ArchiveBox -- Personal Internet Archive
-
https://archivebox.io
"ArchiveBox takes a list of website URLs you want to archive, and creates a local, static, browsable HTML clone of the content from those websites (it saves HTML, JS, media files, PDFs, images and more)."Can import links from:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON, or plain text lists
- Browser history or bookmarks (Chrome, Firefox, Safari, IE, Opera, and more)
Shaarli, Delicious, Reddit Saved Posts, Wallabag, Unmark.it, and any other text with links in it!
Can save these things for each site:
- favicon.ico favicon of the site
- example.com/page-name.html wget clone of the site, with .html appended if not present
- output.pdf Printed PDF of site using headless chrome
- screenshot.png 1440x900 screenshot of site using headless chrome
- output.html DOM Dump of the HTML after rendering using headless chrome
- archive.org.txt A link to the saved site on archive.org
- warc/ for the html + gzipped warc file .gz
- media/ any mp4, mp3, subtitles, and metadata found using youtube-dl
- git/ clone of any repository for github, bitbucket, or gitlab links
- index.html & index.json HTML and JSON index files containing metadata and details
There's a Docker image, as well: https://github.com/pirate/ArchiveBox
-
The dockerfile looks a bit involved, but it exposes some very handy ENV vars to customize the directories and user. An initial implementation might just override those and build using the project's own dockerfile.
Integration with https://amberlink.org/ would be interesting.
-
https://archivebox.io
"ArchiveBox takes a list of website URLs you want to archive, and creates a local, static, browsable HTML clone of the content from those websites (it saves HTML, JS, media files, PDFs, images and more)."Can import links from:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON, or plain text lists
- Browser history or bookmarks (Chrome, Firefox, Safari, IE, Opera, and more)
Shaarli, Delicious, Reddit Saved Posts, Wallabag, Unmark.it, and any other text with links in it!
Can save these things for each site:
- favicon.ico favicon of the site
- example.com/page-name.html wget clone of the site, with .html appended if not present
- output.pdf Printed PDF of site using headless chrome
- screenshot.png 1440x900 screenshot of site using headless chrome
- output.html DOM Dump of the HTML after rendering using headless chrome
- archive.org.txt A link to the saved site on archive.org
- warc/ for the html + gzipped warc file .gz
- media/ any mp4, mp3, subtitles, and metadata found using youtube-dl
- git/ clone of any repository for github, bitbucket, or gitlab links
- index.html & index.json HTML and JSON index files containing metadata and details
There's a Docker image, as well: https://github.com/pirate/ArchiveBox
@heliostatic Great suggestion! lets get this bird in the air.
I think something like this using IPFS to support the archiving would be ideal.
-
https://archivebox.io
"ArchiveBox takes a list of website URLs you want to archive, and creates a local, static, browsable HTML clone of the content from those websites (it saves HTML, JS, media files, PDFs, images and more)."Can import links from:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON, or plain text lists
- Browser history or bookmarks (Chrome, Firefox, Safari, IE, Opera, and more)
Shaarli, Delicious, Reddit Saved Posts, Wallabag, Unmark.it, and any other text with links in it!
Can save these things for each site:
- favicon.ico favicon of the site
- example.com/page-name.html wget clone of the site, with .html appended if not present
- output.pdf Printed PDF of site using headless chrome
- screenshot.png 1440x900 screenshot of site using headless chrome
- output.html DOM Dump of the HTML after rendering using headless chrome
- archive.org.txt A link to the saved site on archive.org
- warc/ for the html + gzipped warc file .gz
- media/ any mp4, mp3, subtitles, and metadata found using youtube-dl
- git/ clone of any repository for github, bitbucket, or gitlab links
- index.html & index.json HTML and JSON index files containing metadata and details
There's a Docker image, as well: https://github.com/pirate/ArchiveBox
In nearly 3 years here ArchiveBox has only managed to receive 5 upvotes. This is depressing. There is a big need for self-hosted archiving and if this application had been supported 3 years ago, it would have been ready for all those people who had their websites shuttered.
The last ArchiveBox update was April 2021. There is a Docker image. The code has received high quality ratings. Lets sort this!
-
In nearly 3 years here ArchiveBox has only managed to receive 5 upvotes. This is depressing. There is a big need for self-hosted archiving and if this application had been supported 3 years ago, it would have been ready for all those people who had their websites shuttered.
The last ArchiveBox update was April 2021. There is a Docker image. The code has received high quality ratings. Lets sort this!
@loudlemur said in ArchiveBox -- Personal Internet Archive:
There is a big need for self-hosted archiving
That doesn't seem to reconcile with only 5 votes.
-
@loudlemur said in ArchiveBox -- Personal Internet Archive:
There is a big need for self-hosted archiving
That doesn't seem to reconcile with only 5 votes.
@timconsidine said in ArchiveBox -- Personal Internet Archive:
@loudlemur said in ArchiveBox -- Personal Internet Archive:
There is a big need for self-hosted archiving
That doesn't seem to reconcile with only 5 votes.
Hah! Yes, there seems to be something wrong with reality here! haa!
Cloudron is brilliant for the updates, which just keep on coming and keep on working. What is the balance of time given to updating existing applications and introducing new ones?
Something like this was suggested recently, but couldn't we try crowd funding somebody with packaging skills to rattle off a few more applications and help clear the backlog?
What could we hope for with a dedicated packager? 5 new packages a week? 10?
-
In nearly 3 years here ArchiveBox has only managed to receive 5 upvotes. This is depressing. There is a big need for self-hosted archiving and if this application had been supported 3 years ago, it would have been ready for all those people who had their websites shuttered.
The last ArchiveBox update was April 2021. There is a Docker image. The code has received high quality ratings. Lets sort this!
@loudlemur said in ArchiveBox -- Personal Internet Archive:
The last ArchiveBox update was April 2021
Precisely!
There have been no releases for 10 months:-
https://github.com/ArchiveBox/ArchiveBox/tagshttps://github.com/ArchiveBox/ArchiveBox/commits/dev
shows commits just 7 days ago, but IMO not much use without releases. -
In nearly 3 years here ArchiveBox has only managed to receive 5 upvotes. This is depressing. There is a big need for self-hosted archiving and if this application had been supported 3 years ago, it would have been ready for all those people who had their websites shuttered.
The last ArchiveBox update was April 2021. There is a Docker image. The code has received high quality ratings. Lets sort this!
@loudlemur Just to be clear, I'm also very keen to see new apps on Cloudron.
I just understand that I need to wait, and for those that I feel cannot wait for, I take an alternative route :
- get another VPS and install CapRover. ArchiveBox is on CapRover if you have pressing need, as well some others that are on Cloudron wishlist. However in my experience as many as 40-50% of apps available on CapRover don't install correctly. More people packaging but quality and reliability much lower. Which is why it can be be worth waiting for a Cloudron app.
- get another VPS and install docker / docker-compose, then no need of packaging, just installing apps which have already been dockerized
- work through the tutorials about packaging, it's not easy but equally it's not beond reach. Lots of gotchas on the way, patient experimentation required, and personally I'm still learning, so it's for sure not a rapid solution to getting something packaged.
All I'm saying is that's about priorities. If it's urgent enough and high enough priority, then that might suggest it's worth biting the bullet for an extra server for own docker installs or own CapRover or both.
I have :
- 1 x Cloudron
- 1 x Caprover
- 1 x "pure" Docker apps
- 1 x Kasm
- 1 x openEdX / Tutor.
I accept I'm unlikely to get all of what I need/want on Cloudron in time for when I need/want it.
-
@timconsidine said in ArchiveBox -- Personal Internet Archive:
@loudlemur said in ArchiveBox -- Personal Internet Archive:
There is a big need for self-hosted archiving
That doesn't seem to reconcile with only 5 votes.
Hah! Yes, there seems to be something wrong with reality here! haa!
Cloudron is brilliant for the updates, which just keep on coming and keep on working. What is the balance of time given to updating existing applications and introducing new ones?
Something like this was suggested recently, but couldn't we try crowd funding somebody with packaging skills to rattle off a few more applications and help clear the backlog?
What could we hope for with a dedicated packager? 5 new packages a week? 10?
@loudlemur said in ArchiveBox -- Personal Internet Archive:
What could we hope for with a dedicated packager? 5 new packages a week? 10?
I would say one or 2.
There's a lot of work in packaging & in testing. -
@loudlemur said in ArchiveBox -- Personal Internet Archive:
What could we hope for with a dedicated packager? 5 new packages a week? 10?
I would say one or 2.
There's a lot of work in packaging & in testing. -
@timconsidine Thanks for those ideas.
It really is nice to know that if it is on Cloudron, it will work and be supported.
@loudlemur said in ArchiveBox -- Personal Internet Archive:
t really is nice to know that if it is on Cloudron, it will work and be supported.
Yes. And you mention support. Support for Caprover apps is close to non-existent. No, actually, sorry, that's harsh. There is support, but not a patch on what is available here.
May also be worth exploring Yunohost and your own Heroku server (e.g. Dokku). They don't work for me, but they may for you or others.
-
I use a Firefox extension called SingleFile that saves webpages as HTML. Works great.
-
https://archivebox.io
"ArchiveBox takes a list of website URLs you want to archive, and creates a local, static, browsable HTML clone of the content from those websites (it saves HTML, JS, media files, PDFs, images and more)."Can import links from:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON, or plain text lists
- Browser history or bookmarks (Chrome, Firefox, Safari, IE, Opera, and more)
Shaarli, Delicious, Reddit Saved Posts, Wallabag, Unmark.it, and any other text with links in it!
Can save these things for each site:
- favicon.ico favicon of the site
- example.com/page-name.html wget clone of the site, with .html appended if not present
- output.pdf Printed PDF of site using headless chrome
- screenshot.png 1440x900 screenshot of site using headless chrome
- output.html DOM Dump of the HTML after rendering using headless chrome
- archive.org.txt A link to the saved site on archive.org
- warc/ for the html + gzipped warc file .gz
- media/ any mp4, mp3, subtitles, and metadata found using youtube-dl
- git/ clone of any repository for github, bitbucket, or gitlab links
- index.html & index.json HTML and JSON index files containing metadata and details
There's a Docker image, as well: https://github.com/pirate/ArchiveBox
@heliostatic What is the progress on supporting ArchiveBox on Cloudron?
-
https://archivebox.io
"ArchiveBox takes a list of website URLs you want to archive, and creates a local, static, browsable HTML clone of the content from those websites (it saves HTML, JS, media files, PDFs, images and more)."Can import links from:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON, or plain text lists
- Browser history or bookmarks (Chrome, Firefox, Safari, IE, Opera, and more)
Shaarli, Delicious, Reddit Saved Posts, Wallabag, Unmark.it, and any other text with links in it!
Can save these things for each site:
- favicon.ico favicon of the site
- example.com/page-name.html wget clone of the site, with .html appended if not present
- output.pdf Printed PDF of site using headless chrome
- screenshot.png 1440x900 screenshot of site using headless chrome
- output.html DOM Dump of the HTML after rendering using headless chrome
- archive.org.txt A link to the saved site on archive.org
- warc/ for the html + gzipped warc file .gz
- media/ any mp4, mp3, subtitles, and metadata found using youtube-dl
- git/ clone of any repository for github, bitbucket, or gitlab links
- index.html & index.json HTML and JSON index files containing metadata and details
There's a Docker image, as well: https://github.com/pirate/ArchiveBox
ArchiveBox was featured in a blog recently:
https://ostechnix.com/self-host-internet-archive-with-archivebox/
-
@loudlemur said in ArchiveBox -- Personal Internet Archive:
The last ArchiveBox update was April 2021
Precisely!
There have been no releases for 10 months:-
https://github.com/ArchiveBox/ArchiveBox/tagshttps://github.com/ArchiveBox/ArchiveBox/commits/dev
shows commits just 7 days ago, but IMO not much use without releases.@RoundHouse1924 said in ArchiveBox -- Personal Internet Archive:
@loudlemur said in ArchiveBox -- Personal Internet Archive:
The last ArchiveBox update was April 2021
Precisely!
There have been no releases for 10 months:-
https://github.com/ArchiveBox/ArchiveBox/tagshttps://github.com/ArchiveBox/ArchiveBox/commits/dev
shows commits just 7 days ago, but IMO not much use without releases.There have been 5 releases since August:
https://selfhosted.libhunt.com/bookmark-archiver-changelog -
https://archivebox.io
"ArchiveBox takes a list of website URLs you want to archive, and creates a local, static, browsable HTML clone of the content from those websites (it saves HTML, JS, media files, PDFs, images and more)."Can import links from:
- Pocket, Pinboard, Instapaper
- RSS, XML, JSON, or plain text lists
- Browser history or bookmarks (Chrome, Firefox, Safari, IE, Opera, and more)
Shaarli, Delicious, Reddit Saved Posts, Wallabag, Unmark.it, and any other text with links in it!
Can save these things for each site:
- favicon.ico favicon of the site
- example.com/page-name.html wget clone of the site, with .html appended if not present
- output.pdf Printed PDF of site using headless chrome
- screenshot.png 1440x900 screenshot of site using headless chrome
- output.html DOM Dump of the HTML after rendering using headless chrome
- archive.org.txt A link to the saved site on archive.org
- warc/ for the html + gzipped warc file .gz
- media/ any mp4, mp3, subtitles, and metadata found using youtube-dl
- git/ clone of any repository for github, bitbucket, or gitlab links
- index.html & index.json HTML and JSON index files containing metadata and details
There's a Docker image, as well: https://github.com/pirate/ArchiveBox
ArchiveBox is very popular. I hope Cloudron support it.
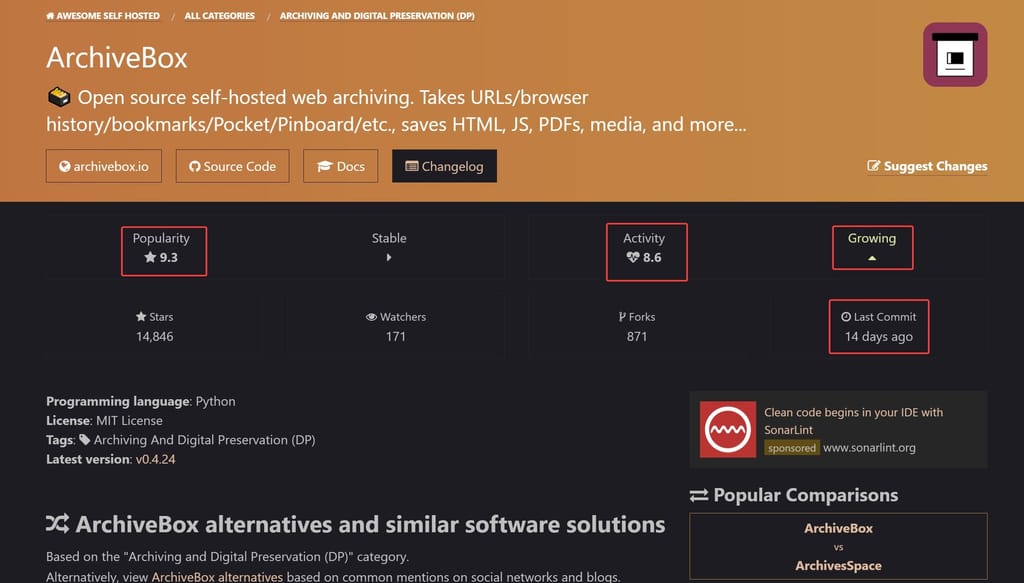
Also consider ArchivesSpace:
https://forum.cloudron.io/topic/4121/archivesspace-archives-collection-management-system/1
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login