Serge - LLaMa made easy 🦙 - self-hosted AI Chat
-
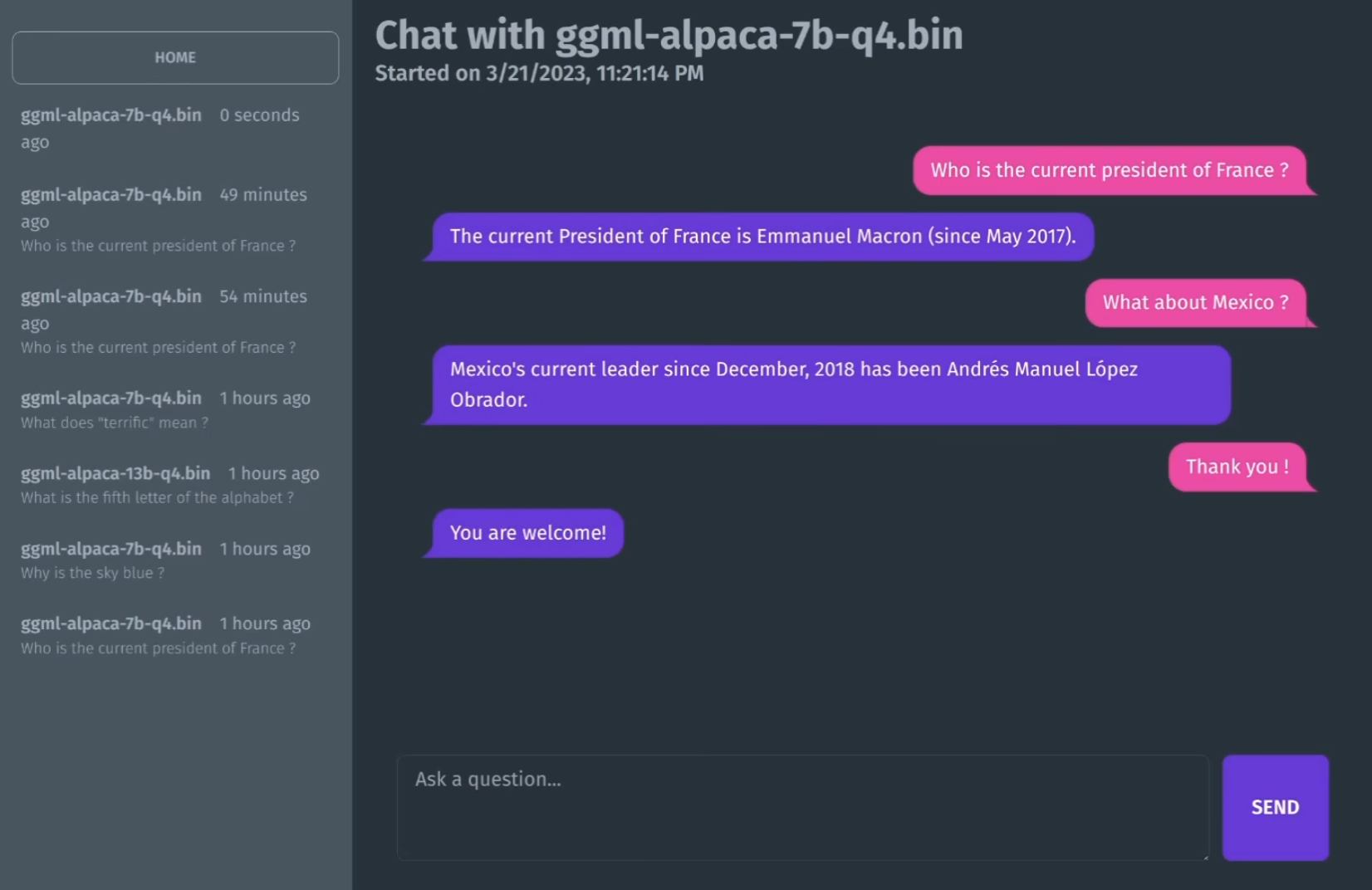
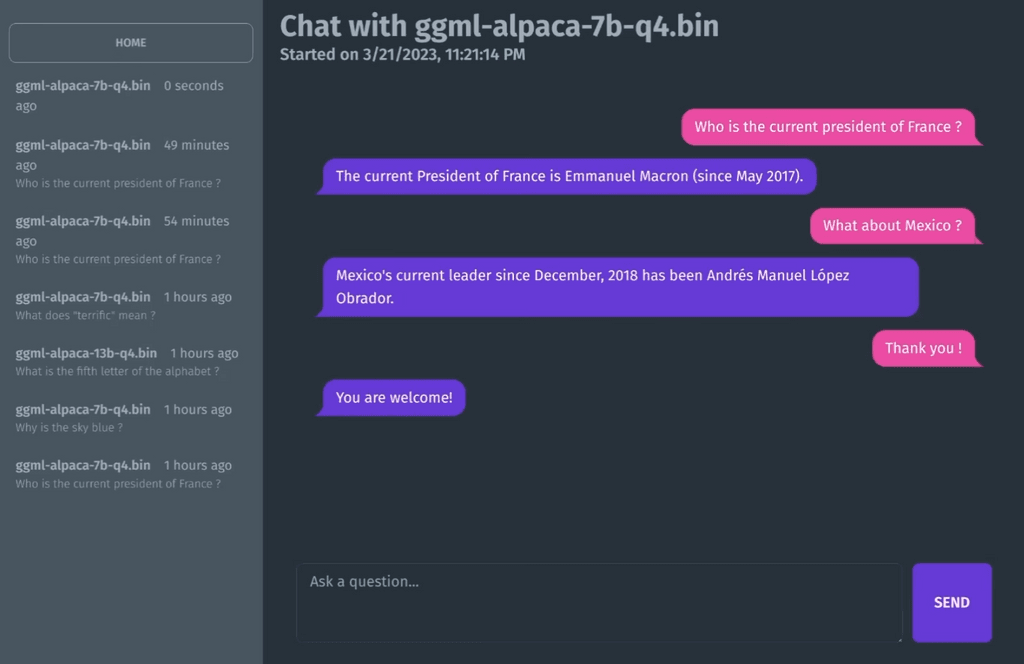
chat interface based on llama.cpp for running Alpaca models. Entirely self-hosted, no API keys needed. Fits on 4GB of RAM and runs on the CPU.
SvelteKit frontend
MongoDB for storing chat history & parameters
FastAPI + beanie for the API, wrapping calls to llama.cpp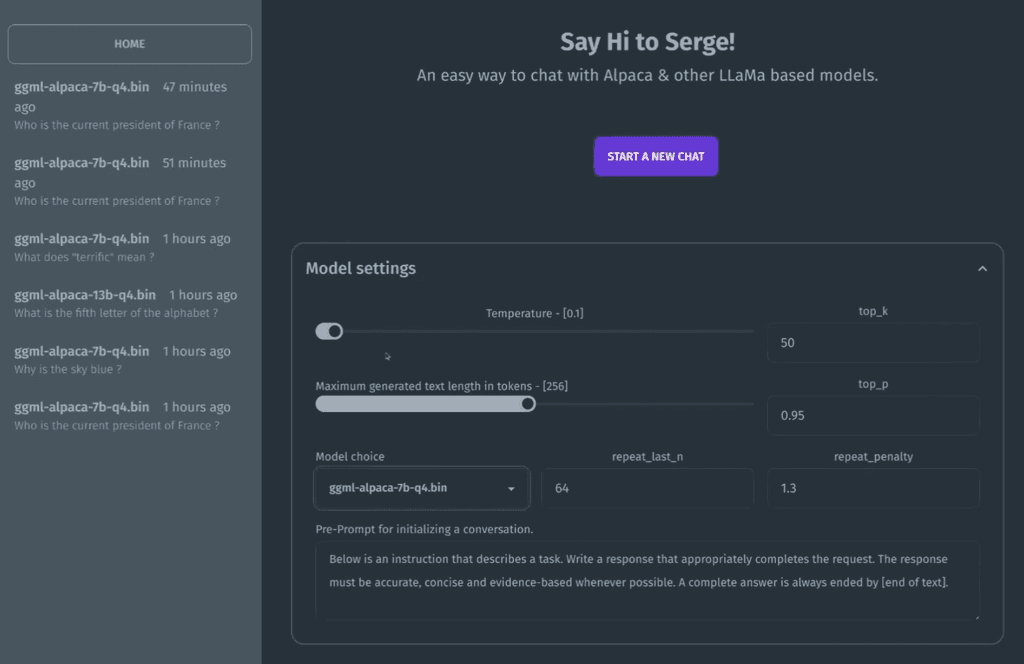
-
 M marcusquinn referenced this topic on
M marcusquinn referenced this topic on
-
chat interface based on llama.cpp for running Alpaca models. Entirely self-hosted, no API keys needed. Fits on 4GB of RAM and runs on the CPU.
SvelteKit frontend
MongoDB for storing chat history & parameters
FastAPI + beanie for the API, wrapping calls to llama.cpp@marcusquinn I tried running this locally but it gave me a "502 bad gateway" error. I wish they hadn't chosen Discord for their support platform. (You might need docker compose running, if you end up with this problem.)
Anyway, this is a great suggestion and I hope we have Serge supported on Cloudron.
The information bubbles/tooltips don't appear properly on Mozilla/or Brave. You can only see the bottom half of the text.
Here is some AI helping explain AI:
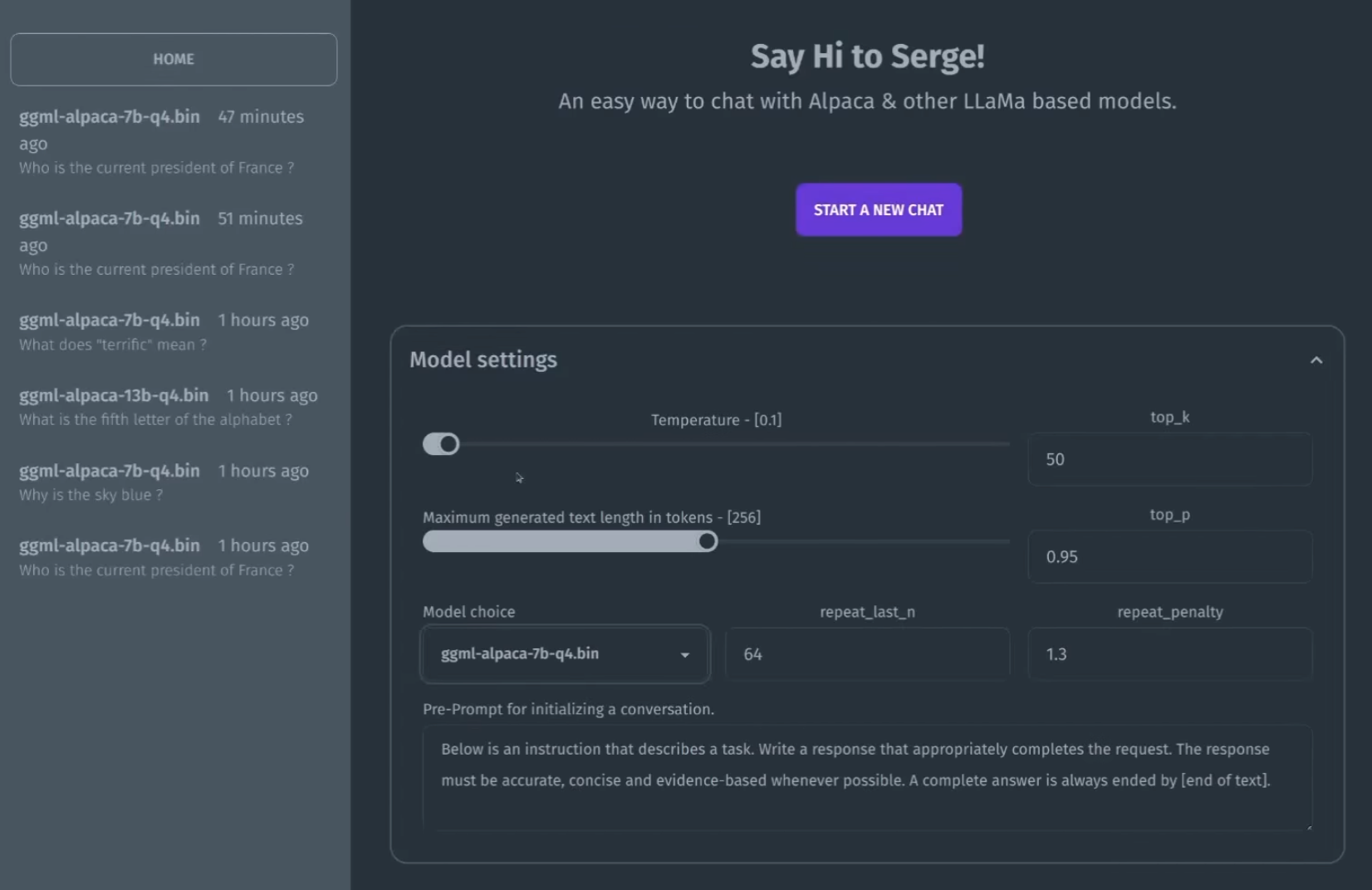
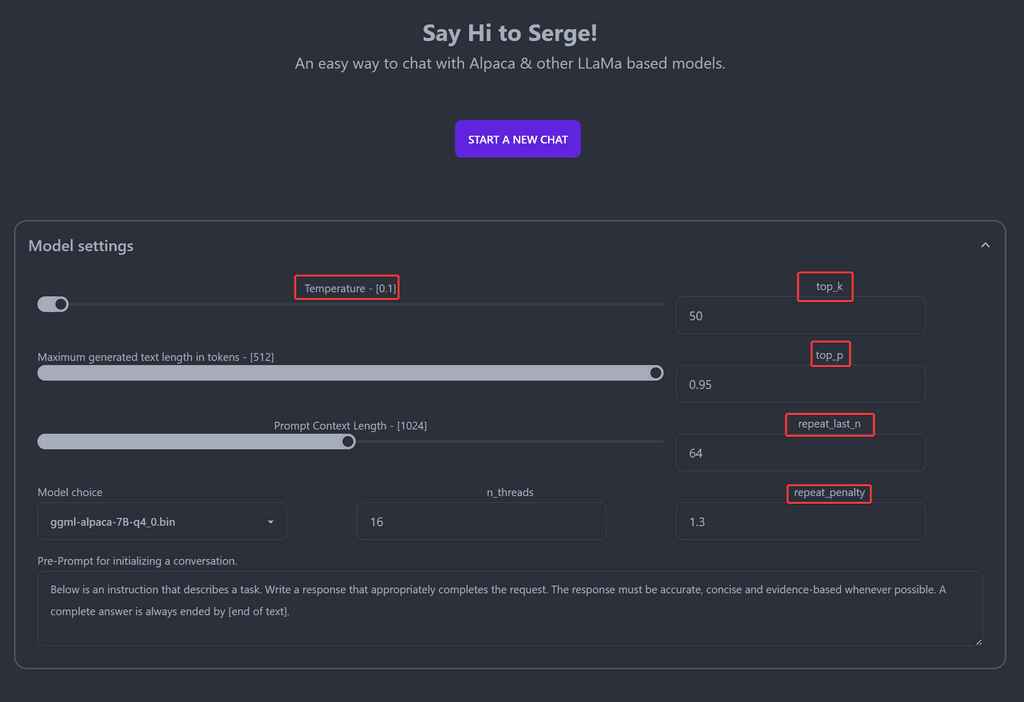
Temperature
The "temperature" setting in the Serge interface likely refers to the "temperature parameter" used in some natural language processing (NLP) models , particularly in those that generate text using an algorithm called "GPT" (Generative Pretrained Transformer). In GPT models, the temperature parameter controls the level of randomness or creativity in the generated text. A low temperature will produce more predictable and conservative output, while a high temperature will produce more diverse and surprising output. The temperature parameter essentially controls how much the model leans towards more common or less common output based on its training data. In the Serge interface or any other NLP tool that uses GPT, setting the temperature can ultimately affect the quality of the generated text, making it either more predictable or more creative depending on the desired outcome.top_k / top_p
In natural language processing (NLP) and generative language models, "top_k" and "top_p" are settings that control the amount of randomness or diversity in the output text. "Top_k" is a setting that limits the number of tokens to consider for the next word in the generated text. For example, if "top_k" is set to 5, the algorithm will only consider the top 5 most probable next words based on its training data. "Top_p," also known as nucleus sampling or probabilistic sampling, is a setting that limits the cumulative distribution of the probabilities of the next words. For example, if "top_p" is set to 0.9, the algorithm will select the minimum number of tokens where the sum of their probabilities is at least 0.9, and then sample from that subset of tokens. Both settings are used to control the level of randomness or creativity in the generated text. Lower values for "top_k" or "top_p" will produce more predictable and conservative output, while higher values will produce more diverse and surprising output.repeat_last_n / repeat_penalty
"repeat_last_n" and "repeat_penalty" are settings that control the repetition of text in the generated output. "Repeat_last_n" is a setting that controls how many previous generated tokens are checked for duplication before a new token is generated. This can help avoid repetition in the output, as the algorithm will avoid generating tokens that are similar or identical to the previous ones. "Repeat_penalty," on the other hand, is a setting that controls how much of a penalty or bias is given to generating similar or identical tokens in the output. Higher values for repeat_penalty will discourage the algorithm from generating repeated or similar text, while lower values will allow for more repetition and similarity in the output. Both settings are used to help control the repetition and diversity of the generated text, and can be adjusted to achieve the desired balance between coherence and novelty in the generated output.n_threads
"n_threads" setting often refers to the number of threads or worker processes that are used to execute a particular task or set of tasks. Threads are lightweight units of processing that can run concurrently within a single process. By dividing a task into multiple threads, it is possible to take advantage of multi-core processors and parallelize the processing of the task, which can improve performance and reduce processing time. The specific meaning and usage of the "n_threads" setting may vary depending on the context and the software or library being used. In some cases, "n_threads" may refer to the total number of threads available to the program at runtime, while in other cases it may refer to the number of threads that are explicitly created or allocated for a specific task. Overall, the "n_threads" setting can have a significant impact on the performance and efficiency of multi-threaded processing, and may require some experimentation to determine the optimal value for a given task or system.Based on the search results, it seems that ggml-alpaca-7b, ggml-alpaca-30b, and ggml-alpaca-13b are different models for the Alpaca AI language model. The main difference between these models is their size and complexity, with ggml-alpaca-7b being the smallest and ggml-alpaca-30b being the largest. The specific differences in performance and accuracy between these models may be dependent on their intended use cases and the type of data they are trained on. It's best to consult the documentation or reach out to the developers for more information on the specific differences between these models. -
chat interface based on llama.cpp for running Alpaca models. Entirely self-hosted, no API keys needed. Fits on 4GB of RAM and runs on the CPU.
SvelteKit frontend
MongoDB for storing chat history & parameters
FastAPI + beanie for the API, wrapping calls to llama.cpp -
@marcusquinn Have you been able to get the ggml-alpaca-30B-q4_0 model to work? For me the best it can do is eggtime or give me a "loading" message.
@JOduMonT I think you might like this project.
@LoudLemur Not tried yet. Just spotted it on my Reddit travels, skimming past a post on it i the self-hosting sub-Reddit.
-
L LoudLemur referenced this topic on
-
@LoudLemur Not tried yet. Just spotted it on my Reddit travels, skimming past a post on it i the self-hosting sub-Reddit.
@marcusquinn said in Serge - LLaMa made easy 🦙 - self-hosted AI Chat:
@LoudLemur Not tried yet. Just spotted it on my Reddit travels, skimming past a post on it i the self-hosting sub-Reddit.
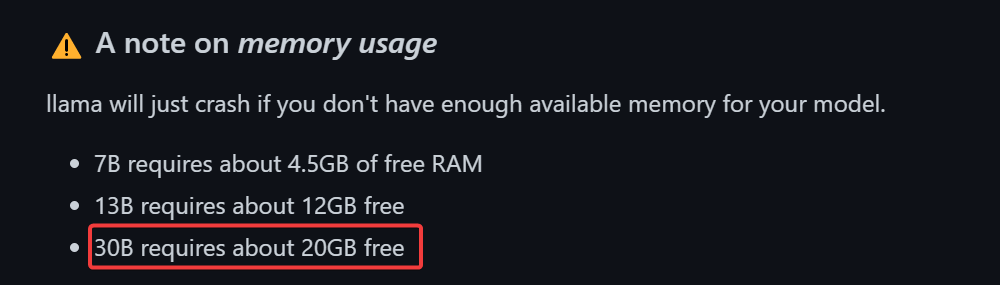
It was a RAM issue. If you don't have a lot of RAM, it is best not to multi-task with it.
-
chat interface based on llama.cpp for running Alpaca models. Entirely self-hosted, no API keys needed. Fits on 4GB of RAM and runs on the CPU.
SvelteKit frontend
MongoDB for storing chat history & parameters
FastAPI + beanie for the API, wrapping calls to llama.cpp@marcusquinn There is now a medical Alpaca too:
https://teddit.net/r/LocalLLaMA/comments/12c4hyx/introducing_medalpaca_language_models_for_medical/
We could ask it health related questions, or perhaps it could ask us questions...
-
@lars1134 said in Serge - LLaMa made easy 🦙 - self-hosted AI Chat:
Is there any interest in getting this in the app store?
There is also this, but I couldn't see the code for the GUI:
https://lmstudio.ai/ -
@lars1134 said in Serge - LLaMa made easy 🦙 - self-hosted AI Chat:
Is there any interest in getting this in the app store?
There is also this, but I couldn't see the code for the GUI:
https://lmstudio.ai/It looks like that only runs locally, but I like the program.
I liked serge as I have quite a bit of ram left unused at one of my servers.
-
This might be a good one for @Kubernetes ?
Indie app dev, huge fan of Cloudron PaaS, scratching my itches : communityapps.appx.uk
-
This might be a good one for @Kubernetes ?
@timconsidine I already played with it on my local machines. I still miss quality for other languages than english. In addition it is very RAM and Disk consuming. So I think it is better to run it dedicated instead of running in shared mode with other applications.
-
I'm on huggingface and the library is huge! My laptop has 32GB RAM and an empty 500GB secondary SSD. Which model would be a good GPT-3.5 alternative?
@humptydumpty said in Serge - LLaMa made easy 🦙 - self-hosted AI Chat:
I'm on huggingface and the library is huge! My laptop has 32GB RAM and an empty 500GB secondary SSD. Which model would be a good GPT-3.5 alternative?
This model uses the recently released Llama2, is uncensored as far as things go and works well and even better with longer prompts:
-
@Kubernetes Thank you for looking into it. I understand the limitations. I run a few servers that have more than 10 EPYC cores and 50GB RAM left unused - those servers have a lot more available resources than our local clients. But I understand that not too many have a similar situation.
-
@Kubernetes Thank you for looking into it. I understand the limitations. I run a few servers that have more than 10 EPYC cores and 50GB RAM left unused - those servers have a lot more available resources than our local clients. But I understand that not too many have a similar situation.
-
@lars1134 the tests I've run in a LAMP app allows these to run in less than 5GB RAM (depending on model) using the right combo of sw all on CPU only.
@robi said in Serge - LLaMa made easy 🦙 - self-hosted AI Chat:
using the right combo of sw all on CPU only.
The GGML versions of the models are designed to offload the work onto the CPU and RAM and, if there is a GPU available, to use that too. Q6 versions offer more power than e.g. Q4, but are a bit slower.
-
From Claude AI:
"
Here is a quick comparison of FP16, GPTQ and GGML model versions:FP16 (Half precision float 16):
Uses 16-bit floats instead of 32-bit floats to represent weights and activations in a neural network.
Reduces model size and memory usage by half compared to FP32 models.
May lower model accuracy slightly compared to FP32, but often accuracy is very close.
Supported on most modern GPUs and TPUs for efficient training and inference.GPTQ (Quantization aware training):
Quantizes weights and/or activations to low bitwidths like 8-bit during training.
Further compresses model size over FP16.
Accuracy is often very close to FP32 model.
Requires quantization aware training techniques.
Currently primarily supported on TPUs.GGML (Mixture of experts):
Partitions a single large model into smaller expert models.
Reduces compute requirements for inference since only one expert is used per sample.
Can maintain accuracy of original large model.
Increases model size due to overhead of gating model and expert models.
Requires changes to model architecture and training procedure.
In summary, FP16 is a straightforward way to reduce model size with minimal accuracy loss. GPTQ can further compress models through quantization-aware training. GGML can provide inference speedups through model parallelism while maintaining accuracy. The best choice depends on hardware constraints, accuracy requirements and inference latency needs." -
@lars1134 the tests I've run in a LAMP app allows these to run in less than 5GB RAM (depending on model) using the right combo of sw all on CPU only.
@robi said in Serge - LLaMa made easy 🦙 - self-hosted AI Chat:
@lars1134 the tests I've run in a LAMP app allows these to run in less than 5GB RAM (depending on model) using the right combo of sw all on CPU only.
Awesome, I will definitely look into that today and tomorrow. Thank you for the inspiration
 . I will let you know how things went for me.
. I will let you know how things went for me.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login