@girish said in Error During GitLab Update (16.11.2 -> 17.0.1): Insufficient Disk Space:
app -> recovery -> repair
Also tried this method but It doesn't seems working
@girish said in Error During GitLab Update (16.11.2 -> 17.0.1): Insufficient Disk Space:
app -> recovery -> repair
Also tried this method but It doesn't seems working
Hi @girish,
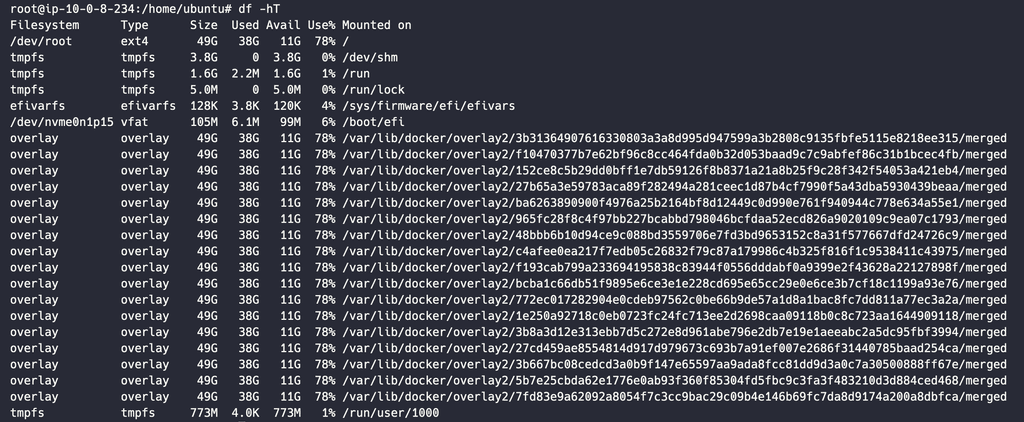
I checked the server earlier, and there is already 11GB of available storage left on the EC2 instance.
I encountered an error while updating GitLab from version 16.11.2 to 17.0.1. The error message is:
An error occurred during the update operation: FileSystem Error: failed to register layer: Error processing tar file(exit status 1): write /home/git/gitaly/_build/intermediate/praefect: no space left on device


Although I've verified sufficient space on the server and for services, the error suggests the disk might be full. It's important to note that this is a new configuration and doesn't currently contain any repositories.


Please advise anyone who has encountered this issue, how to proceed with the given the limited disk space.
Hi All,
I'm currently exploring clients options for testing REST APIs and GraphQL endpoints and I'm eager to learn about the clients and tools you have used for this purpose. In particular, I'm interested in understanding whether you've come across proprietary or open-source solutions that can be self-hosted.
On a related note, I've personally used tools like Postman, ThunderClient, and RapidAPI as VS Code extensions for API testing. If you have any recommendations or insights regarding self-hosted REST API / GraphQL testing clients, please share your experiences and suggestions. Thank you!
Hi @girish,
Just to clarify from my end, the issue is not with SSH (git clone). The problem lies with Uptime Kuma. When Cloudflare proxy is enabled, Uptime Kuma monitors the services effectively. However, if the Cloudflare proxy is disabled, Uptime Kuma stops monitoring the services.
I'm using http/s calls for the monitoring
CF Proxy is Off for GitLab

GitLab is down in Uptime Kuma due to CF Proxy Off

I've encountered an issue with Uptime Kuma monitoring in conjunction with Cloudflare proxy settings and I'm seeking some advice or insights to solve this issue.
Here's the scenario: I'm currently utilizing Uptime Kuma for monitoring my services/apps and using Cloudflare for DNS management. When the proxy is enabled in Cloudflare, Uptime Kuma operates as expected and monitors the services effectively. However, if I disable the proxy for certain services/apps like GitLab, Uptime Kuma ceases to watch them and shows as down.
Has anyone else encountered a similar issue or found a workaround for this situation? Your insights and suggestions would be greatly appreciated.
Hi @nebulon,
Below is the error while I'm trying to login in to Grafana, Actually at the time of setup of Grafana, I did change the default username (admin) and password as to the LDAP user
May 08 20:43:48 ERROR[05-08|15:13:48] Error while trying to authenticate user logger=context userId=0 orgId=0 uname= error="cannot remove last grafana admin" remote_addr=172.71.198.118 traceID=
May 08 20:43:48 ERROR[05-08|15:13:48] Request Completed logger=context userId=0 orgId=0 uname= method=POST path=/login status=500 remote_addr=172.71.198.118 time_ms=166 duration=166.861445ms size=66 referer=https://grafana.example.com/login handler=/login
Hi,
I'm facing an issue where I'm not able to log in to Grafana using Cloudron LDAP. Previously, I was able to log in without any issues, but it seems like it has stopped working now. I have tried multiple times, but every time I try to log in, it gives me an error message.
Error while trying to authenticate user
Can someone please assist me in resolving this issue? Let me know if there is any information or logs that needed from my end to help diagnose the problem.
How proxyAuth can be enabled for the App Proxy applications?
Hi @girish, Is there is any ETA for this feature, I'm eagerly looking for this feature.
Hi @malvim,
You can use Tailscale IP for the App Proxy, provided that Tailscale is set up on both servers
Hi @JOduMonT,
I ran Cloudron with a combination of Tailscale & Cloudflared for two weeks without a public IP at my home setup. So far, everything was working well and I didn't encounter any significant issues. Below is the process that I followed:
1# I had two servers - one for Cloudron and the second with docker and docker-compose. Tailscale was installed and configured with Tailscale IP on both servers. The automatic domain configured was disabled in Cloudron and was set manually.
2# I ran the docker-compose.yml file on the second server using the following:
version: '3.8'
services:
tunnel:
image: 'ghcr.io/shmick/docker-cloudflared'
container_name: tunnel
hostname: tunnel
restart: unless-stopped
user: 1000:1000
env_file:
- $PWD/tunnel.env
volumes:
- /etc/timezone:/etc/timezone:ro
command: tunnel run
network_mode: host
TUNNEL_TOKEN={TUNNEL-TOKEN}
3# I set up and configured the domain in the Cloudflared UI, and used HTTPS for the Cloudron Tailscale IP with No TLS Verify enabled.
@macone said in Cloudron not responding:
2023-02-27T05:43:09.235Z box:shell reload (stdout): nginx: [warn] "ssl_stapling" ignored, host not found in OCSP responder "r3.o.lencr.org" in the certificate "/home/yellowtent/platformdata/nginx/cert/_.mydomain.sk.cert" ....
Hi @girish, I'm getting the same issue in my server, earlier after reboot, It was working, but now It's not, I have raised the ticket for the same
Hi @girish, Thanks for the quick fix, It's working as expected
Hi Team,
I didn't find the ENV file for the customization of the Docker Registry UI
URL Themes ENVs
After the server reboot, Nginx was not able to restart, So, I deleted the file
0dfcd907-afca-4e38-8353-6a8d921357d2.conf:137
and restarted the Nginx, now working as usual, Are there any docs for the Proxy App?
While Installing the new Proxy App, I'm getting the below error
Error : Nginx Error - Error reloading nginx: reload exited with code 1 signal null
Logs:
Sep 30 21:43:11 box:shell reload spawn: /usr/bin/sudo -S /home/yellowtent/box/src/scripts/restartservice.sh nginx
Sep 30 21:43:11 box:shell reload (stdout): nginx: [emerg] invalid URL prefix in /etc/nginx/applications/0dfcd907-afca-4e38-8353-6a8d921357d2.conf:137
Sep 30 21:43:11 box:shell reload code: 1, signal: null
Sep 30 21:43:11 box:apptask run: app error for state pending_install: BoxError: Error reloading nginx: reload exited with code 1 signal null
at reload (/home/yellowtent/box/src/reverseproxy.js:183:22)
at processTicksAndRejections (node:internal/process/task_queues:96:5)
at async writeAppNginxConfig (/home/yellowtent/box/src/reverseproxy.js:532:5)
at async writeAppConfigs (/home/yellowtent/box/src/reverseproxy.js:545:9)
at async Object.configureApp (/home/yellowtent/box/src/reverseproxy.js:576:5)
at async install (/home/yellowtent/box/src/apptask.js:424:5) {
reason: 'Nginx Error',
details: {}
@girish Increased the memory to 8GB, noting changes, launched a new container, is working fine, and will export all existing repo to the new Gitlab container...
Hi @girish, below is logs
Jun 15 13:23:50 172.18.0.1 - - [15/Jun/2022:07:53:50 +0000] "GET / HTTP/1.1" 302 94 "-" "Mozilla (CloudronHealth)"
Jun 15 13:23:53 172.18.0.1 - - [15/Jun/2022:07:53:53 +0000] "GET /arshsahzad/DashPanel/edit HTTP/1.1" 200 139401 "https://git.arsh.dev/arshsahzad/DashPanel" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
Jun 15 13:23:54 time="2022-06-15T07:53:54Z" level=info msg=success-client-cache correlation_id=01G5K5NHW98657YT844J7N40GY duration_s=0.000130239 imageresizer.content_type=image/png imageresizer.original_filesize=36947 imageresizer.status=success-client-cache imageresizer.target_width=88 method=GET subsystem=imageresizer uri="/uploads/-/system/project/avatar/43/web-dashboard.png?width=88" written_bytes=0
Jun 15 13:23:54 172.18.0.1 - - [15/Jun/2022:07:53:54 +0000] "GET /uploads/-/system/project/avatar/43/web-dashboard.png?width=88 HTTP/1.1" 304 0 "https://git.arsh.dev/arshsahzad/DashPanel/edit" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
Jun 15 13:23:54 172.18.0.1 - - [15/Jun/2022:07:53:54 +0000] "GET /api/v4/projects/43/badges HTTP/1.1" 304 0 "https://git.arsh.dev/arshsahzad/DashPanel/edit" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
Jun 15 13:23:54 172.18.0.1 - - [15/Jun/2022:07:53:54 +0000] "POST /api/graphql HTTP/1.1" 200 65 "https://git.arsh.dev/arshsahzad/DashPanel/edit" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
Jun 15 13:24:00 172.18.0.1 - - [15/Jun/2022:07:54:00 +0000] "GET / HTTP/1.1" 302 94 "-" "Mozilla (CloudronHealth)"
Jun 15 13:24:05 172.18.0.1 - - [15/Jun/2022:07:54:05 +0000] "POST /arshsahzad/DashPanel HTTP/1.1" 500 3049 "https://git.arsh.dev/arshsahzad/DashPanel/edit" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
Jun 15 13:24:09 172.18.0.1 - - [15/Jun/2022:07:54:09 +0000] "POST /api/graphql HTTP/1.1" 200 65 "https://git.arsh.dev/arshsahzad/DashPanel/edit" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
Jun 15 13:24:10 172.18.0.1 - - [15/Jun/2022:07:54:10 +0000] "GET / HTTP/1.1" 302 94 "-" "Mozilla (CloudronHealth)"
Jun 15 13:24:10 2022-06-15T07:54:10.976Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigration::CiDatabaseWorker jid=ca35bab4cf85f3033d1ea39b INFO: start
Jun 15 13:24:10 2022-06-15T07:54:10.978Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigration::CiDatabaseWorker jid=ca35bab4cf85f3033d1ea39b INFO: arguments: []
Jun 15 13:24:11 2022-06-15T07:54:11.004Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigration::CiDatabaseWorker jid=ca35bab4cf85f3033d1ea39b INFO: {:class=>"Database::BatchedBackgroundMigration::CiDatabaseWorker", :database=>"ci", :message=>"skipping migration execution for unconfigured database"}
Jun 15 13:24:11 2022-06-15T07:54:11.010Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigration::CiDatabaseWorker jid=ca35bab4cf85f3033d1ea39b elapsed=0.034 INFO: done
Jun 15 13:24:11 2022-06-15T07:54:11.011Z pid=137 tid=5p89 class=LooseForeignKeys::CleanupWorker jid=171070d9801655ec17f579a9 INFO: start
Jun 15 13:24:11 2022-06-15T07:54:11.013Z pid=137 tid=5p89 class=LooseForeignKeys::CleanupWorker jid=171070d9801655ec17f579a9 INFO: arguments: []
Jun 15 13:24:11 2022-06-15T07:54:11.030Z pid=137 tid=5p79 class=UserStatusCleanup::BatchWorker jid=984c480b2fa01449deef5006 INFO: start
Jun 15 13:24:11 2022-06-15T07:54:11.049Z pid=137 tid=5p79 class=UserStatusCleanup::BatchWorker jid=984c480b2fa01449deef5006 INFO: arguments: []
Jun 15 13:24:11 2022-06-15T07:54:11.059Z pid=137 tid=5p79 class=UserStatusCleanup::BatchWorker jid=984c480b2fa01449deef5006 elapsed=0.029 INFO: done
Jun 15 13:24:11 2022-06-15T07:54:11.072Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigrationWorker jid=d16371266352e71ff63ca972 INFO: start
Jun 15 13:24:11 2022-06-15T07:54:11.117Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigrationWorker jid=d16371266352e71ff63ca972 INFO: arguments: []
Jun 15 13:24:11 2022-06-15T07:54:11.130Z pid=137 tid=5p79 class=Database::BatchedBackgroundMigrationWorker jid=d16371266352e71ff63ca972 elapsed=0.058 INFO: done
Jun 15 13:24:11 2022-06-15T07:54:11.135Z pid=137 tid=5p79 class=ScheduleMergeRequestCleanupRefsWorker jid=b351a42e61474a1f47862005 INFO: start
Jun 15 13:24:11 2022-06-15T07:54:11.136Z pid=137 tid=5p79 class=ScheduleMergeRequestCleanupRefsWorker jid=b351a42e61474a1f47862005 INFO: arguments: []
Jun 15 13:24:11 2022-06-15T07:54:11.141Z pid=137 tid=5p79 class=ScheduleMergeRequestCleanupRefsWorker jid=b351a42e61474a1f47862005 elapsed=0.006 INFO: done
Jun 15 13:24:11 2022-06-15T07:54:11.142Z pid=137 tid=5p89 class=LooseForeignKeys::CleanupWorker jid=171070d9801655ec17f579a9 elapsed=0.131 INFO: done
Jun 15 13:24:20 172.18.0.1 - - [15/Jun/2022:07:54:20 +0000] "GET / HTTP/1.1" 302 94 "-" "Mozilla (CloudronHealth)"