Scaling / High Availability Cloudron Setup
-
Starting from the data perspective:
- DRBD - https://www.linbit.com/drbd/
Distributed Replicated Storage System
DRBD
 – software is a distributed replicated storage system for the Linux platform. It is implemented as a kernel driver, several userspace management applications, and some shell scripts.
– software is a distributed replicated storage system for the Linux platform. It is implemented as a kernel driver, several userspace management applications, and some shell scripts.DRBD is traditionally used in high availability (HA) computer clusters, but beginning with DRBD version 9, it can also be used to create larger software defined storage pools with a focus on cloud integration.
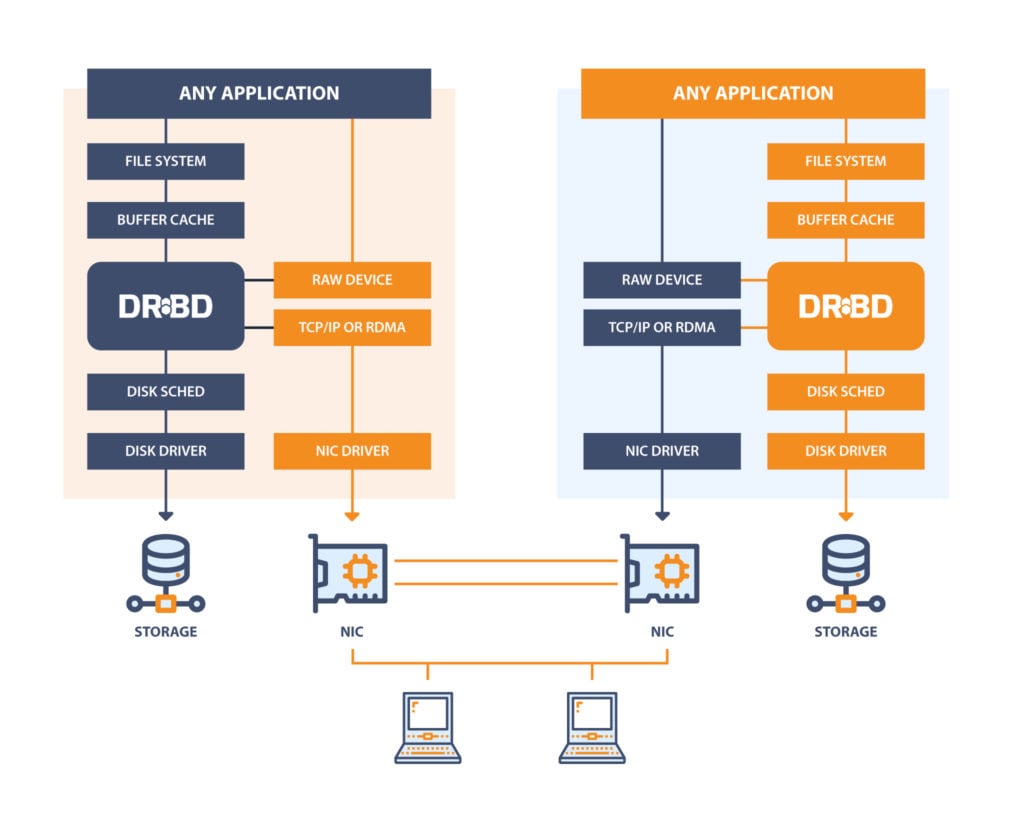
- LinStor - https://github.com/LINBIT/linstor-server
LINSTOR
is open-source software designed to manage block storage devices for large Linux server clusters. It’s used to provide persistent Linux block storage for cloudnative and hypervisor environments.
- OpenEBS - https://openebs.io/
OpenEBS enables Stateful applications to easily access Dynamic Local Persistent Volumes (PVs) or Replicated PVs. By using the Container Attached Storage pattern users report lower costs, easier management, and more control for their teams.
- Yugabyte DB - https://github.com/yugabyte/yugabyte-db
Developers get low latency reads, ACID transactions and globally consistent secondary indexes and full SQL. Develop both scale-out RDBMS and internet-scale OLTP apps with ease.
DBAs & Operations simplify operations with a single database that delivers linear scalability, automatic global data distribution, multi-TB density per node and rebalancing without performance bottlenecks or down time.
CEOs & Line of Business Owners reign in database sprawl and benefit from reduced infrastructure and software licensing costs. Deliver new features and enter new markets with more speed and agility.
Core Features
- Global Resilience
- Geo-replicated
- Strongly consistent across regions
- Extreme resilience to failures
High Performance
- Single-digit millisecond latency
- High throughput
- Written in C/C++
Internet Scale
- Massive write scalability
- App agility with flexible schemas
- Multi-TB data density per node
Cloud Native
- AWS, GCP, Azure, Pivotal
- Docker, Kubernetes
- Private data centers
Open Source
- 100% Apache 2.0 license
- PostgreSQL compatible
- Built-in enterprise features
Integrations
- Spring microservices
- Apache Kafka & KSQL
- Apache Spark
-
I'm not sure I'd want fancy, distributed filesystems on by default for most apps. I feel like most apps would need custom changes to explicitly support distributed storage, and I'm skeptical that a blanket drop-in distributed-fs solution could meet the performance and reliability needs of the diversity of cloudron users.
I'd rather have multi-node app management than distributed app runtime. Manage all your cloudron nodes and assign apps between them, migrate them etc, but most apps can still only be deployed to one cloudron instance at a time. At least I think this would be a better scaling/ha goal for a v1 implementation.
-
I'm not sure I'd want fancy, distributed filesystems on by default for most apps. I feel like most apps would need custom changes to explicitly support distributed storage, and I'm skeptical that a blanket drop-in distributed-fs solution could meet the performance and reliability needs of the diversity of cloudron users.
I'd rather have multi-node app management than distributed app runtime. Manage all your cloudron nodes and assign apps between them, migrate them etc, but most apps can still only be deployed to one cloudron instance at a time. At least I think this would be a better scaling/ha goal for a v1 implementation.
@infogulch said in Scaling / High Availability Cloudron Setup:
I'd rather have multi-node app management than distributed app runtime. Manage all your cloudron nodes and assign apps between them, migrate them etc, but most apps can still only be deployed to one cloudron instance at a time. At least I think this would be a better scaling/ha goal for a v1 implementation.
I totally agree, and I think it's the way the cloudron team is headed for the V1
")
-
I'm not sure I'd want fancy, distributed filesystems on by default for most apps. I feel like most apps would need custom changes to explicitly support distributed storage, and I'm skeptical that a blanket drop-in distributed-fs solution could meet the performance and reliability needs of the diversity of cloudron users.
I'd rather have multi-node app management than distributed app runtime. Manage all your cloudron nodes and assign apps between them, migrate them etc, but most apps can still only be deployed to one cloudron instance at a time. At least I think this would be a better scaling/ha goal for a v1 implementation.
@infogulch Yes, I recall overthinking it that way (i.e trying to scale and distribute etc) but @mehdi corrected my thoughts a while ago about this and mentioned focusing on just managing nodes. I remember writing this somewhere, but I cannot find my notes.
-
Having been down the high-availability setup path with K8S, it isn't a small ask and without compromises. I prefer to think of HA on the server level - so good servers with RAID10 or VPS that does all that for you, couple that with a solid backup and restore setup and you can get as close to HA as those more complex solutions.
I'd rather see focus on the multi-cloud control panel and granular backup policies first.
It's the same as encryption - everyone thinks they want it, until they realise how many people and policies there needs to be for key holders because of the vulnerability for loss moving from the technology to the people.
-
Having been down the high-availability setup path with K8S, it isn't a small ask and without compromises. I prefer to think of HA on the server level - so good servers with RAID10 or VPS that does all that for you, couple that with a solid backup and restore setup and you can get as close to HA as those more complex solutions.
I'd rather see focus on the multi-cloud control panel and granular backup policies first.
It's the same as encryption - everyone thinks they want it, until they realise how many people and policies there needs to be for key holders because of the vulnerability for loss moving from the technology to the people.
@marcusquinn More like common hypervisor HA features instead of full blow K8 HA? Mainly the ability to migrate an app to a different node and further move/manage its backup and DNS
-
k8s is not a great fit imo for cloudron without introducing much bigger changes...there are roads to that runtime with some intermediary schedulers as well though, which is why I like Nomad in this space the most. I've actually been working up a prototype using the HashiStack Consul/Nomad (plus or minus vault) to provide a distributed runtime, but that's a reasonably long way off seeing any sort of integration into the core of things. It's a big shift on its own, and needs a lot of refinement. Obviously so would a k8s approach. In the immediate term, managing across multiple full-on cloudron instances is fairly clean, and if implemented correctly, could actually still be useful in that world as well. It's the first, easiest, smallest thing to do and therefore in my opinion is valuable, regardless of where the higher-powered distributed runtime ideas go.
-
@marcusquinn More like common hypervisor HA features instead of full blow K8 HA? Mainly the ability to migrate an app to a different node and further move/manage its backup and DNS
@plusone-nick I mean as in disk hardware redundancy. Most racks have 2 of everything else. In my experience a simple server setup on a good hardware rack will outperform K8S for uptime. I lost count of the times we were restarting one thing or another with Rancher to get something working that had no reason to fail than K8S getting it's knickers in a twist.
The biggest risk to data loss is always the simple minds of the users!
The biggest risk to availability is always the complex minds of the tools!
No-one really needs high-availability, online banking goes offline frequently for maintenance. If Google has a bad day, people make a beverage and talk to each other.
HA is snake oil in my experience.
Web Design & Development: https://www.evergreen.je
Technology & Apps: https://www.marcusquinn.com -
@plusone-nick I mean as in disk hardware redundancy. Most racks have 2 of everything else. In my experience a simple server setup on a good hardware rack will outperform K8S for uptime. I lost count of the times we were restarting one thing or another with Rancher to get something working that had no reason to fail than K8S getting it's knickers in a twist.
The biggest risk to data loss is always the simple minds of the users!
The biggest risk to availability is always the complex minds of the tools!
No-one really needs high-availability, online banking goes offline frequently for maintenance. If Google has a bad day, people make a beverage and talk to each other.
HA is snake oil in my experience.
-
@plusone-nick I mean as in disk hardware redundancy. Most racks have 2 of everything else. In my experience a simple server setup on a good hardware rack will outperform K8S for uptime. I lost count of the times we were restarting one thing or another with Rancher to get something working that had no reason to fail than K8S getting it's knickers in a twist.
The biggest risk to data loss is always the simple minds of the users!
The biggest risk to availability is always the complex minds of the tools!
No-one really needs high-availability, online banking goes offline frequently for maintenance. If Google has a bad day, people make a beverage and talk to each other.
HA is snake oil in my experience.
@marcusquinn
You can just not have live HA, but like a soft one.
If a container is on a node that is not responding you can start it on a new node.Matteo. R.
Founder and Tech-Support Manager.
MooCloud MSP
Swiss Managed Service Provider -
@marcusquinn
You can just not have live HA, but like a soft one.
If a container is on a node that is not responding you can start it on a new node.@moocloud_matt Thanks, I know what HA is, and how it works, and far too many options for it - it's still the wrong approach for almost all online services.
One thing I've learned in all my years is to always discount, ignore and do the opposite of anyone that says "just" in any comments, because they always represent the vast difference in time and cost between saying and doing.
I'm well aware of the vast industry of people peddling HA pipe-dreams - I'm pretty sure I could beat all of them for uptime, by specifically avoiding doing every single thing they recommend, and just having the tried and tested strategy of keeping it simple.
If you can't take a month off and then another month doing different things without having to do any maintenance or explain anything to anyone, your stack is too complicated.
All HA ever did for me was cost me an additional couple of employees just to continually maintain it, and generally take away resources and attention from the actual things users wanted.
No K8S, no excessive expertise costs, and no uptime problems since because there's just less to go wrong, and less opinion to distract from the actual usage of services that funds them.
Web Design & Development: https://www.evergreen.je
Technology & Apps: https://www.marcusquinn.com -
@moocloud_matt Thanks, I know what HA is, and how it works, and far too many options for it - it's still the wrong approach for almost all online services.
One thing I've learned in all my years is to always discount, ignore and do the opposite of anyone that says "just" in any comments, because they always represent the vast difference in time and cost between saying and doing.
I'm well aware of the vast industry of people peddling HA pipe-dreams - I'm pretty sure I could beat all of them for uptime, by specifically avoiding doing every single thing they recommend, and just having the tried and tested strategy of keeping it simple.
If you can't take a month off and then another month doing different things without having to do any maintenance or explain anything to anyone, your stack is too complicated.
All HA ever did for me was cost me an additional couple of employees just to continually maintain it, and generally take away resources and attention from the actual things users wanted.
No K8S, no excessive expertise costs, and no uptime problems since because there's just less to go wrong, and less opinion to distract from the actual usage of services that funds them.
HA is a bit overpower for most customer that's true, but is the idea that people have of it, that push MSP and CSP to have some lvl of HA.
Good hardware components can be a good solution, but if you have to restore a raid from a backup it will take a lot of time, and some customer don't want to take that risk.
They just prefer to have an soft HA set-up.KISS is always the good way in the IT, but not always it's possible to "keep it simple s*" .
Matteo. R.
Founder and Tech-Support Manager.
MooCloud MSP
Swiss Managed Service Provider -
HA is a bit overpower for most customer that's true, but is the idea that people have of it, that push MSP and CSP to have some lvl of HA.
Good hardware components can be a good solution, but if you have to restore a raid from a backup it will take a lot of time, and some customer don't want to take that risk.
They just prefer to have an soft HA set-up.KISS is always the good way in the IT, but not always it's possible to "keep it simple s*" .
@moocloud_matt In 20 years of hosting web apps, I cannot recall a single instance of hardware failure causing service or data loss. Not one.
There are network interruptions but they usually get solved through mutual interests in that being solved.
I have however see frequent data loss from software issues, and in the absolute vast majority of cases it was human error.
Software High Availability is a contradiction because it is adding the element of human reliance to a system, and my experience was that the software was never finished, always being updated and frequently failing.
Hardware resilience and redundancy is the only method of data security that is almost immune to interference.
In my experience "Customers" have no idea or interest in risk assessment, and they just want things to work - it is "solutions" sales people that try to sell them solutions to risks they didn't know they had to have in the first place for the sake of securing support retainers.
I'm sure you know what you want - but I would never invest in what you suggest purely because you are trying to sell it.
To me the best solution is one that does not need the person selling it, and that is where actually the oldest solutions have stood the test of time and new solutions are creating the problems they want to sell the solutions for because they cannot scare their customers into support retainers if they were given solutions that just worked because they don't need to keep changing.
Web Design & Development: https://www.evergreen.je
Technology & Apps: https://www.marcusquinn.com -
@moocloud_matt In 20 years of hosting web apps, I cannot recall a single instance of hardware failure causing service or data loss. Not one.
There are network interruptions but they usually get solved through mutual interests in that being solved.
I have however see frequent data loss from software issues, and in the absolute vast majority of cases it was human error.
Software High Availability is a contradiction because it is adding the element of human reliance to a system, and my experience was that the software was never finished, always being updated and frequently failing.
Hardware resilience and redundancy is the only method of data security that is almost immune to interference.
In my experience "Customers" have no idea or interest in risk assessment, and they just want things to work - it is "solutions" sales people that try to sell them solutions to risks they didn't know they had to have in the first place for the sake of securing support retainers.
I'm sure you know what you want - but I would never invest in what you suggest purely because you are trying to sell it.
To me the best solution is one that does not need the person selling it, and that is where actually the oldest solutions have stood the test of time and new solutions are creating the problems they want to sell the solutions for because they cannot scare their customers into support retainers if they were given solutions that just worked because they don't need to keep changing.
Obviously, it's true what you say, it's just base on Hardware Defines Stuff.
We use a lot of software define storage SDS, or software defines networking, and with that, we can easily without many efforts push SoftHA to everybody.
Not for the customer, but for us especially.
If we maintain an HDD or just OS patch/update (we use LivePatch from January, so no need reboot now) take time and sometimes customer need to use their app on that time.Some customers just want high SLA, just because the wrong maintenance or failure will make them lose a lot of money, and this is not seen as annual SLA, but maybe monthly, having just 5 min of downtime is really hard to offer without some kind of HA.
It's completely true that good hardware can reduce a lot of inconveniences, and in most cases, it will protect the customer really well. But now that we have SDS and is easy to manage and really robust, we can move to that and countless on hardware.
Obviously, there are 2 ways Hardware and Software and there are pros and cons for both, I just see Cloudron as more oriented on Software than hardware, and to replay the main question of this post, I think that softHA base on SDS can be easily implemented compared to some of the super costly hardware by DELL or HPE and provide scalability other than a soft approach to HA.
But I support your thesis to, good hardware is absolutely a good way to provide good SLA.
Matteo. R.
Founder and Tech-Support Manager.
MooCloud MSP
Swiss Managed Service Provider -
Obviously, it's true what you say, it's just base on Hardware Defines Stuff.
We use a lot of software define storage SDS, or software defines networking, and with that, we can easily without many efforts push SoftHA to everybody.
Not for the customer, but for us especially.
If we maintain an HDD or just OS patch/update (we use LivePatch from January, so no need reboot now) take time and sometimes customer need to use their app on that time.Some customers just want high SLA, just because the wrong maintenance or failure will make them lose a lot of money, and this is not seen as annual SLA, but maybe monthly, having just 5 min of downtime is really hard to offer without some kind of HA.
It's completely true that good hardware can reduce a lot of inconveniences, and in most cases, it will protect the customer really well. But now that we have SDS and is easy to manage and really robust, we can move to that and countless on hardware.
Obviously, there are 2 ways Hardware and Software and there are pros and cons for both, I just see Cloudron as more oriented on Software than hardware, and to replay the main question of this post, I think that softHA base on SDS can be easily implemented compared to some of the super costly hardware by DELL or HPE and provide scalability other than a soft approach to HA.
But I support your thesis to, good hardware is absolutely a good way to provide good SLA.
-
@moocloud_matt Which SDS do you use?
@robi
Mostly Ceph, if is not needed an other stack by the customer.
But I have tested recently the new ScaleOutZFS by truenas scale, and it's really good and easy to manage, but is not a really 100% SDS.Matteo. R.
Founder and Tech-Support Manager.
MooCloud MSP
Swiss Managed Service Provider -
@robi
Mostly Ceph, if is not needed an other stack by the customer.
But I have tested recently the new ScaleOutZFS by truenas scale, and it's really good and easy to manage, but is not a really 100% SDS.@moocloud_matt have you played with Open vStorage? MaxIOPS? ...?
-
@moocloud_matt have you played with Open vStorage? MaxIOPS? ...?
@robi
Not that I remember, but I'm not actually the CTO, so in some cases i just know of the production / future production ready solution that we are testing or using.
I don't keep up with all the project that we test or try.Matteo. R.
Founder and Tech-Support Manager.
MooCloud MSP
Swiss Managed Service Provider -
@robi
Not that I remember, but I'm not actually the CTO, so in some cases i just know of the production / future production ready solution that we are testing or using.
I don't keep up with all the project that we test or try.@moocloud_matt Okie.. if you get to ask him, see what else he's tried.
-
Hey everyone, hope it's ok if I chime in here and ask if anyone has built something in this direction. I'm asking because I got approached to host a static site (basically html, js and a few smaller images) which has trafficspikes where 50k+ users will try to access it for a short period of time and then mostly idles again. How would you go about that, is this doable on Cloudron? I did manage to have 100s of users, but 1000s is a different story

Can the surfer app (being a node server and all) handle that load if there's enough CPU/RAM on the host machine? Or would you rather build a custom nginx app which does nothing but serve compressed static files? Or fire up some smaller VPS, install nginx and use a load balancer to spread the traffic? Any information and suggestion is appreciated
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login