A follow-up, because raising nginx client_max_body_size alone turns out not to be enough — there is a second, hard-coded ceiling that hits right after.
Even with the /api/ location bumped to 10m, a blocklist POST now fails with HTTP 500 and this JSON body:
{"status":"Internal Server Error","message":"request entity too large"}
Note it is a 500, not an nginx 413 — the body passes nginx and is then rejected
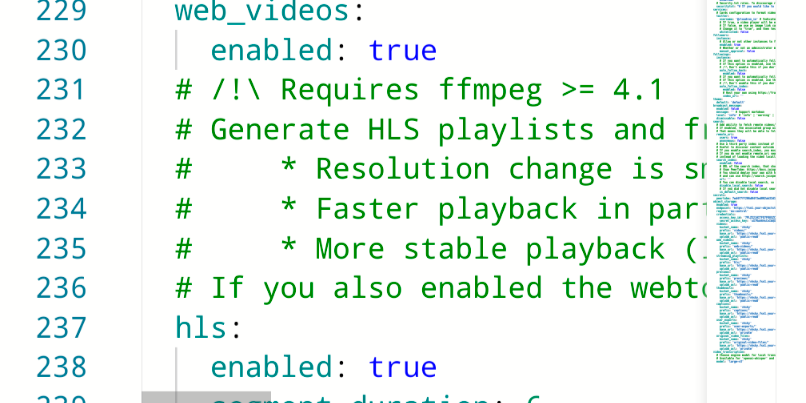
inside box. The cause is the JSON body-parser limit in:
box/src/server.js (9.0.0, ~line 41)
const QUERY_LIMIT = '2mb', // max size for json queries (see also client_max_body_size in nginx)
...
const json = middleware.json({ strict: true, limit: QUERY_LIMIT }, true);
That QUERY_LIMIT applies to every JSON POST route, including
POST /api/v1/network/blocklist. So there are two coupled limits — the nginx one
and this one — and the box default (2mb = 2,097,152 bytes) is the real wall for
large blocklists.
Concrete numbers from a live install: the combined blocklist is ~90,600 entries and
the JSON request body is 2,096,109 bytes — about 1 KB under the 2 MiB limit. One of my
servers already fails as soon as a few hundred new IPs are added, while others with a
slightly shorter list still squeak through. (JSON encoding inflates it further: each
newline becomes \n → \n, ~90 KB on top of the raw list. JSON_UNESCAPED_SLASHES is
already applied.)
Request: please raise both limits, ideally toward the ipset capacity (262,144
entries). At minimum, give the blocklist route a QUERY_LIMIT that matches a raised
client_max_body_size (e.g. 8–10 MB) — otherwise raising the nginx value has no effect
for this endpoint. The in-code comment already acknowledges the two are meant to track
each other.
Happy to provide a sample 90k-entry blocklist for testing if useful.