't agree with however PeerTube is configured or what plugins we have running.
-
PeerTube not responding after successful upgrade to v2.17.0Hi guys,
I have another query if you could help please.
A PeerTube app "container" we use on Cloudron to host some training videos upgraded successfully from v2.16.0 to v2.17.0 and some hours later its status is Not responding as opposed to the healthy Running status.
We did a Restart App and also a stop and start in case this is different than a restart and still same outcome, Not responding.
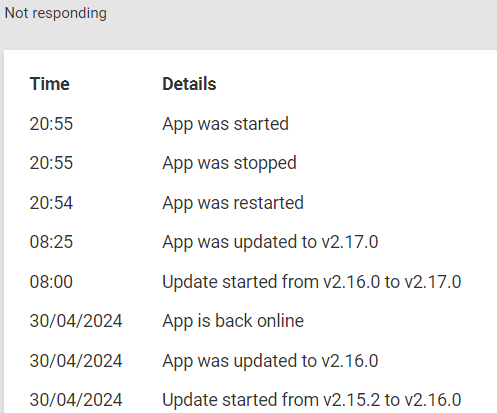
There are some errors in the logs, quite a few hours after the successful upgrade; quite detailed information, so I've just pulled out the following which seems relevant (and was quoted on other posts on this forum):
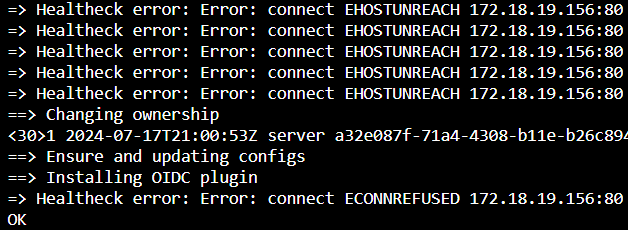
Any ideas how we fix this please? I haven't yet tried enabling the recovery mode, I thought I'd ask for help first as the app failure is not something we generated through use of the video platform or indeed any configuration of it.
Thank you in advance.
Ovidiu
-
WordPress app container stuck on updating from package version 3.7.2 to 3.7.3The above may be linked to Cloudron update to v8.0.1 as detailed here:
https://forum.cloudron.io/post/91544But still, there must be a way to break the vicious update cycle on the WordPress app "container" because when I go into Settings, under Updates and I click the Updates Available button it tells me there are apps blocking the Cloudron update and I should wait for these operations to finish first:

-
What's coming in 8.0@girish said in What's coming in 8.0:
w00t, I have fixed the long-standing issue of backups getting stuck (usually, it would says @0Mbps) . Fix is in 8.0.1 (not released).
@girish Bingo! We might be affected by that very issue: backups getting stuck @0Mbps (in the middle of a managed WP version upgrade, all be it a minor upgrade)
Just logged this ticket
https://forum.cloudron.io/topic/12123/wordpress-app-container-stuck-on-updating-from-package-version-3-7-2-to-3-7-3If the fix is to upgrade to Cloudron v8.0.1, I'll need to look at that because just like @eddowding we are currently running v7.7.2 (due to our, let's say, lack of human resources and time)
Thank you, guys! Great forum and community here, and not for the first time!
-
WordPress app container stuck on updating from package version 3.7.2 to 3.7.3Hi guys,
Could you assist with the following please?
We run a number of WordPress "app" websites on Cloudron, all but one have updated successfully to package version 3.7.5. One website, our main one, hasn't and I've just noticed it's been trying and failing to update from 3.7.2 to 3.7.3 daily for a few weeks.
The app is currently stuck on:

We can't stop the app (print screen does not capture the "not allowed" mouse cursor when hovering over the Off button):
Nor can we use any of the buttons on the Repair tab, likely due to the app being in the middle of trying to update the packaged WP version:
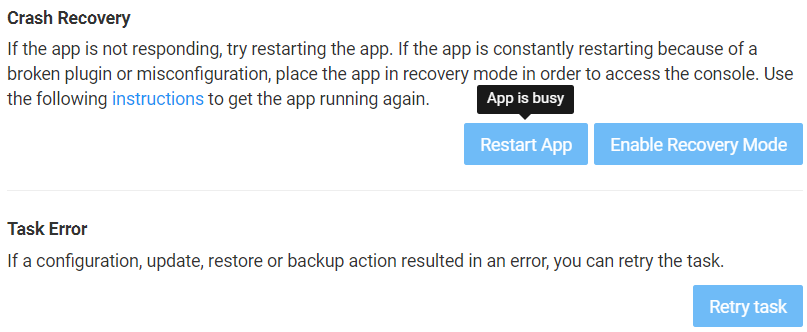
Nor can we take a fresh backup of the website, which is up and working despite the following message:
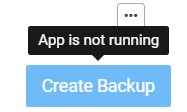
On the Cloudron My App home page we see the app is Updating:
It started the update process probably over 12 hours ago, it will fail at some point and then start again; it looks as follows:
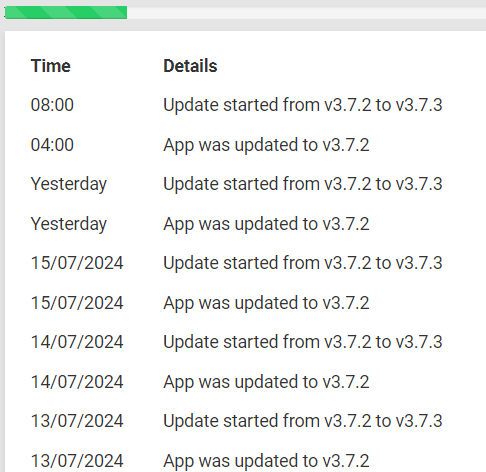
How do we safely break the vicious cycle please?
Incidentally, I see we also have a notification for Cloudron v8.0.1 being available; a Reboot required notification is also present to finish the Ubuntu security updates; I was under the impression that these reboots happen automatically, but maybe they don't and we have to initiate them manually as our uptime show as "a year" and our platform version is v7.7.2.
Your help, advice and guidance are much appreciated.
Thank you in advance.
THI Staff
-
Invalid website certificateFor future readers, the error was that the domain was not hosted on GoDaddy

Correct; we were hosted on GoDaddy, but created a subdomain for another website, which we moved to another hosting company, we moved the domain there in the process and then forgot to update the Cloudron domain setup to change the provider from GoDaddy to Cloudflare.
Great support by the way, I must say; I work in IT support myself, but web hosting is not my main expertise
-
Invalid website certificate@girish All sorted; schoolboy error on my part. Thank you again
-
Invalid website certificateI've just sent an email with the supporting information to support@cloudron.io
Thank you in advance -
Invalid website certificatePerfect, thank you @girish I saw that drop down, all items are green, but did not click on any of them; will do and then email you guys.
-
Invalid website certificate@girish Thank you very much for your prompt reply
Where are these certificate logs please? If you can advise please, I shall collect them and send an email to the address you provided
Thank you again -
Invalid website certificateHi Cloudron guys and forum
One of our website certificates is failing to renew; we have 2 websites hosted on Cloudron, both with the same setup, both on GoDaddy, one is fine, the other isn't (expired certificate error).
We renewed all certificates manually in Cloudron 3 times today, the Renew section shows all green, yet under the Event log we can see the certificate for one of the website is failing to renew / apply.
This is something for Cloudron to fix, right? And how do we log a formal support call with Cloudron as I really don't want to share sensitive details here?
Thank you all.
THI Staff
-
Some emails going to spam@luckow Thinking about it, maybe it was Postal that I came across before and didn't save that webpage; it certainly wasn't on postalserver.io, the webpage had a different design and look and feel, but the content and complexity of the technical setup seems pretty similar; thank you again.