Regular short getaddrinfo EAI_AGAIN outages

-
This is an Uptime Kuma quirk that I solved by upping "Retries" on each affected monitor to at least 2. Just one of my 25 monitors needed retries upping to 5 for a fix.
Hope this helps!
Self-hoster with Cloudron, Hetzner, Exoscale, Porkbun & Gandi
-
This is an Uptime Kuma quirk that I solved by upping "Retries" on each affected monitor to at least 2. Just one of my 25 monitors needed retries upping to 5 for a fix.
Hope this helps!
@RoundHouse1924 Thanks, although surely that could just mean that when it tried once it was broken but by the time it retried it was working again? Although I guess the time between retries is tiny?
-
 G girish moved this topic from Support on
G girish moved this topic from Support on
-
That's a fantastic idea! I will add it. I ended up migrating it off Cloudron for the time being because I have come to depend on UK for work and all the notifications were bogging me down.
I will restart the old instance to test and will report back what I find out.
-
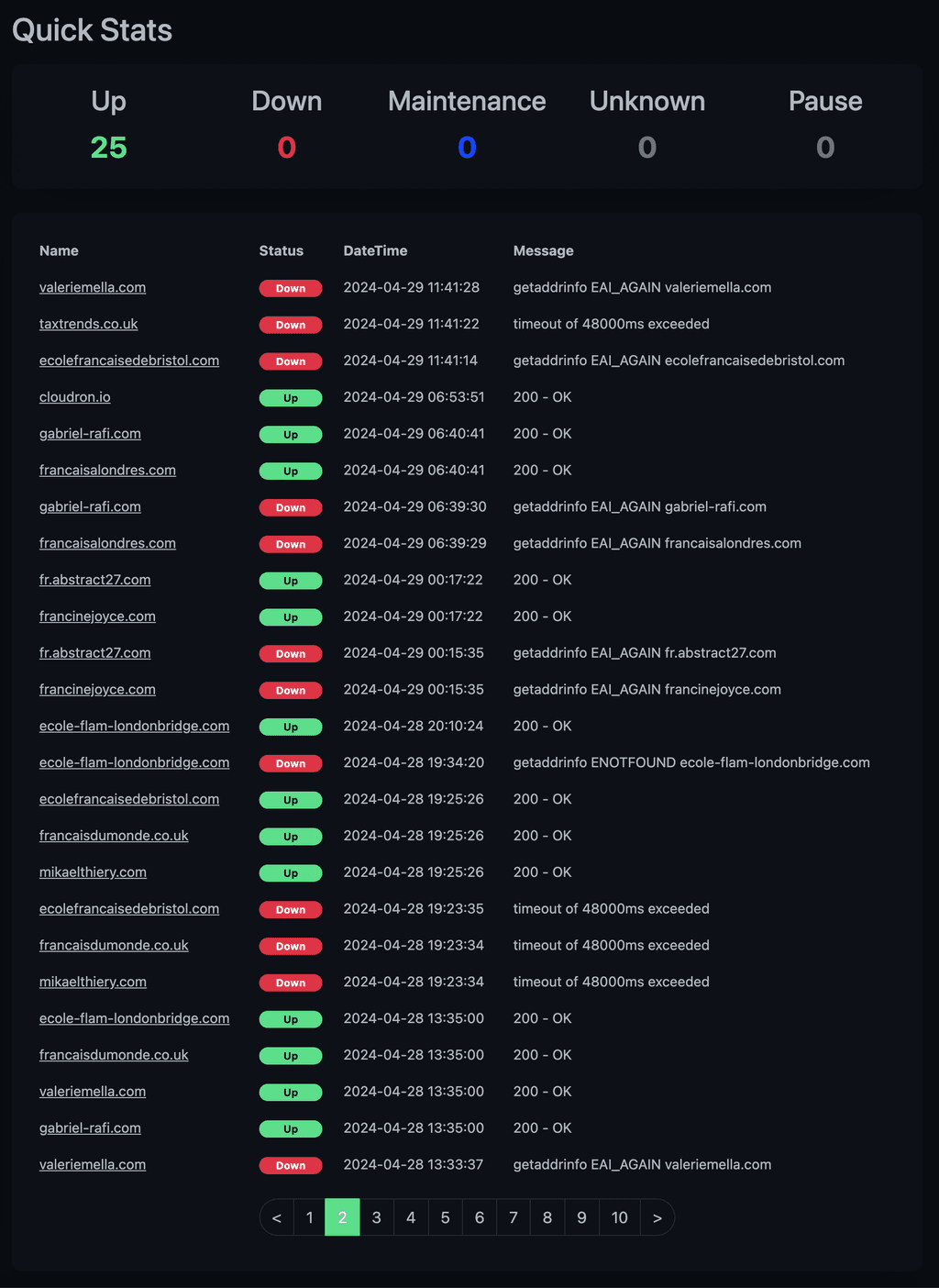
I do have the same kind of shortages with uptime kuma. I did add Cloudron to see. Any idea of what is happening ?
I have a dedicated server with hetzner.
-
@jrl-abstract27 this is to do with the local DNS server (unbound) not resolving . In Cloudron 8 (the next release), we are removing unbound altogether and it will use your network's resolver via systemd-resolved. Maybe this issues gets sorted out with that.
-
thanks @girish
-
@jrl-abstract27 this is to do with the local DNS server (unbound) not resolving . In Cloudron 8 (the next release), we are removing unbound altogether and it will use your network's resolver via systemd-resolved. Maybe this issues gets sorted out with that.
@girish said in Regular short getaddrinfo EAI_AGAIN outages:
@jrl-abstract27 this is to do with the local DNS server (unbound) not resolving . In Cloudron 8 (the next release), we are removing unbound altogether and it will use your network's resolver via systemd-resolved. Maybe this issues gets sorted out with that.
Hi, i just upgraded to Cloudron 8.0.3, rebooted server and i see Unbound still appears in the services pages, is that normal? does that mean uptime kuma still uses it?
-
unboundis still used in Cloudron, but its usage is drastically reduced now. It is used for directly querying the nameservers to check if DNS records are already in-sync to avoid hitting NXDOMAIN for newly installed apps as well as for email DNS record lookup.The rest now uses whatever the default setup, of the environment the server is running in, is.
-
To conclude what @nebulon said, for Uptime Kuma this means that it uses the system DNS (and not unbound).
-
I've used Uptime Kuna without any problem since April. But for the last 24+ hours I suddenly have started to receive tons of these:
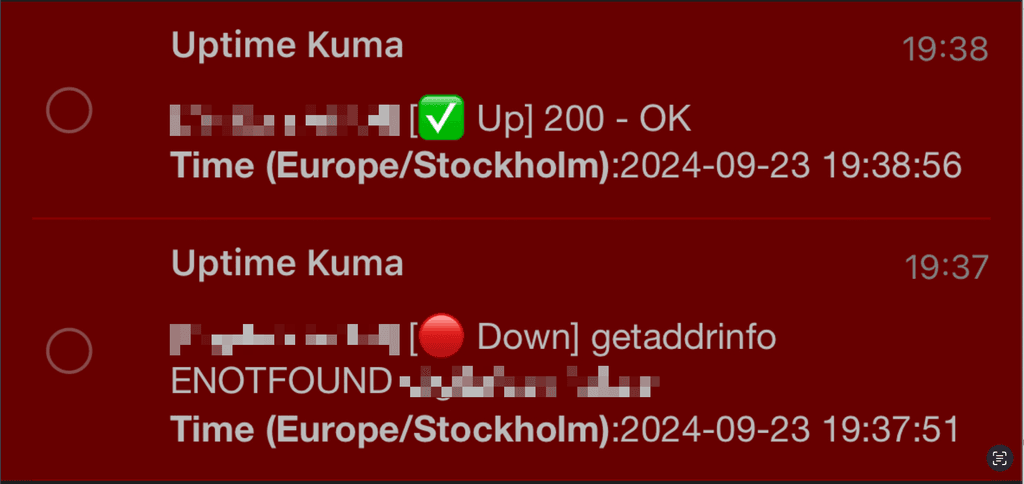
The affected hosts are on .se, and one .social. Some of them are hosted at the same box I run Cloudron on, some on others.
I see that it's not the same error message as in the OP, but similar enough to be related?
According to my logs, my Cloudron was updated to 8.0.4 on August 28, and 8.0.6 yesterday morning. I don't know for sure, but from the graphs it looks like the problem started as soon as that update had been installed. This is what the week graph looks like for or the monitored services with problems:
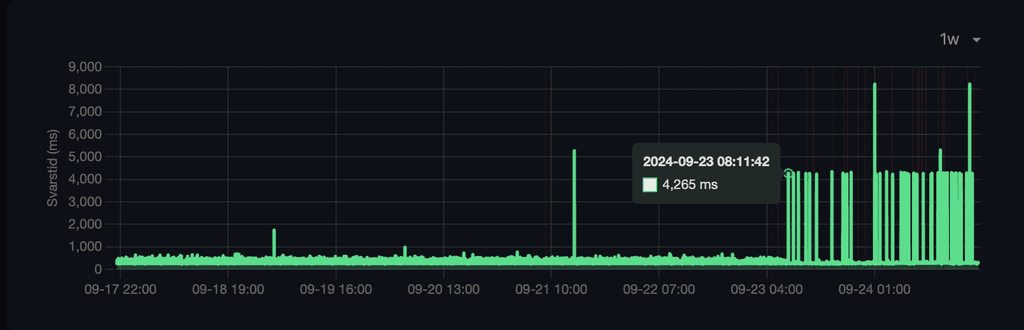
-
@thoresson usually, ENOTFOUND is a problem with the DNS. Is the DNS working on the server? You can try
host www.cloudron.iofrom the host (via ssh) and also viw the Web Terminal of the Uptime Kuma app. Do they work?
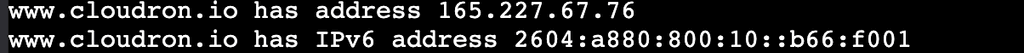
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login