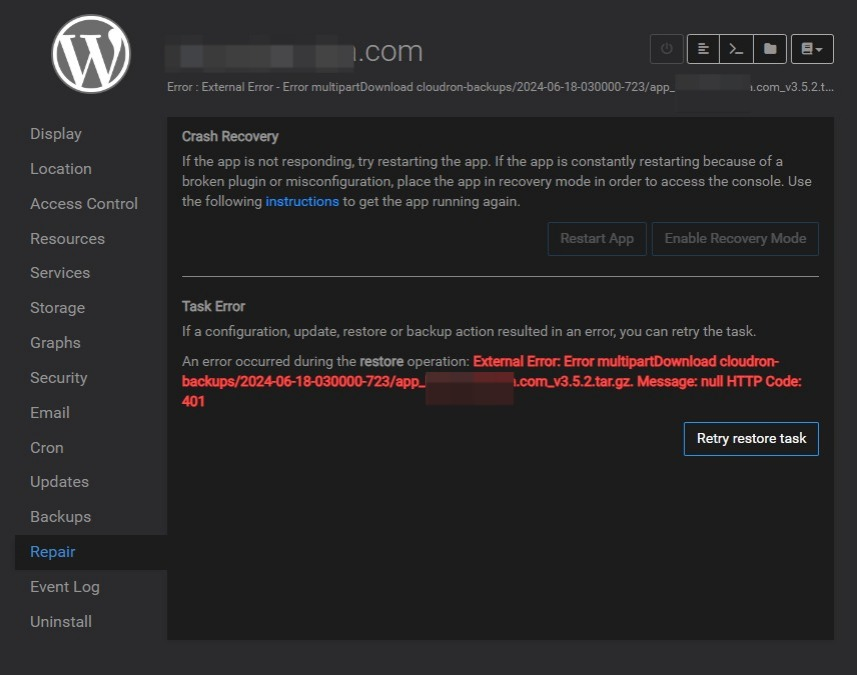
Yes @girish, this is the content of /home/yellowtent/platformdata/logs/tasks/14939.log:
2024-07-29T11:31:16.050Z box:taskworker Starting task 14939. Logs are at /home/yellowtent/platformdata/logs/tasks/14939.log
2024-07-29T11:31:16.255Z box:tasks update 14939: {"percent":1,"message":"Checking disk space"}
2024-07-29T11:31:16.257Z box:shell file execArgs: df ["-B1","--output=source,fstype,size,used,avail,pcent,target","/"]
2024-07-29T11:31:16.346Z box:tasks update 14939: {"percent":5,"message":"Downloading and verifying release"}
2024-07-29T11:31:16.348Z box:shell cleanupOldArtifacts exec: rm -rf /tmp/box-*
2024-07-29T11:31:20.263Z box:shell cleanupOldArtifacts: rm -rf /tmp/box-* errored Error: Command failed: rm -rf /tmp/box-*
rm: cannot remove '/tmp/box-2971389862/node_modules/ssh2/lib/protocol/crypto/build/config.gypi': Permission denied
at genericNodeError (node:internal/errors:984:15)
at wrappedFn (node:internal/errors:538:14)
at ChildProcess.exithandler (node:child_process:422:12)
at ChildProcess.emit (node:events:518:28)
at maybeClose (node:internal/child_process:1105:16)
at ChildProcess._handle.onexit (node:internal/child_process:305:5) {
code: 1,
killed: false,
signal: null,
cmd: 'rm -rf /tmp/box-*'
}
2024-07-29T11:31:20.266Z box:updater BoxError: cleanupOldArtifacts errored with code 1 message Command failed: rm -rf /tmp/box-*
rm: cannot remove '/tmp/box-2971389862/node_modules/ssh2/lib/protocol/crypto/build/config.gypi': Permission denied
at /home/yellowtent/box/src/shell.js:71:23
at ChildProcess.exithandler (node:child_process:430:5)
at ChildProcess.emit (node:events:518:28)
at maybeClose (node:internal/child_process:1105:16)
at ChildProcess._handle.onexit (node:internal/child_process:305:5)
2024-07-29T11:31:20.266Z box:updater downloadUrl: downloading https://releases.cloudron.io/versions.json to /home/yellowtent/platformdata/update/versions.json
2024-07-29T11:31:20.266Z box:shell downloadUrl execArgs: curl ["-s","--fail","https://releases.cloudron.io/versions.json","-o","/home/yellowtent/platformdata/update/versions.json"]
2024-07-29T11:31:21.766Z box:updater downloadUrl: done
2024-07-29T11:31:21.766Z box:updater downloadUrl: downloading https://releases.cloudron.io/versions.json.sig to /home/yellowtent/platformdata/update/versions.json.sig
2024-07-29T11:31:21.766Z box:shell downloadUrl execArgs: curl ["-s","--fail","https://releases.cloudron.io/versions.json.sig","-o","/home/yellowtent/platformdata/update/versions.json.sig"]
2024-07-29T11:31:22.568Z box:updater downloadUrl: done
2024-07-29T11:31:22.569Z box:updater gpgVerify: /usr/bin/gpg --status-fd 1 --no-default-keyring --keyring /home/yellowtent/box/src/releases.gpg --verify /home/yellowtent/platformdata/update/versions.json.sig /home/yellowtent/platformdata/update/versions.json
2024-07-29T11:31:22.569Z box:shell gpgVerify execArgs: /usr/bin/gpg ["--status-fd","1","--no-default-keyring","--keyring","/home/yellowtent/box/src/releases.gpg","--verify","/home/yellowtent/platformdata/update/versions.json.sig","/home/yellowtent/platformdata/update/versions.json"]
2024-07-29T11:31:22.671Z box:updater downloadUrl: downloading https://releases.cloudron.io/box-8d9043e590-8d9043e590-8.0.2.tar.gz to /home/yellowtent/platformdata/update/box.tar.gz
2024-07-29T11:31:22.672Z box:shell downloadUrl execArgs: curl ["-s","--fail","https://releases.cloudron.io/box-8d9043e590-8d9043e590-8.0.2.tar.gz","-o","/home/yellowtent/platformdata/update/box.tar.gz"]