Notifications not showing for backup failures with no disk space left
-
It seems that ever since 7.2, whenever a backup fails because of lack of disk space, there's no notification in the dashboard. Was that change by design or is that a defect in 7.2.5? If by design, how many failures would it take to then show a notification?
FWIW, my two cents... notifications should be done in the Dashboard for things which usually would require a manual intervention such as disk space issues, but could reasonably be delayed in showing for things that are often just intermittent like connection delays / timeouts, etc.
If this is by design, is it possible to modify that behaviour at all? And if a defect, is there anything I can do to help?
Here's the logs of the latest failure in my backup, but there's no actual notification present in my Dashboard:
Jul 13 07:16:01 box:tasks update 15964: {"percent":98.5,"message":"Copying /mnt/cloudron-backups/snapshot/box to /mnt/cloudron-backups/2022-07-13-140001-726/box_v7.2.5"} Jul 13 07:16:01 box:shell copy spawn: /bin/cp -al /mnt/cloudron-backups/snapshot/box /mnt/cloudron-backups/2022-07-13-140001-726/box_v7.2.5 Jul 13 07:16:01 box:shell copy (stdout): /bin/cp: cannot create directory '/mnt/cloudron-backups/2022-07-13-140001-726/box_v7.2.5': No space left on device Jul 13 07:16:01 box:shell copy code: 1, signal: null Jul 13 07:16:01 box:backuptask copy: copied successfully to 2022-07-13-140001-726/box_v7.2.5. Took 0.012 seconds Jul 13 07:16:01 box:taskworker Task took 960.252 seconds Jul 13 07:16:01 box:tasks setCompleted - 15964: {"result":"box_box_v7.2.5_fb71c1c5c67946490199748613b423eca452263507d79d4e049de5440b1d86ef","error":null} Jul 13 07:16:01 box:tasks update 15964: {"percent":100,"result":"box_box_v7.2.5_fb71c1c5c67946490199748613b423eca452263507d79d4e049de5440b1d86ef","error":null}By the way... I noticed that it ends with "error: null" so maybe that's why it's not triggering a failure? But earlier in the logs it shows
No space left on deviceand a copy code of 1, so I presume it failed... right?--
Dustin Dauncey
www.d19.ca -
It seems that ever since 7.2, whenever a backup fails because of lack of disk space, there's no notification in the dashboard. Was that change by design or is that a defect in 7.2.5? If by design, how many failures would it take to then show a notification?
FWIW, my two cents... notifications should be done in the Dashboard for things which usually would require a manual intervention such as disk space issues, but could reasonably be delayed in showing for things that are often just intermittent like connection delays / timeouts, etc.
If this is by design, is it possible to modify that behaviour at all? And if a defect, is there anything I can do to help?
Here's the logs of the latest failure in my backup, but there's no actual notification present in my Dashboard:
Jul 13 07:16:01 box:tasks update 15964: {"percent":98.5,"message":"Copying /mnt/cloudron-backups/snapshot/box to /mnt/cloudron-backups/2022-07-13-140001-726/box_v7.2.5"} Jul 13 07:16:01 box:shell copy spawn: /bin/cp -al /mnt/cloudron-backups/snapshot/box /mnt/cloudron-backups/2022-07-13-140001-726/box_v7.2.5 Jul 13 07:16:01 box:shell copy (stdout): /bin/cp: cannot create directory '/mnt/cloudron-backups/2022-07-13-140001-726/box_v7.2.5': No space left on device Jul 13 07:16:01 box:shell copy code: 1, signal: null Jul 13 07:16:01 box:backuptask copy: copied successfully to 2022-07-13-140001-726/box_v7.2.5. Took 0.012 seconds Jul 13 07:16:01 box:taskworker Task took 960.252 seconds Jul 13 07:16:01 box:tasks setCompleted - 15964: {"result":"box_box_v7.2.5_fb71c1c5c67946490199748613b423eca452263507d79d4e049de5440b1d86ef","error":null} Jul 13 07:16:01 box:tasks update 15964: {"percent":100,"result":"box_box_v7.2.5_fb71c1c5c67946490199748613b423eca452263507d79d4e049de5440b1d86ef","error":null}By the way... I noticed that it ends with "error: null" so maybe that's why it's not triggering a failure? But earlier in the logs it shows
No space left on deviceand a copy code of 1, so I presume it failed... right?@d19dotca We wait for 3 backup failures before raising the notification. This change was made because previously the complaint was that we should not raise a notification immediately just because one backup failed (since network, disk etc can all fail in various ways intermittently).
What do you think can be made configurable here? I think spotting specific errors like "no disk space" is not easy since it involves grepping the output of various tools.
-
 G girish marked this topic as a question on
G girish marked this topic as a question on
-
@d19dotca We wait for 3 backup failures before raising the notification. This change was made because previously the complaint was that we should not raise a notification immediately just because one backup failed (since network, disk etc can all fail in various ways intermittently).
What do you think can be made configurable here? I think spotting specific errors like "no disk space" is not easy since it involves grepping the output of various tools.
@girish That’s fair, I understand it may not be an easy fix. In an ideal world (and why I’m raising it), errors such as no disk space left would trigger an immediate alert because there basically has to be a manual intervention to fix as opposed to just transient network errors for example.
My fear here is for people who only backup once a day or once a week for example, then the current logic would dictate that the admin would be without backups for 3 days or even 3 weeks before being notified, depending on their backup schedule. I think that’s where the 3x rule currently falls apart.
Some possible solutions / improvements:
- Maybe it’s possible to trigger an alert based on timing… for example if it’s been 24 hours since the first failure and there’s been no successful backup since then… then throw the alert.
- Maybe the simplest solution is to make it a 2x rule instead for now?
- Or maybe we can just simply have that number be configurable? So for example we can set how many failures we are willing to accept before we are notified? Maybe that’s the better solution for now if we can’t easily decipher the type of error and make logic based off that?
- Lastly maybe the logic can change based on the type of backup endpoint? For example, there will basically never be network issues when backing up to a local disk / mounted disk, it should only really fail in a scenario where the disk isn’t mounted properly or if the disk is full, both requiring manual intervention. When it’s an hosted s3 type of backup though there’d be a lot more things that can happen and most of it would be outside the control of the user so in that case makes sense not to alert so often.
Hopefully that makes sense.
") Let me know if I can clarify at all.
Let me know if I can clarify at all.--
Dustin Dauncey
www.d19.ca -
@girish That’s fair, I understand it may not be an easy fix. In an ideal world (and why I’m raising it), errors such as no disk space left would trigger an immediate alert because there basically has to be a manual intervention to fix as opposed to just transient network errors for example.
My fear here is for people who only backup once a day or once a week for example, then the current logic would dictate that the admin would be without backups for 3 days or even 3 weeks before being notified, depending on their backup schedule. I think that’s where the 3x rule currently falls apart.
Some possible solutions / improvements:
- Maybe it’s possible to trigger an alert based on timing… for example if it’s been 24 hours since the first failure and there’s been no successful backup since then… then throw the alert.
- Maybe the simplest solution is to make it a 2x rule instead for now?
- Or maybe we can just simply have that number be configurable? So for example we can set how many failures we are willing to accept before we are notified? Maybe that’s the better solution for now if we can’t easily decipher the type of error and make logic based off that?
- Lastly maybe the logic can change based on the type of backup endpoint? For example, there will basically never be network issues when backing up to a local disk / mounted disk, it should only really fail in a scenario where the disk isn’t mounted properly or if the disk is full, both requiring manual intervention. When it’s an hosted s3 type of backup though there’d be a lot more things that can happen and most of it would be outside the control of the user so in that case makes sense not to alert so often.
Hopefully that makes sense.
Let me know if I can clarify at all.@d19dotca
My 2p : the discussion is valid and the points are worth considering, and I wouldn't want to detract from resolving it.But in the interim I would recommend setting up ntfy.sh, using their free hosted service or installing my custom cloudron app with a cron job which reports on disk space.
I get a morning report on all servers similar to this :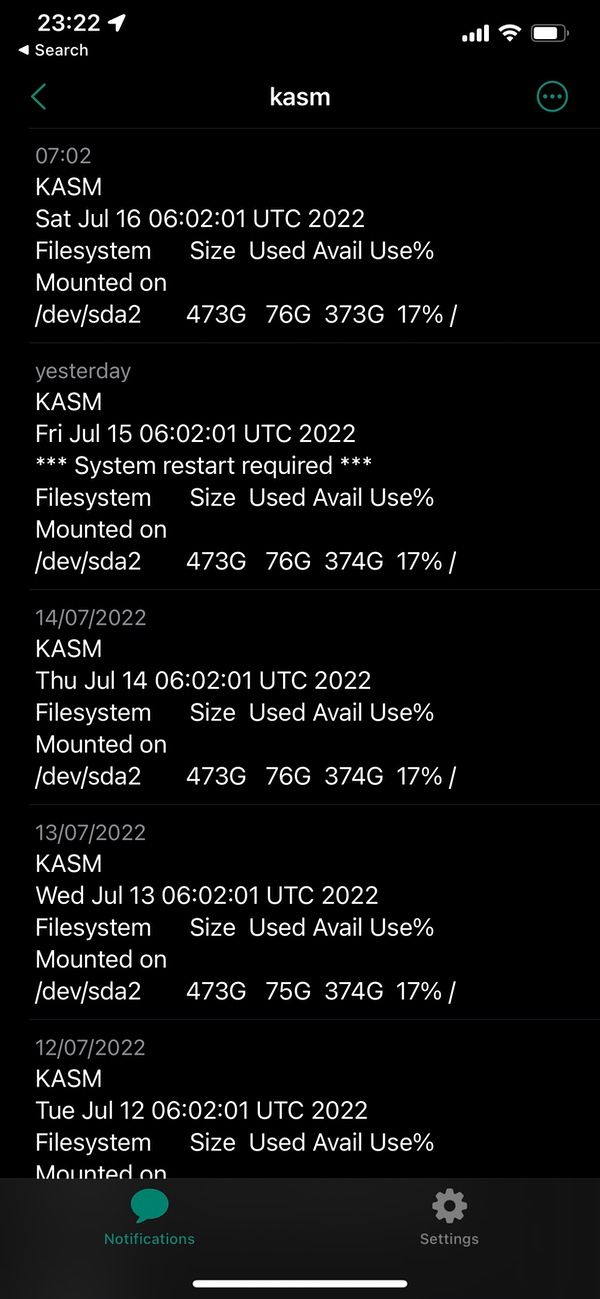
If disk space is fast changing, adjust cron job frequency to e.g. hourly.
Cron job is just simple bash script as below.
This could be improved with a conditional IF based on parsed output ofdf -hcommand whether to send a notification according to free space remaining.
Remote backup storage can be queried using e.g.rclone size remoteserver: >> /root/ntfy-msg.txt#!/bin/bash echo 'KASM' > /root/ntfy-msg.txt date >> /root/ntfy-msg.txt if [ -f /var/run/reboot-required ]; then cat /var/run/reboot-required >> /root/ntfy-msg.txt fi df -h / >> ntfy-msg.txt curl https://ntfy.domain.tld/kasm -T /root/ntfy-msg.txtI like seeing the raw results each morning, so have not yet added conditional logic to the bash script.
But I do query remote storage such as Scaleway and Hetzner Storage Box for free space, and send notification based on that.I know this is not at all a solution to the issue, but it is an immediate workaround because having a current backup is critical to system security.
Indie app dev, huge fan of Cloudron PaaS, scratching my itches : communityapps.appx.uk
-
@d19dotca
My 2p : the discussion is valid and the points are worth considering, and I wouldn't want to detract from resolving it.But in the interim I would recommend setting up ntfy.sh, using their free hosted service or installing my custom cloudron app with a cron job which reports on disk space.
I get a morning report on all servers similar to this :If disk space is fast changing, adjust cron job frequency to e.g. hourly.
Cron job is just simple bash script as below.
This could be improved with a conditional IF based on parsed output ofdf -hcommand whether to send a notification according to free space remaining.
Remote backup storage can be queried using e.g.rclone size remoteserver: >> /root/ntfy-msg.txt#!/bin/bash echo 'KASM' > /root/ntfy-msg.txt date >> /root/ntfy-msg.txt if [ -f /var/run/reboot-required ]; then cat /var/run/reboot-required >> /root/ntfy-msg.txt fi df -h / >> ntfy-msg.txt curl https://ntfy.domain.tld/kasm -T /root/ntfy-msg.txtI like seeing the raw results each morning, so have not yet added conditional logic to the bash script.
But I do query remote storage such as Scaleway and Hetzner Storage Box for free space, and send notification based on that.I know this is not at all a solution to the issue, but it is an immediate workaround because having a current backup is critical to system security.
@timconsidine That's a cool idea - I'll definitely look into that (can likely use that for more use-cases too). But yeah I'd like to see the notifications improved directly (if possible) in Cloudron.
--
Dustin Dauncey
www.d19.ca -
@timconsidine That's a cool idea - I'll definitely look into that (can likely use that for more use-cases too). But yeah I'd like to see the notifications improved directly (if possible) in Cloudron.
@d19dotca I have updated my
bashscript to check for disk used status and then send antfy.shmessage using self-hostedntfyAdapted the script from https://scriptcrunch.com/linux-shell-script-to-automate-disk-usage-monitoring/ which is designed for email if people prefer an email.
#!/bin/bash VALUE=80 for line in $(df -hP | egrep '^/dev/sda2' | awk '{ print $1 "_:_" $5 }') do FILESYSTEM=$(echo "$line" | awk -F"_:_" '{ print $1 }') DISK_USAGE=$(echo "$line" | awk -F"_:_" '{ print $2 }' | cut -d'%' -f1 ) if [ $DISK_USAGE -ge $VALUE ]; then echo 'MyDocker - DISK ALERT !!' >> /root/disk-msg.txt date >> /root/disk-msg.txt echo $FILESYSTEM " is now " $DISK_USAGE "%" >> /root/disk-msg.txt curl https://ntfy.domain.tld/mydocker -T /root/disk-msg.txt rm /root/disk-msg.txt fi doneHope it helps someone.
This scrip runs very 4 hours viacron -
Personally, our requirements are very basic. We wish to have some global notification settings for warnings and alters via email. So if we're not checking our Cloudron dashboard frequently, we nevertheless miss important things to handle as admins.
Failed backups or inaccessible backup locations could be part of these notifications via email.
-
-
G girish has marked this topic as solved on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login