6.3.3 a few quirks
-
From the log:
POST /api/v1/tasks/3302/stop 409 Conflict task is not active 12.361 ms - 61 Jun 25 19:54:06 box:scheduler sync: error creating jobs (HTTP code 400) unexpected - No such container: def7655c9e0a287873abde909aea7f722c6795a26d91b4ab355d2f3106043ea8Symptom: Configuring (Queued) - Queued in a WordPress app after updating one Cloudron with
3938 apps. Press the x for cancellation does not have any effect. No backup tasks or anything else. Fun fact: a restart does not work (in the sense of pressing the button in the dashboard)Tomorrow I will try to reboot via shell.
@luckow the second line can be ignored, it's not related to the first. the stop button does not work immediately after an update because the update is sort of still "happening" in the background (because we want user to see the dashboard as early as possible). after some time, do you see all the configuring things moving ahead? only at that point will the stop button work. I guess "queued" is a geeky term but it means that at some point a task will be started.
-
@luckow the second line can be ignored, it's not related to the first. the stop button does not work immediately after an update because the update is sort of still "happening" in the background (because we want user to see the dashboard as early as possible). after some time, do you see all the configuring things moving ahead? only at that point will the stop button work. I guess "queued" is a geeky term but it means that at some point a task will be started.
-
Waiting for (let's say) 1 hour for updating/configuring all 39 app is ok. 7 hours later, it looks like "something is broken". This is the reason why I want to wait until tomorrow and restart the instance via shell.
Pronouns: he/him | Primary language: German
-
Waiting for (let's say) 1 hour for updating/configuring all 39 app is ok. 7 hours later, it looks like "something is broken". This is the reason why I want to wait until tomorrow and restart the instance via shell.
-
@girish No. As I said in the first comment: no backup task. This was my first idea from a Cloudron administrator's point of view
")
-
@luckow Thanks for access to the server, I found the issue but not sure why it happens yet. The box code temporarily lost connection to the database and caused some state to be lost. Workaround: I did a "systemctl restart box" and it picked up from where it left off.
Thanks for reporting! Let's see how common this is.
2021-06-25T12:07:36.791Z box:apps BoxError: connect ETIMEDOUT at /home/yellowtent/box/src/settingsdb.js:26:36 at Query.queryCallback [as _callback] (/home/yellowtent/box/src/database.js:96:42) at Query.Sequence.end (/home/yellowtent/box/node_modules/mysql/lib/protocol/sequences/Sequence.js:83:24) at /home/yellowtent/box/node_modules/mysql/lib/Pool.js:205:13 at Handshake.onConnect (/home/yellowtent/box/node_modules/mysql/lib/Pool.js:58:9) at Handshake.<anonymous> (/home/yellowtent/box/node_modules/mysql/lib/Connection.js:526:10) at Handshake._callback (/home/yellowtent/box/node_modules/mysql/lib/Connection.js:488:16) at Handshake.Sequence.end (/home/yellowtent/box/node_modules/mysql/lib/protocol/sequences/Sequence.js:83:24) at Protocol.handleNetworkError (/home/yellowtent/box/node_modules/mysql/lib/protocol/Protocol.js:369:14) at PoolConnection.Connection._handleNetworkError (/home/yellowtent/box/node_modules/mysql/lib/Connection.js:418:18) -
I have a similar issue where 55 apps were backed up, but then many had to reconfigure so that took 20m, and all of the apps redirect to the "you found a cloudron in the wild" page.
Restarted Nginx from services menu, no change.
Restarted box from CLI, no change. (It seems we could also use a restart button for thecloudronservice.)
All my apps areoffline.Update: After 30m or so, apps are coming back online.
-
The update has to do a "rebuild" of all the containers and services because of the multi-host changes. This can take a bit depending on how fast the server CPU and disk is. It's best to follow the progress under
/home/yellowtent/platformdata/logs/box.log. That said 30m does seem quite excessive. Maybe the databases are taking a long time to come up? If you can see in the logs where the most time is spent, would be good to know. -
The update has to do a "rebuild" of all the containers and services because of the multi-host changes. This can take a bit depending on how fast the server CPU and disk is. It's best to follow the progress under
/home/yellowtent/platformdata/logs/box.log. That said 30m does seem quite excessive. Maybe the databases are taking a long time to come up? If you can see in the logs where the most time is spent, would be good to know.@girish Hi Girish, I think I had mentioned this a long time ago, but for what it's worth... I think it'd be helpful to include in the release notes a bit of an "info/alert" when there is to be more downtime than usual.
For me, it's alarming and jarring to see a random lengthy update when the usual update time to Cloudron is only a minute or two. So when it unexpectedly takes 10-30+ minutes (depending on performance of the server I guess) due to the containers needing to be re-created for example, it's not the best user experience.
I tend to make "30 minute" maintenance windows to sort of cover myself (and during off-peak hours of course) so the length of downtime isn't necessarily the main issue, but for me at least I was caught by surprise at the length it was taking and started to panic a little thinking something was wrong because it's so unusual for it to take that long. Thankfully I saw the containers being recreated when I looked at the system logs so knew it was okay and just needed some time, but I think having that pre-warning would be very helpful so admins at least know to expect a lengthier update instead of the usual update time.
-
Having the same issue.

Is this what others experienced?
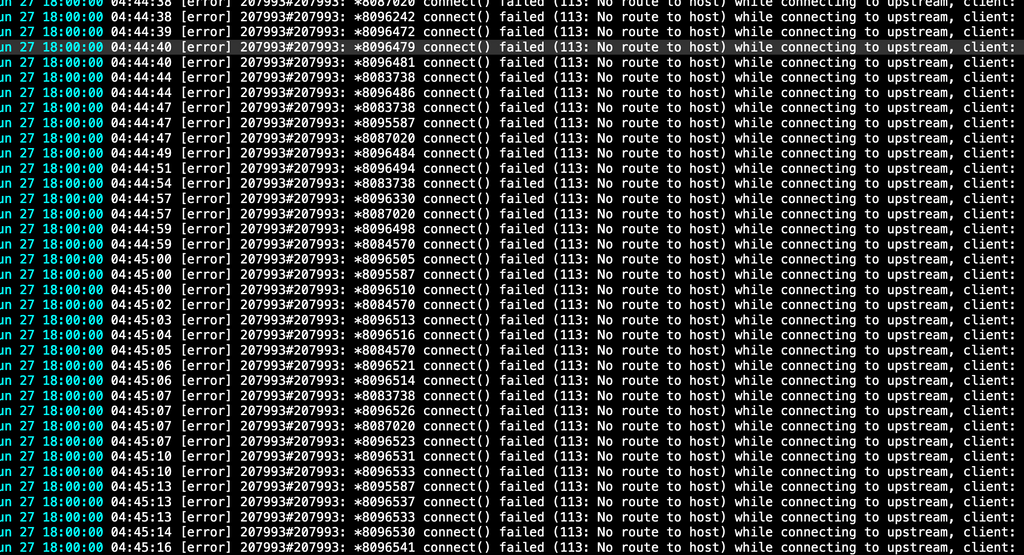
@girish This is my nginx logs... I don't have physical access to the server right now but I can drive over to take a look if you have ideas.
-
Ok so now after a restart it looks like nginx just refuses to start...
Fuck... guess im nuking my install, restoring from wasabi, and praying to the dieties i dont believe in that it just goes back to normal.
@staff any idea what might have gone wrong? Can I set up a time with one of you to do a supervised update?
Also I guess the contents of my volumes are fucked as well...
-
Ok so now after a restart it looks like nginx just refuses to start...
Fuck... guess im nuking my install, restoring from wasabi, and praying to the dieties i dont believe in that it just goes back to normal.
@staff any idea what might have gone wrong? Can I set up a time with one of you to do a supervised update?
Also I guess the contents of my volumes are fucked as well...
-
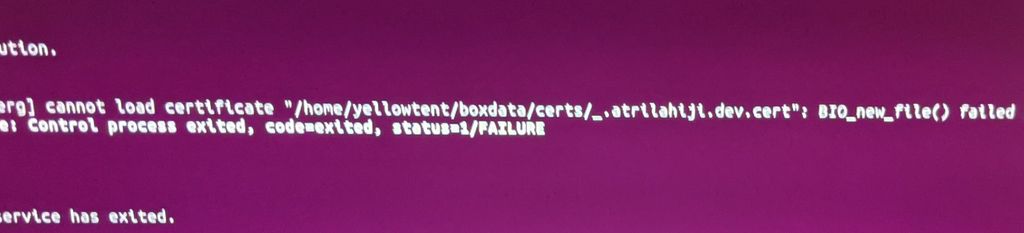
This seems to be the error...
-
@atridad That's not good, do you think I can have access to your server? If you enable SSH access, I can look into first thing tomorrow. thanks and sorry for the issue!
@girish Sure. I'll DM you
EDIT: That works. Only thing is I cant access the dashboard which makes it hard to enable ssh access. I can make you an account if you need? I'm going to be up for the next 2 hours so, so let me know and I can set things up.
-
@girish Sure. I'll DM you
EDIT: That works. Only thing is I cant access the dashboard which makes it hard to enable ssh access. I can make you an account if you need? I'm going to be up for the next 2 hours so, so let me know and I can set things up.
-
@msbt said in 6.3.3 a few quirks:
cloudron-support --enable-ssh
I love you.
Seriously though thanks. I was pacing around trying to figure out how to do this lol
-
Ok at least for @atridad the issue was that for some reason old dashboard nginx configs were still around and referencing old SSL certificates which were now purged from the system. This made nginx fail to startup, causing the rest of the side-effects.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login