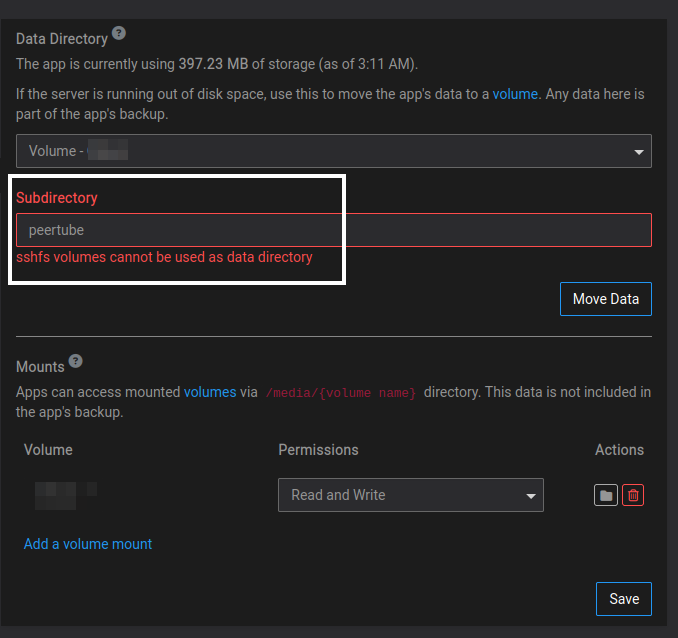
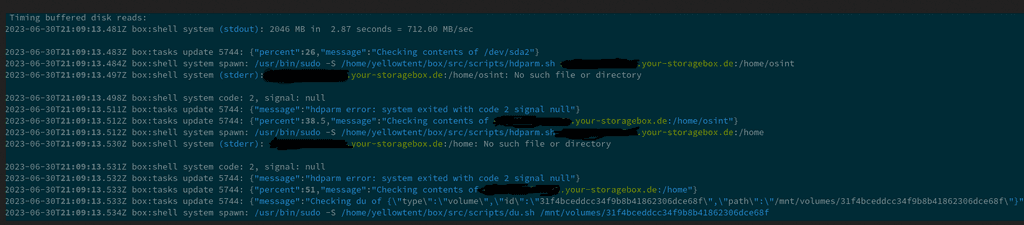
OK I have found the culprit, apparently when I added the SSHFS mount I set the home to be /
[Unit]
Description=XXXXXX
Requires=network-online.target
After=network-online.target
Before=docker.service
[Mount]
What=xxxxx@xxxxxxx.your-storagebox.de:/ <----- Problem
Where=/mnt/volumes/1cb3536743394406a8db5a6666226f33
Options=allow_other,port=23,IdentityFile=/home/yellowtent/platformdata/sshfs/id_rsa_XXXXXX.your-storagebox.de,StrictHostKeyChecking=no,reconnect
Type=fuse.sshfs
[Install]
WantedBy=multi-user.target
so I went to /etc/systemd/system/
found my mnt-volumes-CLOUDRON_ID
and compared with a previous working mount
and the only thing I found was the home
[Unit]
Description=XXXXXX
Requires=network-online.target
After=network-online.target
Before=docker.service
[Mount]
What=xxxxx@xxxxxxx.your-storagebox.de:/home
Where=/mnt/volumes/1cb3536743394406a8db5a6666226f33
Options=allow_other,port=23,IdentityFile=/home/yellowtent/platformdata/sshfs/id_rsa_XXXXXX.your-storagebox.de,StrictHostKeyChecking=no,reconnect
Type=fuse.sshfs
[Install]
WantedBy=multi-user.target
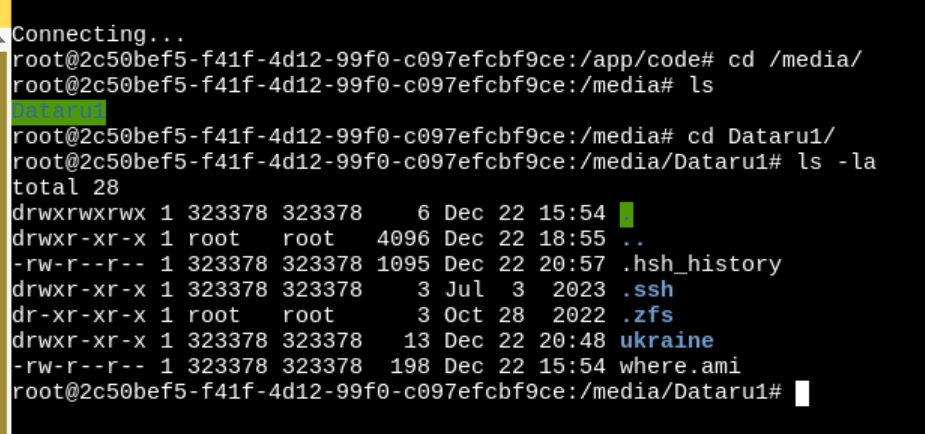
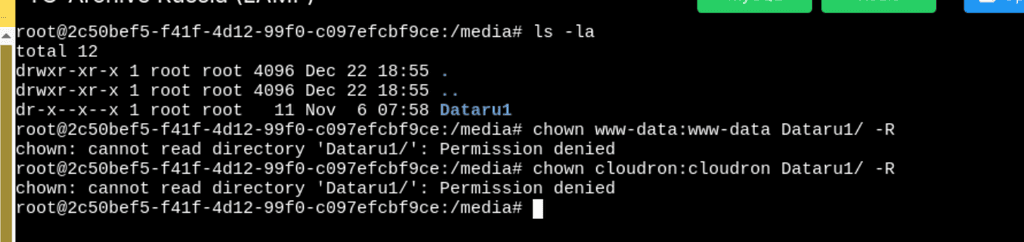
Now my mounts are working like before !

")