Essential information about failures are not forwarded to the sysadmin
-
@nebulon backup failed completely yesterday without any notification. so I missed a complete day of backup without being informed about it. that's not acceptable!
@chymian-0 if it failed completely even after retry, it indeed should have notified, we have to check why this didn't happen.
-
@chymian-0 if it failed completely even after retry, it indeed should have notified, we have to check why this didn't happen.
@nebulon, ok now I'm getting to understand you better.
It should have sent a mail after complete failure of backup, not only after 3 days… - I see.but even in the past, when backup failed, I got only 1 single mail.
from my understanding now, it should have sent me a mail per try - which never happened.thx for clarification.
do you need any logs/info? -
@nebulon, ok now I'm getting to understand you better.
It should have sent a mail after complete failure of backup, not only after 3 days… - I see.but even in the past, when backup failed, I got only 1 single mail.
from my understanding now, it should have sent me a mail per try - which never happened.thx for clarification.
do you need any logs/info?@chymian-0 Side note not meant to derail the great conversation (as I can certainly see both sides to the equation here)... If your backups are critical (which they are for many of us), it'll be infinitely better to backup multiple times a day, not just once. As a side benefit, you'd be notified sooner if any failures too. Personally I backup about 4 times a day (though I tweak this occasionally).
-
@chymian-0 if it failed completely even after retry, it indeed should have notified, we have to check why this didn't happen.
@nebulon It may be a good idea to allow customization of the notification system, so that those users who deem everything uber critical (for business reasons and such) can be notified upon every failure, and those who are more using Cloudron for their hobby can choose to not be bugged by failures as often due to the very real reason that led to this change in the first place... too many false-positives or intermittent issues that no sysadmin can necessarily do anything about anyways (i.e. if the object storage provider is having issues).
If you want to keep it 'simple' still, then maybe just have two options for users... aggressive or non-aggressive. lol.
-
To add to this: the backup failure notifications after three failures and not after 3 days. So, if you have backups at a higher interval, you will get notified soon enough.
-
-
@jdaviescoates There's two levels of retry - things like network errors, transient api errors etc are retried immediately. The other retry is in the next scheduled backup time. There is no other retry between scheduled backup time.
Just chiming in here because I came back from a short trip and thought everything would be okay (since I didn't get any emails that said otherwise) but then I saw this (no, the first notification is not about the primary domain):
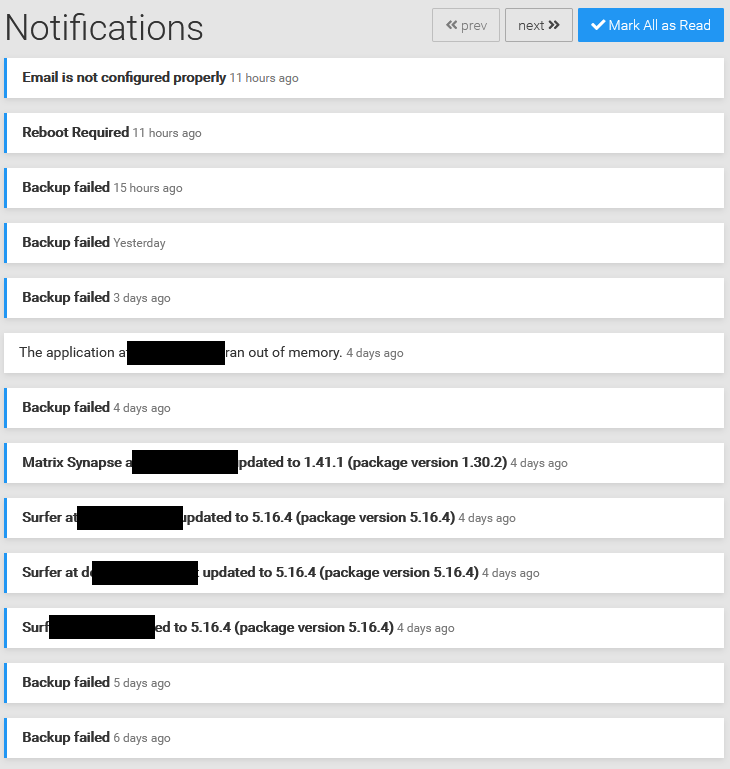
and the Backup-view
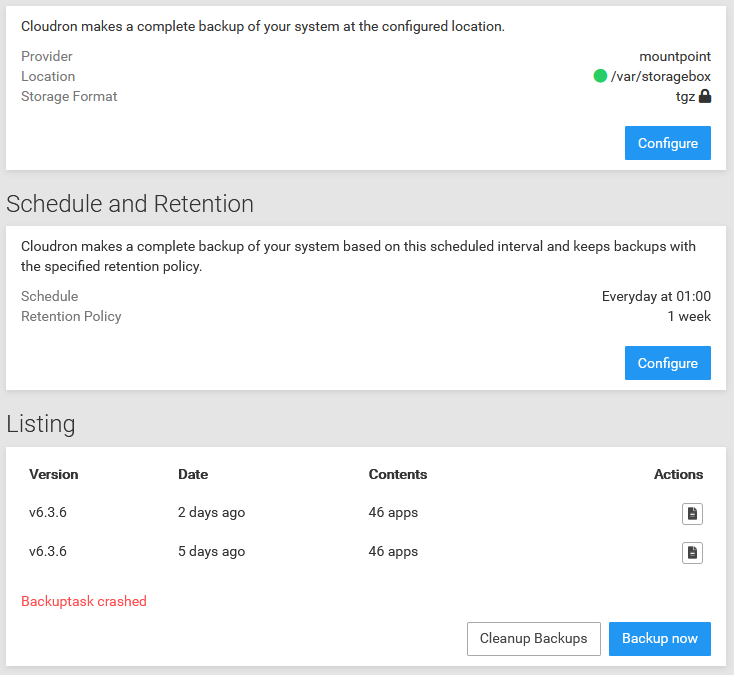
So instead of 7 backups (1 per day) I only got two left, the others apparently got cleaned after the backup failed.
Here are my questions:
As you can see, I'm using encrypted tgz as storage format. Wouldn't it double the required space if I added more times to the scheduler?
Why was there no notification if it failed so often?
The logs of the last crash (the app in question was the culprit for earlier crashes, a mid-size Magento store whose cache might interfere with the backup process, but I thought we fixed that along the way):
Sep 13 01:09:35 box:backups some-app.at Unable to backup BoxError: Backuptask crashed at /home/yellowtent/box/src/backups.js:901:29 at f (/home/yellowtent/box/node_modules/once/once.js:25:25) at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:77:9) at ChildProcess.emit (events.js:315:20) at Process.ChildProcess._handle.onexit (internal/child_process.js:277:12) { reason: 'Internal Error', details: {} -
Just chiming in here because I came back from a short trip and thought everything would be okay (since I didn't get any emails that said otherwise) but then I saw this (no, the first notification is not about the primary domain):
and the Backup-view
So instead of 7 backups (1 per day) I only got two left, the others apparently got cleaned after the backup failed.
Here are my questions:
As you can see, I'm using encrypted tgz as storage format. Wouldn't it double the required space if I added more times to the scheduler?
Why was there no notification if it failed so often?
The logs of the last crash (the app in question was the culprit for earlier crashes, a mid-size Magento store whose cache might interfere with the backup process, but I thought we fixed that along the way):
Sep 13 01:09:35 box:backups some-app.at Unable to backup BoxError: Backuptask crashed at /home/yellowtent/box/src/backups.js:901:29 at f (/home/yellowtent/box/node_modules/once/once.js:25:25) at ChildProcess.<anonymous> (/home/yellowtent/box/src/shell.js:77:9) at ChildProcess.emit (events.js:315:20) at Process.ChildProcess._handle.onexit (internal/child_process.js:277:12) { reason: 'Internal Error', details: {}@msbt said in Essential information about failuers are not forwarded to the sysadmin:
Why was there no notification if it failed so often?
It should have tried to send an email notification. Let me log this, so in the future we can atleast identify if the email is not sent out at all or if the email failed to send or some other issue.
-
@msbt said in Essential information about failuers are not forwarded to the sysadmin:
Why was there no notification if it failed so often?
It should have tried to send an email notification. Let me log this, so in the future we can atleast identify if the email is not sent out at all or if the email failed to send or some other issue.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login