When restoring Cloudron, two apps didn't complete due to DNS propagation... how to resume without needing to restore again?
-
tl;dr: There seems to be a usability defect in the process of restoring apps when DNS fails. The files all exist for the app so no backup should need to be restored again, and once DNS is changed days later it then fails to succeed if the backup was removed prior even though it shouldn't need those files and just needs to configure Apache/Nginx and ensure the cert exists.
I had moved my Cloudron server to a a new Vultr VPS server (their High-Frequency servers are pretty great so far, especially compared to the performance I had at OVH's Public Cloud instances).
There are two domains which I don't control the DNS for, so they are still pointing to the old server for now and should change in a few days. However one of them was changed early this morning and so I went to then restart the restore process, but it failed because I had removed the older backups already while setting up Object Storage at Vultr.
What's odd about that is that when I look at the files in the app, it all seems to be there. And it kind of makes sense that'd they'd all be present since it downloads the files from backup before bothering with DNS propagation checks. So why is the backup files even required for a second time now? This seems like a usability defect to me.
What I had to do to get around it was the following:
- Change /etc/hosts file on my computer
- Login to the old machine
- Make a backup of the app
- Download the backup config
- Change /etc/hosts again to point to the new instance
- Restore backup on new instance using the Import Backup process.
The above worked, but was a real pain and created more downtime than necessary.
At present, I now have one last domain that will be encountering the same issue as before at some point in the coming days and I'd like to know how to avoid this if possible.
The apps on the last domain are there, the files all exist and are ready for action, except when I click the Retry Restore task (it's really the only option I see), it gives me the error around backups not found:
backupID must be non-empty stringis the error I see.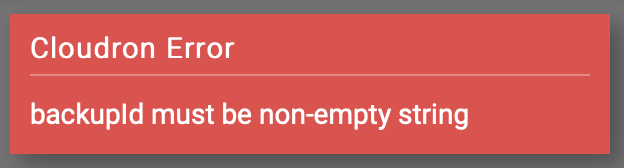
But again... why is a backup even necessary when the backup was already done earlier in terms of all the files being presented on the new instance already and the task only failed because I stopped it at the time due to DNS propogation checks which weren't going to work yet until my client modified their DNS records. Is there a way around this somehow?
If there's no way around it, I'd like to request that the process be improved, because if the files were actually restored properly earlier and only DNS failed at the time, it should no longer need a backup ID to restore from in order to proceed again, unless I'm misunderstanding something.
--
Dustin Dauncey
www.d19.ca -
I realize this doesn’t answer your question, but I love your Help requests Dustin. They stem from real-world, in-use, time-sensitive contexts, the solving of which actually helps many of us (I think) who read through the issues, and likely have had/will have the same. Your requests are a dynamic alternative to others’ requests about “why can’t Cloudron do X because unicorns and fairies”, or “I have an imagined use case that will apply once to me, maybe, and I demand the Cloudron devs put all their focus on my bizarre niche demand”.
Press on!
-
tl;dr: There seems to be a usability defect in the process of restoring apps when DNS fails. The files all exist for the app so no backup should need to be restored again, and once DNS is changed days later it then fails to succeed if the backup was removed prior even though it shouldn't need those files and just needs to configure Apache/Nginx and ensure the cert exists.
I had moved my Cloudron server to a a new Vultr VPS server (their High-Frequency servers are pretty great so far, especially compared to the performance I had at OVH's Public Cloud instances).
There are two domains which I don't control the DNS for, so they are still pointing to the old server for now and should change in a few days. However one of them was changed early this morning and so I went to then restart the restore process, but it failed because I had removed the older backups already while setting up Object Storage at Vultr.
What's odd about that is that when I look at the files in the app, it all seems to be there. And it kind of makes sense that'd they'd all be present since it downloads the files from backup before bothering with DNS propagation checks. So why is the backup files even required for a second time now? This seems like a usability defect to me.
What I had to do to get around it was the following:
- Change /etc/hosts file on my computer
- Login to the old machine
- Make a backup of the app
- Download the backup config
- Change /etc/hosts again to point to the new instance
- Restore backup on new instance using the Import Backup process.
The above worked, but was a real pain and created more downtime than necessary.
At present, I now have one last domain that will be encountering the same issue as before at some point in the coming days and I'd like to know how to avoid this if possible.
The apps on the last domain are there, the files all exist and are ready for action, except when I click the Retry Restore task (it's really the only option I see), it gives me the error around backups not found:
backupID must be non-empty stringis the error I see.But again... why is a backup even necessary when the backup was already done earlier in terms of all the files being presented on the new instance already and the task only failed because I stopped it at the time due to DNS propogation checks which weren't going to work yet until my client modified their DNS records. Is there a way around this somehow?
If there's no way around it, I'd like to request that the process be improved, because if the files were actually restored properly earlier and only DNS failed at the time, it should no longer need a backup ID to restore from in order to proceed again, unless I'm misunderstanding something.
@d19dotca thanks for the detailed description, however I am still not sure I got what you exactly hit here. So you restored a Cloudron from a backup and presumably have checked the dry-run option for DNS since the old Cloudron is still the one where the DNS is pointing to?
Just to be clear, you have a Cloudron with apps (from one domain) which are in error state after restore due to DNS propagation errors and now when the DNS is actually switched you want them to just be up and running again, which sadly re-runs the whole restore essentially? -
@d19dotca thanks for the detailed description, however I am still not sure I got what you exactly hit here. So you restored a Cloudron from a backup and presumably have checked the dry-run option for DNS since the old Cloudron is still the one where the DNS is pointing to?
Just to be clear, you have a Cloudron with apps (from one domain) which are in error state after restore due to DNS propagation errors and now when the DNS is actually switched you want them to just be up and running again, which sadly re-runs the whole restore essentially?@nebulon said:
you restored a Cloudron from a backup and presumably have checked the dry-run option for DNS since the old Cloudron is still the one where the DNS is pointing to?
Actually I did a live migration, not a dry run. All the domains where I control the DNS were updated. Unfortunately two domains on my Cloudron instance I don’t actually control their DNS and have to rely on their IT guy to make the changes. One domain was updated and that’s the issue I encountered. The remaining domain has yet to be updated but I expect will be done any day now. In the meantime, that domain is still pointing to the old server.
Just to be clear, you have a Cloudron with apps (from one domain) which are in error state after restore due to DNS propagation errors and now when the DNS is actually switched you want them to just be up and running again, which sadly re-runs the whole restore essentially?
Correct. Basically all the files were restored properly since that’s the first thing Cloudron does during the restore process, but in the end the task failed because of DNS. When the DNS was finally updated for one of the domains, I went to retry the task and it started to do a full restore operation again despite all the files already existing. It of course failed because I had deleted the old backups by that point. I suppose this would be easier if I hadn’t done that, but it has me questioning why that’s even necessary to restore all the files when the files were already restored and exist on the new server. It should just sort of do a DNS check again and start up properly, not needing to do a restore at all.
————————————
@scooke said:
I love your Help requests Dustin. They stem from real-world, in-use, time-sensitive contexts, the solving of which actually helps many of us (I think) who read through the issues, and likely have had/will have the same. Your requests are a dynamic alternative to others’ requests about “why can’t Cloudron do X because unicorns and fairies”, or “I have an imagined use case that will apply once to me, maybe, and I demand the Cloudron devs put all their focus on my bizarre niche demand”.
Haha, I really appreciate that, thank you! I like to think while I’m not a developer who can build apps I’ve still been able to contribute to the documentation and try to find gaps in the user experience.
 I’m glad others see the value in that too. I definitely hope the experiences I report can help future Cloudron users.
I’m glad others see the value in that too. I definitely hope the experiences I report can help future Cloudron users.  Thanks again, I needed that positive message this morning.
Thanks again, I needed that positive message this morning.--
Dustin Dauncey
www.d19.ca -
@nebulon said:
you restored a Cloudron from a backup and presumably have checked the dry-run option for DNS since the old Cloudron is still the one where the DNS is pointing to?
Actually I did a live migration, not a dry run. All the domains where I control the DNS were updated. Unfortunately two domains on my Cloudron instance I don’t actually control their DNS and have to rely on their IT guy to make the changes. One domain was updated and that’s the issue I encountered. The remaining domain has yet to be updated but I expect will be done any day now. In the meantime, that domain is still pointing to the old server.
Just to be clear, you have a Cloudron with apps (from one domain) which are in error state after restore due to DNS propagation errors and now when the DNS is actually switched you want them to just be up and running again, which sadly re-runs the whole restore essentially?
Correct. Basically all the files were restored properly since that’s the first thing Cloudron does during the restore process, but in the end the task failed because of DNS. When the DNS was finally updated for one of the domains, I went to retry the task and it started to do a full restore operation again despite all the files already existing. It of course failed because I had deleted the old backups by that point. I suppose this would be easier if I hadn’t done that, but it has me questioning why that’s even necessary to restore all the files when the files were already restored and exist on the new server. It should just sort of do a DNS check again and start up properly, not needing to do a restore at all.
————————————
@scooke said:
I love your Help requests Dustin. They stem from real-world, in-use, time-sensitive contexts, the solving of which actually helps many of us (I think) who read through the issues, and likely have had/will have the same. Your requests are a dynamic alternative to others’ requests about “why can’t Cloudron do X because unicorns and fairies”, or “I have an imagined use case that will apply once to me, maybe, and I demand the Cloudron devs put all their focus on my bizarre niche demand”.
Haha, I really appreciate that, thank you! I like to think while I’m not a developer who can build apps I’ve still been able to contribute to the documentation and try to find gaps in the user experience.
I’m glad others see the value in that too. I definitely hope the experiences I report can help future Cloudron users. Thanks again, I needed that positive message this morning.@d19dotca I see now. There seems to be a possibility of optimizing that process. Currently a failed restore will trigger a complete restore as you found out. I guess the reason is, that it is not easy to determine what exactly needs to be redone on a failure, so we take the safer approach and rerun the same task as before. I think immediately this will be hard to optimize for your "edge-case" but we should keep it in mind for the future.
-
@d19dotca I see now. There seems to be a possibility of optimizing that process. Currently a failed restore will trigger a complete restore as you found out. I guess the reason is, that it is not easy to determine what exactly needs to be redone on a failure, so we take the safer approach and rerun the same task as before. I think immediately this will be hard to optimize for your "edge-case" but we should keep it in mind for the future.
@nebulon My two cents... whether this is an edge-case or not, this is a design defect (or a design that's not optimal at the very least) with room for meaningful improvement. It'd also likely affect other situations... example: what if I kept the backups but there was then a few hours outage at the Object Storage endpoint days later when the website's DNS was finally changed, and now the website has to encounter a few hours of downtime because it's waiting for files on Object Storage that it actually already has locally? Sure this is very unlikely, but fixing this issue would still benefit everyone regardless, especially when outbound traffic costs are charged by the Object Storage provider.
I likely (and understandably) turned my scenario into an "edge-case" by having removed the old backups after a period of time prior to the DNS records being changed for the two domains I don't control the DNS for, but the fact remains that Cloudron is currently designed to try a complete restore even though almost all of the restore process was successful prior, only failing at the DNS check.
I'd propose that the process be improved by perhaps creating "checkpoints" along the restore process, so that it only has to do the steps it actually failed to finish rather than the entire restore process from scratch. I'd like to make the following points which I assume nearly everyone would agree with:
-
It is inefficient to restore all the files of an app multiple times when the actual file restore part didn't even fail and it was only a failure on the DNS check - for example - which is also very superfluous in the end. This can mean extra financial costs to users in some situations too when using an Object Storage endpoint that charges for outbound traffic.
-
I think the "industry standard" would be to only reattempt what actually failed. Right now Cloudron assumes that the entire restore process failed if any one single part of it failed, and that's the inefficient part of the whole thing. Thinking about other industries... if something doesn't fully complete, do they generally try from scratch or just re-attempt the parts that failed? Example: Mechanic who's rebuilding a car... if they're suddenly missing a part (please draw a parallel to the DNS check), do they rip apart the entire car again and start from scratch or do they just wait until the part they need is back in-hand and begin again from where they left off?
") I guess it's a silly example, but hopefully illustrates the point.
I guess it's a silly example, but hopefully illustrates the point.
I realize I would have avoided the whole thing if I hadn't of deleted the old backups, but it didn't seem necessary to exist anymore since the files were in-fact already restored successfully and was only a DNS failure. I hadn't realized the restore process would start from scratch on re-attempting it, assuming it's begin again by just verifying the DNS was updated and then run successfully.
--
Dustin Dauncey
www.d19.ca -
-
@d19dotca I see now. There seems to be a possibility of optimizing that process. Currently a failed restore will trigger a complete restore as you found out. I guess the reason is, that it is not easy to determine what exactly needs to be redone on a failure, so we take the safer approach and rerun the same task as before. I think immediately this will be hard to optimize for your "edge-case" but we should keep it in mind for the future.
@d19dotca I guess the key bit from @nebulon's last reply is:
it is not easy to determine what exactly needs to be redone on a failure
I wonder how feasible your idea of "checkpoints" along the way would be to implement in practice. If possible, that sounds like a good idea to me.
Saying that, given transfer costs etc aren't generally that significant, I think right now I personally prefer the current Cloudron approach of making doubly sure just in case (because bits actually don't have too much in common with car part

") )
) -
@nebulon My two cents... whether this is an edge-case or not, this is a design defect (or a design that's not optimal at the very least) with room for meaningful improvement. It'd also likely affect other situations... example: what if I kept the backups but there was then a few hours outage at the Object Storage endpoint days later when the website's DNS was finally changed, and now the website has to encounter a few hours of downtime because it's waiting for files on Object Storage that it actually already has locally? Sure this is very unlikely, but fixing this issue would still benefit everyone regardless, especially when outbound traffic costs are charged by the Object Storage provider.
I likely (and understandably) turned my scenario into an "edge-case" by having removed the old backups after a period of time prior to the DNS records being changed for the two domains I don't control the DNS for, but the fact remains that Cloudron is currently designed to try a complete restore even though almost all of the restore process was successful prior, only failing at the DNS check.
I'd propose that the process be improved by perhaps creating "checkpoints" along the restore process, so that it only has to do the steps it actually failed to finish rather than the entire restore process from scratch. I'd like to make the following points which I assume nearly everyone would agree with:
-
It is inefficient to restore all the files of an app multiple times when the actual file restore part didn't even fail and it was only a failure on the DNS check - for example - which is also very superfluous in the end. This can mean extra financial costs to users in some situations too when using an Object Storage endpoint that charges for outbound traffic.
-
I think the "industry standard" would be to only reattempt what actually failed. Right now Cloudron assumes that the entire restore process failed if any one single part of it failed, and that's the inefficient part of the whole thing. Thinking about other industries... if something doesn't fully complete, do they generally try from scratch or just re-attempt the parts that failed? Example: Mechanic who's rebuilding a car... if they're suddenly missing a part (please draw a parallel to the DNS check), do they rip apart the entire car again and start from scratch or do they just wait until the part they need is back in-hand and begin again from where they left off?
I guess it's a silly example, but hopefully illustrates the point.
I realize I would have avoided the whole thing if I hadn't of deleted the old backups, but it didn't seem necessary to exist anymore since the files were in-fact already restored successfully and was only a DNS failure. I hadn't realized the restore process would start from scratch on re-attempting it, assuming it's begin again by just verifying the DNS was updated and then run successfully.
@d19dotca I agree with you points about possible improvements there. The main issue is, that we currently have no system in place to track tasks in-depth or via such checkpoints, so we have to rework the task system there. Ideally we would have thought of that from the get go, but at the moment this seems like a lot of work, which also needs thorough testing to avoid other side-effects. Just trying to explain why it may not be implemented any time soon.
Overall I guess in your case the dry-run restore or temporarily setting DNS backend to noop would have avoided all that also, while of course this has nothing to do with the task architecture as such. Just for other readers facing a similar situation, where one has no access to the DNS settings as such.
-
-
@d19dotca I agree with you points about possible improvements there. The main issue is, that we currently have no system in place to track tasks in-depth or via such checkpoints, so we have to rework the task system there. Ideally we would have thought of that from the get go, but at the moment this seems like a lot of work, which also needs thorough testing to avoid other side-effects. Just trying to explain why it may not be implemented any time soon.
Overall I guess in your case the dry-run restore or temporarily setting DNS backend to noop would have avoided all that also, while of course this has nothing to do with the task architecture as such. Just for other readers facing a similar situation, where one has no access to the DNS settings as such.
@nebulon said:
The main issue is, that we currently have no system in place to track tasks in-depth or via such checkpoints, so we have to rework the task system there. Ideally we would have thought of that from the get go, but at the moment this seems like a lot of work, which also needs thorough testing to avoid other side-effects. Just trying to explain why it may not be implemented any time soon.
Totally fair points. I can definitely appreciate that.
Overall I guess in your case the dry-run restore or temporarily setting DNS backend to noop would have avoided all that also
Good to note for future reference.
So next time if I had to do a restore on a server with a different IP, itd be best to first change the DNS to “noop” before restoring then, correct? If I was to take a backup again (as I have to now anyways), does it make sense then for me to change the DNS provider of that domain to noop temporarily on my new server, backup the apps from the old server on that domain and then restore to the new server, then it’d be running again, right? And of course I’d have to change it back to Manual as the DNS backend once their IT guy makes the changes to their DNS, right?
-
@d19dotca said in When restoring Cloudron, two apps didn't complete due to DNS propagation... how to resume without needing to restore again?:
I think the "industry standard" would be to only reattempt what actually failed.
Actually, atleast in cloud computing, we go more towards immutable infrastructure. This is mostly because it's cheaper, more predictable to build something from scratch (so ironically for your car example, a missing tyre means rebuilding the car is actually cheaper and faster than figuring out how to replace the tyre). In the past, I have dealt with puppet/chef/capistrano/cloudformation style systems which will try to read in the server's current state and try to update and sync with the declarative configs and they all fail in various ways. This is mostly because there are too many variables in a mutable system. It's instead just simpler to start from scratch. https://www.digitalocean.com/community/tutorials/what-is-immutable-infrastructure is a good article.
In this specific case, it's just easier and faster to restore from scratch than try to track and figure what state the system is in. All this said, I totally understand this doesn't work if one has to download 100s of gigs or the download takes hours, so I am not putting my head in the sand
One thing is that if you as an admin are "confident" that it's all downloaded and good, you can use the CLI tool to
cloudron import --in-place --app <app>and that will actually repair the app in-place. This is not exposed in the UI for the reason above - it only works if you are sure that everything is downloaded. -
@d19dotca said in When restoring Cloudron, two apps didn't complete due to DNS propagation... how to resume without needing to restore again?:
I think the "industry standard" would be to only reattempt what actually failed.
Actually, atleast in cloud computing, we go more towards immutable infrastructure. This is mostly because it's cheaper, more predictable to build something from scratch (so ironically for your car example, a missing tyre means rebuilding the car is actually cheaper and faster than figuring out how to replace the tyre). In the past, I have dealt with puppet/chef/capistrano/cloudformation style systems which will try to read in the server's current state and try to update and sync with the declarative configs and they all fail in various ways. This is mostly because there are too many variables in a mutable system. It's instead just simpler to start from scratch. https://www.digitalocean.com/community/tutorials/what-is-immutable-infrastructure is a good article.
In this specific case, it's just easier and faster to restore from scratch than try to track and figure what state the system is in. All this said, I totally understand this doesn't work if one has to download 100s of gigs or the download takes hours, so I am not putting my head in the sand
One thing is that if you as an admin are "confident" that it's all downloaded and good, you can use the CLI tool to
cloudron import --in-place --app <app>and that will actually repair the app in-place. This is not exposed in the UI for the reason above - it only works if you are sure that everything is downloaded. -
@d19dotca said in When restoring Cloudron, two apps didn't complete due to DNS propagation... how to resume without needing to restore again?:
I think the "industry standard" would be to only reattempt what actually failed.
Actually, atleast in cloud computing, we go more towards immutable infrastructure. This is mostly because it's cheaper, more predictable to build something from scratch (so ironically for your car example, a missing tyre means rebuilding the car is actually cheaper and faster than figuring out how to replace the tyre). In the past, I have dealt with puppet/chef/capistrano/cloudformation style systems which will try to read in the server's current state and try to update and sync with the declarative configs and they all fail in various ways. This is mostly because there are too many variables in a mutable system. It's instead just simpler to start from scratch. https://www.digitalocean.com/community/tutorials/what-is-immutable-infrastructure is a good article.
In this specific case, it's just easier and faster to restore from scratch than try to track and figure what state the system is in. All this said, I totally understand this doesn't work if one has to download 100s of gigs or the download takes hours, so I am not putting my head in the sand
One thing is that if you as an admin are "confident" that it's all downloaded and good, you can use the CLI tool to
cloudron import --in-place --app <app>and that will actually repair the app in-place. This is not exposed in the UI for the reason above - it only works if you are sure that everything is downloaded.@girish said in When restoring Cloudron, two apps didn't complete due to DNS propagation... how to resume without needing to restore again?:
ne thing is that if you as an admin are "confident" that it's all downloaded and good
Perhaps there's a log where one can confirm the download is "good" and error="null" .
-
@d19dotca said in When restoring Cloudron, two apps didn't complete due to DNS propagation... how to resume without needing to restore again?:
I think the "industry standard" would be to only reattempt what actually failed.
Actually, atleast in cloud computing, we go more towards immutable infrastructure. This is mostly because it's cheaper, more predictable to build something from scratch (so ironically for your car example, a missing tyre means rebuilding the car is actually cheaper and faster than figuring out how to replace the tyre). In the past, I have dealt with puppet/chef/capistrano/cloudformation style systems which will try to read in the server's current state and try to update and sync with the declarative configs and they all fail in various ways. This is mostly because there are too many variables in a mutable system. It's instead just simpler to start from scratch. https://www.digitalocean.com/community/tutorials/what-is-immutable-infrastructure is a good article.
In this specific case, it's just easier and faster to restore from scratch than try to track and figure what state the system is in. All this said, I totally understand this doesn't work if one has to download 100s of gigs or the download takes hours, so I am not putting my head in the sand
One thing is that if you as an admin are "confident" that it's all downloaded and good, you can use the CLI tool to
cloudron import --in-place --app <app>and that will actually repair the app in-place. This is not exposed in the UI for the reason above - it only works if you are sure that everything is downloaded.@girish So I tried it now, but it seems stuck at "Configuring reverse proxy"... it isn't failing but isn't proceeding from it either (about 10 minutes now). Is that expected when the DNS provider is "noop"? In other words, should I just leave it? Or will this impact other processes down the road like the scheduled backups for Cloudron?
cloudron import --in-place --app 200d36ca-8109-409a-9b56-07f46c2f09bd => Queued => Cleaning up old install => Importing addons in-place .. => Configuring reverse proxy ........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
Edit: I actually just realized why, which makes sense I guess. It's trying to get the cert and failing.
May 18 14:25:17 box:cert/acme2 waitForChallenge: status is "invalid" {"type":"http-01","status":"invalid","error":{"type":"urn:ietf:params:acme:error:unauthorized","detail":"Invalid response from http://www.<domain>.com/.well-known/acme-challenge/an6npW86bKK-xL88iivlKjtRFxhvRuqO1xMHbiFkHr0 [<IP>]: \"<html>\\r\\n<head><title>404 Not Found</title></head>\\r\\n<body>\\r\\n<center><h1>404 Not Found</h1></center>\\r\\n<hr><center>nginx</center>\\r\\n\"","status":403},"url":"https://acme-v02.api.letsencrypt.org/acme/chall-v3/13239568197/mTMq3A","token":"an6npW86bKK-xL88iivlKjtRFxhvRuqO1xMHbiFkHr0","validationRecord":[{"url":"http://www.<domain>.com/.well-known/acme-challenge/an6npW86bKK-xL88iivlKjtRFxhvRuqO1xMHbiFkHr0","hostname":"www.<domain>","port":"80","addressesResolved":["51.222.174.82"],"addressUsed":"<IP>"}],"validated":"2021-05-18T21:21:53Z"}I thought "noop" made it so it didn't care about getting that stuff though either, no? Or is "noop" only good for skipping DNS verifications?
--
Dustin Dauncey
www.d19.ca -
@girish So I tried it now, but it seems stuck at "Configuring reverse proxy"... it isn't failing but isn't proceeding from it either (about 10 minutes now). Is that expected when the DNS provider is "noop"? In other words, should I just leave it? Or will this impact other processes down the road like the scheduled backups for Cloudron?
cloudron import --in-place --app 200d36ca-8109-409a-9b56-07f46c2f09bd => Queued => Cleaning up old install => Importing addons in-place .. => Configuring reverse proxy ........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
Edit: I actually just realized why, which makes sense I guess. It's trying to get the cert and failing.
May 18 14:25:17 box:cert/acme2 waitForChallenge: status is "invalid" {"type":"http-01","status":"invalid","error":{"type":"urn:ietf:params:acme:error:unauthorized","detail":"Invalid response from http://www.<domain>.com/.well-known/acme-challenge/an6npW86bKK-xL88iivlKjtRFxhvRuqO1xMHbiFkHr0 [<IP>]: \"<html>\\r\\n<head><title>404 Not Found</title></head>\\r\\n<body>\\r\\n<center><h1>404 Not Found</h1></center>\\r\\n<hr><center>nginx</center>\\r\\n\"","status":403},"url":"https://acme-v02.api.letsencrypt.org/acme/chall-v3/13239568197/mTMq3A","token":"an6npW86bKK-xL88iivlKjtRFxhvRuqO1xMHbiFkHr0","validationRecord":[{"url":"http://www.<domain>.com/.well-known/acme-challenge/an6npW86bKK-xL88iivlKjtRFxhvRuqO1xMHbiFkHr0","hostname":"www.<domain>","port":"80","addressesResolved":["51.222.174.82"],"addressUsed":"<IP>"}],"validated":"2021-05-18T21:21:53Z"}I thought "noop" made it so it didn't care about getting that stuff though either, no? Or is "noop" only good for skipping DNS verifications?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login