Improve Clone/Backup/Restore Speed
-
Incremental backups. I thought we had those already, but if we don't - we should vote to support them.
@Lonk said in Improve Clone/Backup/Restore Speed:
Incremental backups. I thought we had those already, but if we don't - we should vote to support them.
We do have them with the rsync option.
-
Actually, rsync and rclone-ing the incremental backups - encrypted - to Onedrive has been very reliable for me the last years. rclone is such a fantastic tool.
-
@Lonk said in Improve Clone/Backup/Restore Speed:
Incremental backups. I thought we had those already, but if we don't - we should vote to support them.
We do have them with the rsync option.
@jdaviescoates I'm using
.tgzwith Backblaze right now since tgz was the default I didn't look into it. Should I switch to rsync for the benefit of incremental changes or are there cons like @robi is trying to solve (his cloning / restoring speed suggestions).Is "Incremental TAR files" the best of both worlds, basically?
-
@jdaviescoates I'm using
.tgzwith Backblaze right now since tgz was the default I didn't look into it. Should I switch to rsync for the benefit of incremental changes or are there cons like @robi is trying to solve (his cloning / restoring speed suggestions).Is "Incremental TAR files" the best of both worlds, basically?
@Lonk If you use rsync, use Wasabi as it has no ingress costs. Also, in Backblaze, check the lifecycle settings on all buckets to make sure you're not paying to insure infinite versions of versions, just change the setting for each in there to just store the latest.
Web Design & Development: https://www.evergreen.je
Technology & Apps: https://www.marcusquinn.com -
@Lonk If you use rsync, use Wasabi as it has no ingress costs. Also, in Backblaze, check the lifecycle settings on all buckets to make sure you're not paying to insure infinite versions of versions, just change the setting for each in there to just store the latest.
@marcusquinn said in Improve Clone/Backup/Restore Speed:
@Lonk If you use rsync, use Wasabi as it has no ingress costs. Also, in Backblaze, check the lifecycle settings on all buckets to make sure you're not paying to insure infinite versions of versions, just change the setting for each in there to just store the latest.
I did have infinite versions on, thanks for saving me there, I owe ya!
-
@marcusquinn said in Improve Clone/Backup/Restore Speed:
@Lonk If you use rsync, use Wasabi as it has no ingress costs. Also, in Backblaze, check the lifecycle settings on all buckets to make sure you're not paying to insure infinite versions of versions, just change the setting for each in there to just store the latest.
I did have infinite versions on, thanks for saving me there, I owe ya!
@Lonk Everyone does as the sneaky f***ers make it the default. Must have lost thousands of dollars before I found that where everyone else missed it.
Web Design & Development: https://www.evergreen.je
Technology & Apps: https://www.marcusquinn.com -
@Lonk Everyone does as the sneaky f***ers make it the default. Must have lost thousands of dollars before I found that where everyone else missed it.
Wasabi don't make it the default though, and have a much better interface. I'm dropping Backblaze from my recommendations for S3 needs and only use if for personal machine backups which don't have all those extra costs.
-
@girish are you aware of the incremental feature of tar ?
This feature is provided by
tarvia an argument-listed-incremental=snapshot-filewhere a "snapshot-file" is a special file maintained by thetarcommand to determine the files that are been added,modified or deleted.That will speed things up.
@robi said in Improve Clone/Backup/Restore Speed:
This feature is provided by tar via an argument -listed-incremental=snapshot-file where a "snapshot-file" is a special file maintained by the tar command to determine the files that are been added,modified or deleted.
-
Recently, I accidentally found myself studying this problem. I've relocated backups to GCS recently from DigitalOcean Spaces for one machine...suffice it to say I found the bottleneck in that process. Previously, it appeared to be some traffic management into spaces, and/or the fact that it was heading to the SFO2 region from NYC3 (you know...because...geography). After turning on backups into GCS in the awesome
usmulti-region automatic replication (nearline), it became very obvious that the main limiting factor was a 10MB/s cap on the disk speed at DO.Seriously; here's their graph over the last 7 days for Disk I/O performance (it's pretty obvious where the backups are):
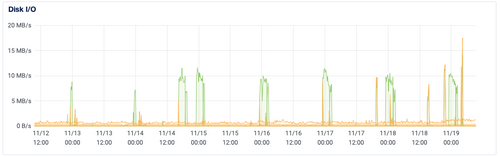
The main reason this even showed up is that GCS ingest is way faster from a bandwidth perspective:
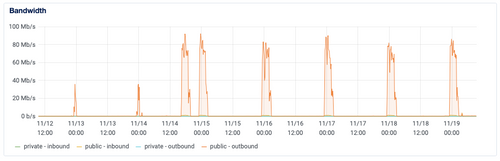
Too bad I don't have the old Spaces graph to show as well, but suffice it to say, it wasn't great. So the GCS switchover actually moved the first bottleneck, getting at the main root of the issue.
I'll update on how things go one the server in question gets itself moved into a GCP instance - by my rough math, there should be a noticeable performance bump in at least backups, but likely systemwide once it transitions into the GCP volumes, which are rated at least 50% faster in the case of the small volumes, and in the big one (apps data), should have a network performance ceiling that is roughly 6x higher than the existing DO volumes. I know this is more on the production/operator side than the personal side of usage, and the problem of "throw more, bigger resources at it" is not one most folks can/would take on a NAS/local server and home internet connection, but it's some interesting data and an intriguing problem in any case.
-
Recently, I accidentally found myself studying this problem. I've relocated backups to GCS recently from DigitalOcean Spaces for one machine...suffice it to say I found the bottleneck in that process. Previously, it appeared to be some traffic management into spaces, and/or the fact that it was heading to the SFO2 region from NYC3 (you know...because...geography). After turning on backups into GCS in the awesome
usmulti-region automatic replication (nearline), it became very obvious that the main limiting factor was a 10MB/s cap on the disk speed at DO.Seriously; here's their graph over the last 7 days for Disk I/O performance (it's pretty obvious where the backups are):
The main reason this even showed up is that GCS ingest is way faster from a bandwidth perspective:
Too bad I don't have the old Spaces graph to show as well, but suffice it to say, it wasn't great. So the GCS switchover actually moved the first bottleneck, getting at the main root of the issue.
I'll update on how things go one the server in question gets itself moved into a GCP instance - by my rough math, there should be a noticeable performance bump in at least backups, but likely systemwide once it transitions into the GCP volumes, which are rated at least 50% faster in the case of the small volumes, and in the big one (apps data), should have a network performance ceiling that is roughly 6x higher than the existing DO volumes. I know this is more on the production/operator side than the personal side of usage, and the problem of "throw more, bigger resources at it" is not one most folks can/would take on a NAS/local server and home internet connection, but it's some interesting data and an intriguing problem in any case.
@jimcavoli To add to the disk I/O, for the tar.gz backups I have noticed that gzip performance is quite poor on many of the cloud providers (because of the CPU). Initially, I thought this was just node being very slow (thought that seemed a bit unlikely because it is using zlib underneath like everyone else) but I remember comparing with tar and the performance was quite comparable - https://git.cloudron.io/cloudron/box/-/issues/691#note_10936 . That led me down the path of trying to see if there was a parallel zip implementation that uses multiple cores or some special cpu instructions. I found http://www.zlib.net/pigz/ but haven't really found time to test it.
-
@jimcavoli To add to the disk I/O, for the tar.gz backups I have noticed that gzip performance is quite poor on many of the cloud providers (because of the CPU). Initially, I thought this was just node being very slow (thought that seemed a bit unlikely because it is using zlib underneath like everyone else) but I remember comparing with tar and the performance was quite comparable - https://git.cloudron.io/cloudron/box/-/issues/691#note_10936 . That led me down the path of trying to see if there was a parallel zip implementation that uses multiple cores or some special cpu instructions. I found http://www.zlib.net/pigz/ but haven't really found time to test it.
@girish Interesting, and not something I'd considered. That
pigsoption is similarly interesting, though seems to have gone silent since 2017. Curiously, it's a similar story withpbzip2(the same idea forbzip2) as far as I can tell. Decent roundup of options for Ubuntu at https://askubuntu.com/questions/258202/multi-core-compression-tools in case you want to review. It will be interesting to see the GCP results for sure. I'll pull some metrics after the migration/restore as well as after the manual backup and see how it does across CPU/Disk/Network in the process. -
Just to follow up, here's a sample of normal backups followed by a Cloudron upgrade, which itself triggered another backup run, and the corresponding relevant network and disk graphs:
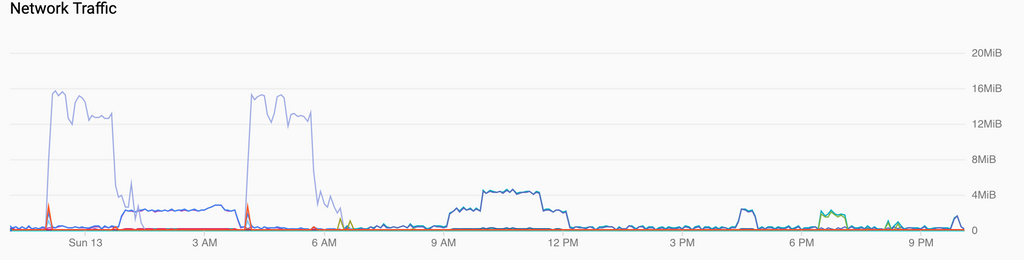
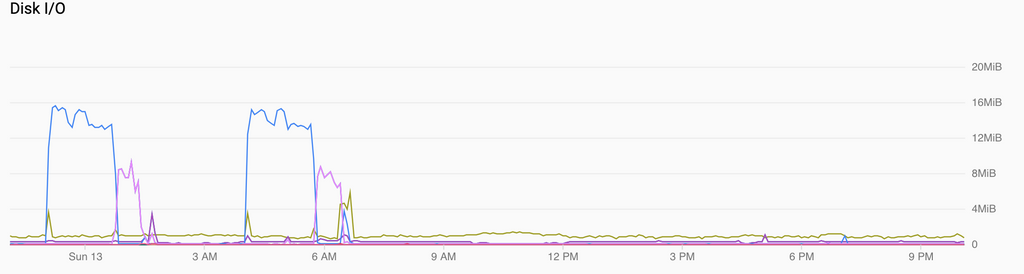
All in all, it's definitely fast-er but not insanely performant. CPU utilization vs load hints that it may in fact be down to inefficient utilization of cores to some extent, but there is definitely a fair bit more bottleneck coming from the network still.
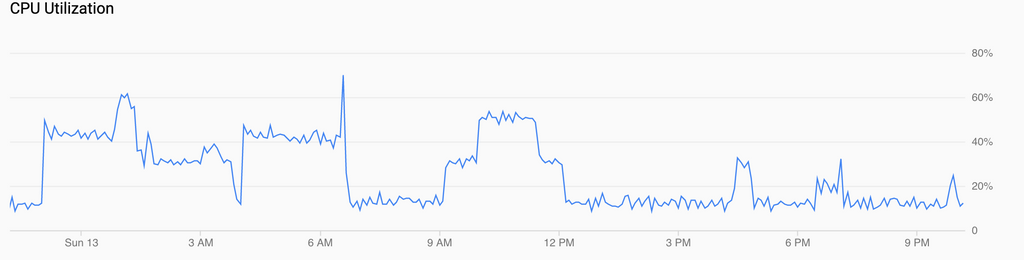
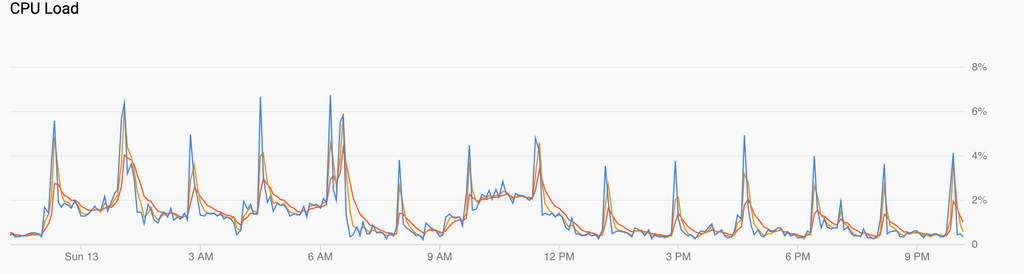
Nothing earth-shattering either way, and gains were more mild than I would have guessed, but all in all, not a bad outcome.
