
-
Hi guys,
I recently (Friday night) migrated my server between data centres using the typical backup/restore method in the docs. Everything has been running fine since then, however I just noticed today that about 50% approximately of my WordPress instances don't have the cron running at all.
I was notified of the cron issue upon logging in and finding a warning about missed tasks by WP Rocket, for example, and then in the Tools > Site Health I see a warning there as well (screenshot below). So I dug into the logs of the instance and I see no instances of the cron running at all, not even running and failing, it just doesn't even start a cron at all... as if it doesn't exist or something.
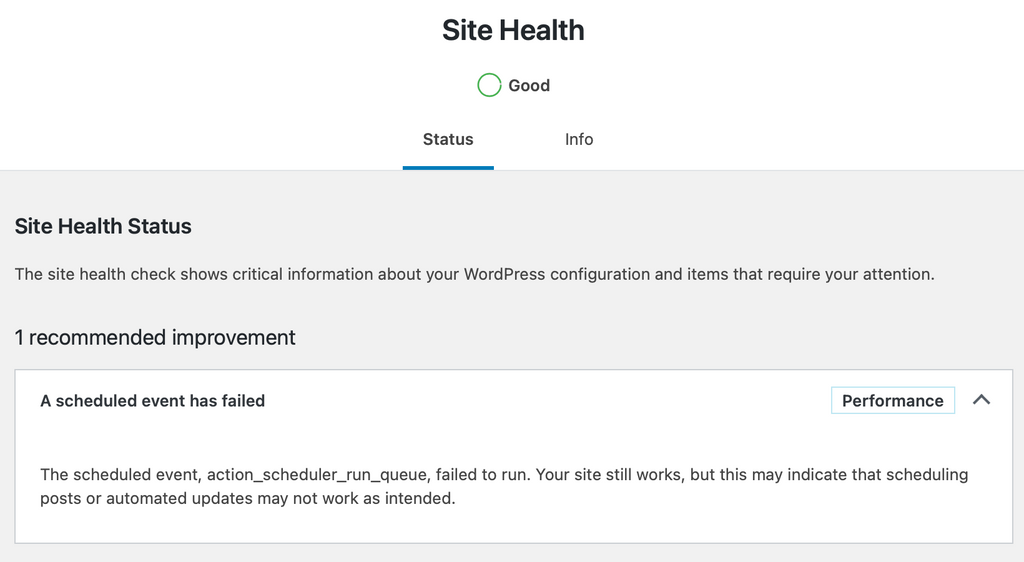
As far as I'm aware, it was running fine on the old server. Not sure if related to the migration but seems coincidental at the very least. In case it does matter though, during the migration I also changed from Ubuntu 18.04 to 20.04 (figured I may as well do it at the same time since I had to spin up a new server anyways), but again I'm not certain this is related at all because about half my sites are still running crons as expected. I can't figure out anything common between the ones that work and the ones that don't. I bring up the migration though in case this is an issue that comes in rare circumstances when restoring from a backup (backup was in OVH Object Storage if that matters at all).
Restarting the apps doesn't seem to fix anything. I can verify that the cron runs fine when manually executed in Terminal for each app. No idea why it's not getting triggered, but would love some help on this please.
When I dug into the logs of sites that seemed to be working fine (i.e. didn't have this cron issue reported in the admin side), I see the cron running as expected and repeated frequently in the logs, such as the one below:
Feb 14 14:02:01 => Run cron job Feb 14 14:02:01 Executed the cron event 'action_scheduler_run_queue' in 0.032s. Feb 14 14:02:01 Executed the cron event 'wp_privacy_delete_old_export_files' in 0.011s. Feb 14 14:02:01 Success: Executed a total of 2 cron events.For what it's worth, when I look in the logs of a non-working one, I still see the following line in there so I know the cron was setup:
Feb 13 00:42:40 box:addons <FQDN> Setting up addon scheduler with options {"wpcron":{"schedule":"*/1 * * * *","command":"/app/pkg/cron.sh"}}The above is what I expect to see every minute in WordPress, but isn't happening at all in half (or maybe most) of my sites. Any ideas?
-
Update: In Matomo, I should also see in the logs something like
=> Run cron jobright? Because I checked a non-WordPress app and don't see that in the logs for my Matomo instance either. So maybe this isn't necessary specific to WordPress then the issue of cron not running at all and is more wide-spread across different types of apps? Or it's a red-herring if the logs for Matomo don't actually ever write=> Run cron job. -
Further update: One of the sites that was having issues... I tried that "Location > Save" trick noted from another post for reinitializing the logrotate config, and sure enough that seemed to do the trick. The crons are running again on that instance. So I will do this for all the apps quickly and hopefully that fixes it for all of them. I'll keep an eye on this.
Any ideas though on why this would happen? Only thing I can imagine is something to do with the restore done on Friday night, almost like it wasn't a perfect restore or something even though there were no failures / issues until this one cron thing was realized today.
-
I can now confirm... going to an App config > Location > Save seems to fix the issue in all apps now. Still curious why this happened.
PS - This topic should probably be moved out of this category and into the Support category. I originally thought it was only for WordPress but seems to have been a few other apps as well.
-
This sounds like the cron job was not setup correctly for some apps during the migration. The reconfiguring would set them up again, a restart does not.
Not sure where to start debugging here, since it looks like this already failed during the migration step. -
Thanks guys! Yeah it's a weird issue for sure and likely very rare, so it's probably not a big deal. If it helps for reproducing it, here's a few notes:
- 27 apps installed at the time of backup/restore
- Backup & Restore used tgz format with OVH Object Storage in BHS region
- Backup from a LunaNode m.8 model in Toronto region
- Restored onto OVH b2-7 model (though since upgraded to b2-15) in BHS3 region
- LunaNode instance (source) was running Ubuntu 18.04 at backup time, and OVH instance (target) was running Ubuntu 20.04 at the time of restore.
- When I restored, I very nearly ran out of disk space on the included disk, leaving only ~ 1.5 GB of space remaining.
- When restoring initially, it failed to restore because of the issue I reported earlier, though doubtful this is a root cause. Immediately moved the boxdata to external disk afterwards though, so plenty of space free soon after the restore was done once I moved boxdata off (20 GB in emails alone so it takes up a lot of space).
Hopefully those notes above help in some small way. No worries though if you can't reproduce it, I imagine it's a very rare scenario and could have even been completely unique to me somehow. Hopefully others can chime in though if they experienced anything similar where cron wouldn't run at all (whether a restore involved or not, as I'm still not 100% certain it had to do with the restore though I presume it did).
-
@girish I think I'm running into the same issue here. Now on
9.0.15and a few days ago my turn monitor stopped working. I hadn't had time to check why that was but I also noticed another application doesn't process cron based jobs anymore.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login