Solved! Thanks a lot! (re)installation works.
Do I have to pay attention to any follow-up measures? Or can I leave the administration to Cloudron again?
Solved! Thanks a lot! (re)installation works.
Do I have to pay attention to any follow-up measures? Or can I leave the administration to Cloudron again?
Hello Nebulon,
yes, the restart still fails. When I run the reinstall command, a message appears that two new packages are being installed: libunbound8 and unbound-anchor.
So could this be the problem?
If I have changed any configurations, I don't know how, because normally I don't access the server via ssh, but let cloudron manage everything. I only use ssh for disk adjustments or specific instructions from the Cloudron interface. 

However. I have started the reinstallation and will wait and see. It is currently taking a while (approx. 5 minutes). The latest message is Setting up unbound (1.19.2-1ubuntu3.3) ...
Thanks for the inputs so far !
root@...:~# /usr/sbin/unbound -dv
[1731569630] unbound[455868:0] notice: Start of unbound 1.19.2.
I searched how to updating root achor and found this thread: https://forum.cloudron.io/topic/12496/unbound-anchor-not-found-in-ubuntu-24-04/2
When I run apt list --installed | grep unbound there is an entry unbound/noble-updates,noble-security,now 1.19.2-1ubuntu3.3 amd64 [installed].
When I check for installable unbound packages, there are two:
unbound/noble-updates,noble-security,now 1.19.2-1ubuntu3.3 amd64 [installed]
unbound/noble 1.19.2-1ubuntu3 amd64
Do I need to install the second too?
Via SSH the command cloudron-support --troubleshoot returned
[WARN] Domain [domain.tld] expiry check skipped because whois does not have this information
unbound is down. updating root anchor to see if it fixes it
And this from the Service log:
systemd[1]: Starting unbound.service - Unbound DNS Resolver...
systemd[1]: unbound.service: Control process exited, code=exited, status=203/EXEC
systemd[1]: unbound.service: Failed with result 'exit-code'.
@nebulon Thank you, the unbound service is not running and don't starts when I trigger the restart in the services.
In the logs I see related messages (i guess)
at genericNodeError (node:internal/errors:984:15)
at wrappedFn (node:internal/errors:538:14)
at ChildProcess.exithandler (node:child_process:422:12)
at ChildProcess.emit (node:events:518:28)
at maybeClose (node:internal/child_process:1105:16)
at Socket.<anonymous> (node:internal/child_process:457:11)
at Socket.emit (node:events:518:28)
at Pipe.<anonymous> (node:net:337:12) {
code: 3,
killed: false,
signal: null,
cmd: 'systemctl is-active unbound'
}
Nov 13 14:55:55 box:shell statusUnbound: systemctl with args is-active unbound errored Error: Command failed: systemctl is-active unbound
Could that help to solve the Problem?
@joseph Hi I have the same problem, only I don't think it's a firewall problem because I haven't changed anything and I assume that Cloudron manages the firewall so that everything works fine.
Anyways: I am running Cloudron v8.0.6 (Ubuntu 24.04 LTS) and the command host -t NS {{domain.tld}} 127.0.0.150 gives me the following message:

Any ideas what I could try?
Thanks a lot!
Located the problem: it's something about the password length. Tested it with different length with a shorter password it works now
Solved: I don't know what was wrong, but I canceled the connection and re-connected my instance to my rocket.chat account. Works fine now....
@jdaviescoates Thanks for the advise but unfortunately it didn't help.
I did a fresh install to for double-check it. (But also never changed anything in the configurations before or used any authentication other than cloudron group)
Install-screen:
(Yes, I am in the selected Group ") )
)
Login-Screen (User or PWD incorrect)
Log from Login:

However, there is no hint/reason for this error there either - or do I just not see it?
It seems to work with the email address of the user but the connection wont be established. The process stands still with the following screen:
When I use only the username there is the error "Incorrect username or password"
Can you assume, whats the reason for that?
(I already checked the firewall rules of the hoster (Hetzner))
Hi again,
just did an update again
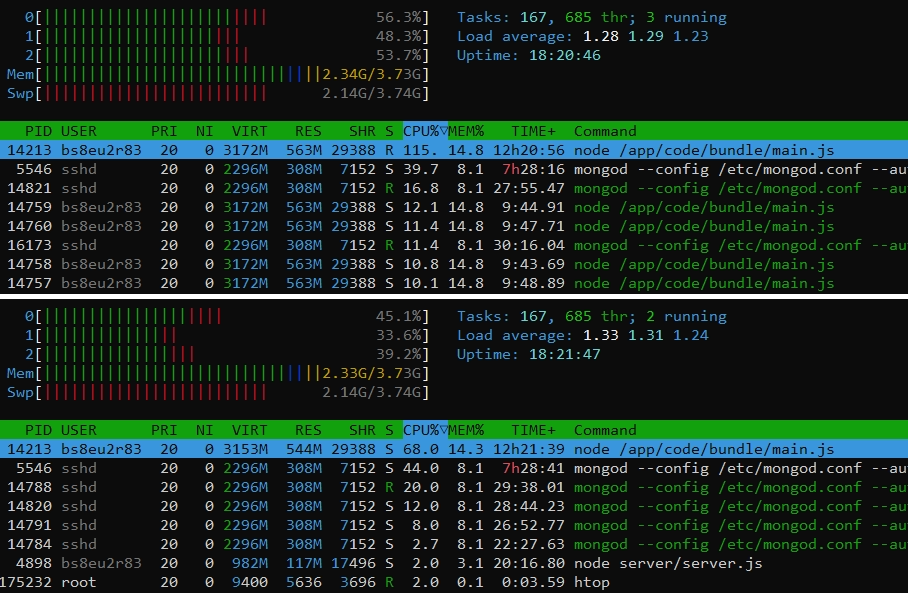
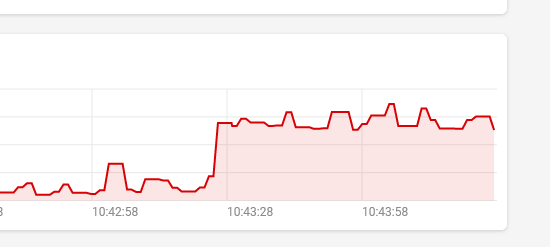
... and watched the cpu load. First it was nice but after a while (maybe 15 minutes) the load rises again (10:43)
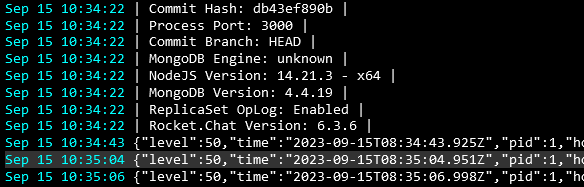
But the last log messages of Rocket-Chat were from 10:35...
Do you know if there is any way to find out, which process of Rocket.Chat rises the cpu load?
@Aizat said in Authentication support?:
@nebulon I'm still getting the authentication issue, when I use my Cloudron login username, it doesn't authenticate me, and says incorrect pwd or username. Then I tried my Cloudron email, it just connecting...
Do I need to change/add something in the "jitsi-meet-config.js"?
Hello, have you been able to solve this problem? I would like to use the cloudron authentication...
Update: Rocket.Chat updated to package version 2.39.1 (v. 6.3.1) but the cpu usage is still high.. I'll have to keep looking.
https://github.com/H2-invent/open-datenschutzcenter
https://open-datenschutzcenter.de/
Granted, this app may not affect a large amount of users, but it is a software that can make life immensely easier if you are responsible for or have to manage data protection (DSGVO / GDPR) in companies or organizations/assosiations.
Yes, i saw some posts to older versions too but thought none fits to my situation.. also tried some setting-changes - but none of them was the solution..
I restarted the app again and the log looks quite well - there occures just one error from time to time while startup:
"=> Healtheck error: Error: connect ECONNREFUSED 172.18.16.54:3000"
But im not sure if it has any affect on the cpu usage in my case, cause htop shows that a js-file causes the cpu usage (between 70 and 115) and not the db server