Emailing notifications of certain crucial system events, such as full disk space
-
Hi Cloudron Community,
unfortunately I had to deal with a full disk space and its consequences.
I was quite stunned that the disk usage was running full so quickly. Without prior notice services stopped and the dashboard was unreachable. After resizing the disk and the partitions I was able to start the server again. Anyways the unbound DNS server wasn't running properly, even though it did after resizing the disk, which caused mainly the mailserver to stop working.
The reason I believe the disk space was running full in the first place:
The mounted CIFS backup volume wasn't mounted anymore → backups were made locally. Why did that happen? No idea. But it would have been good to know that it happened.These events just showed me that I would miss the possibility to setup email notifications for certain system events, which require immediate action, such as
- Backup volume not found/unmounted;
- Disk usage exceeds a threshold;
- Service X not running since X minutes → indicates a problem;
- … you name it.
And since I read quite often that people’s disk space was running full "suddenly" I thought this might be caused by a lack of information.
-
Hi Cloudron Community,
unfortunately I had to deal with a full disk space and its consequences.
I was quite stunned that the disk usage was running full so quickly. Without prior notice services stopped and the dashboard was unreachable. After resizing the disk and the partitions I was able to start the server again. Anyways the unbound DNS server wasn't running properly, even though it did after resizing the disk, which caused mainly the mailserver to stop working.
The reason I believe the disk space was running full in the first place:
The mounted CIFS backup volume wasn't mounted anymore → backups were made locally. Why did that happen? No idea. But it would have been good to know that it happened.These events just showed me that I would miss the possibility to setup email notifications for certain system events, which require immediate action, such as
- Backup volume not found/unmounted;
- Disk usage exceeds a threshold;
- Service X not running since X minutes → indicates a problem;
- … you name it.
And since I read quite often that people’s disk space was running full "suddenly" I thought this might be caused by a lack of information.
@dev-cb I've suggested in another thread that a pop-up message on the Cloudron Dashboard might be an even better reminder/notification about a given Cloudron using local storage. Even disks with close to 1TB fill up quickly if you use local storage and a healthy backup frequency! I don't think Cloudron should be responsible for our disk usage/monitoring, but it could certainly alert us to some conditions that might lead to a full disk.
A life lived in fear is a life half-lived
-
@dev-cb I've suggested in another thread that a pop-up message on the Cloudron Dashboard might be an even better reminder/notification about a given Cloudron using local storage. Even disks with close to 1TB fill up quickly if you use local storage and a healthy backup frequency! I don't think Cloudron should be responsible for our disk usage/monitoring, but it could certainly alert us to some conditions that might lead to a full disk.
@scooke said in Emailing notifications of certain crucial system events, such as full disk space:
I don't think Cloudron should be responsible for our disk usage/monitoring
I agree with you in general. It is the users responsibility to take action anyways – not Cloudron’s. But since one promise which is communicated on the website is the following, I think slightly different in detail:
Cloudron lets you focus on using the apps and not worry about system administration.
The users asking for help after having a full disk certainly had to deal with system administration – very suddenly and on a level which needs quite some knowledge (partitioning a disk).
A notification on the dashboard might give a good indication but also requires the user to constantly working with the dashboard which is not always the case. Imagine there are just running a few apps, for example to enable groupware for a small business.
Since Cloudron provides a built-in mail service it should be possible to implement the delivery of notifications or warnings to prevent a system failure.
I can just speak based on the experience I had, which wasn’t pleasant at all. The failure forced my business to stop running for a couple of hours which had cost quite something in time, effort and money. Could have been prevented.
What’s the opinion of others here? How often is the support been contacted with an issue such as full disk space and its consequences?
-
Hi Cloudron Community,
unfortunately I had to deal with a full disk space and its consequences.
I was quite stunned that the disk usage was running full so quickly. Without prior notice services stopped and the dashboard was unreachable. After resizing the disk and the partitions I was able to start the server again. Anyways the unbound DNS server wasn't running properly, even though it did after resizing the disk, which caused mainly the mailserver to stop working.
The reason I believe the disk space was running full in the first place:
The mounted CIFS backup volume wasn't mounted anymore → backups were made locally. Why did that happen? No idea. But it would have been good to know that it happened.These events just showed me that I would miss the possibility to setup email notifications for certain system events, which require immediate action, such as
- Backup volume not found/unmounted;
- Disk usage exceeds a threshold;
- Service X not running since X minutes → indicates a problem;
- … you name it.
And since I read quite often that people’s disk space was running full "suddenly" I thought this might be caused by a lack of information.
@dev-cb said in Emailing notifications of certain crucial system events, such as full disk space:
Backup volume not found/unmounted;
Disk usage exceeds a threshold;
Service X not running since X minutes → indicates a problem;
… you name it.I agree with parts of your statement.
Yes an email notification about running out of space would be nice.
Why did the system do a local backup instead of notifying about the missing mount, or even better just try to remount the storage and then do the backup?
(I believe I talked with @nebulon about this and this should be fixed with the new update? big emphasis on believe since I am not sure if we really talked or my mind is playing games with me )
)But now we come into a territory where Clouron it self would have to implement a full monitoring solution it self.
"Don't re-invent the wheel"I use Zabbix for all my systems.
No there is no Zabbix app for Cloudron yet.With Zabbix I can monitor everything.
Disk Usage, docker status Cloudron API and more.
You want to see some data for a system? Sure here:
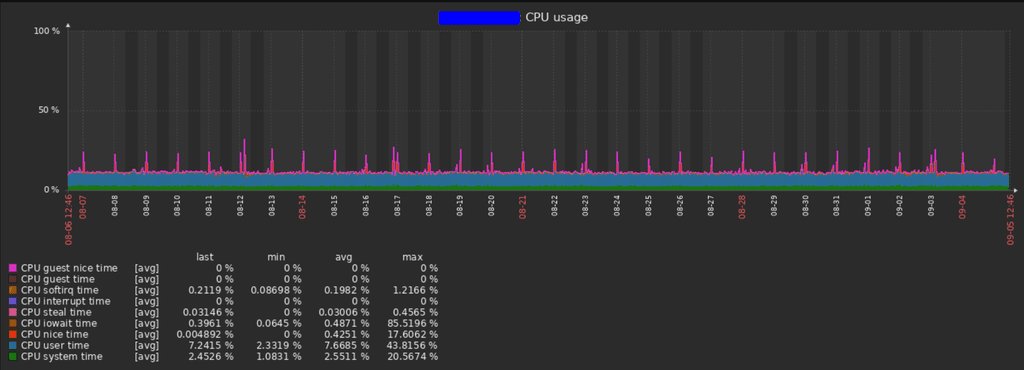
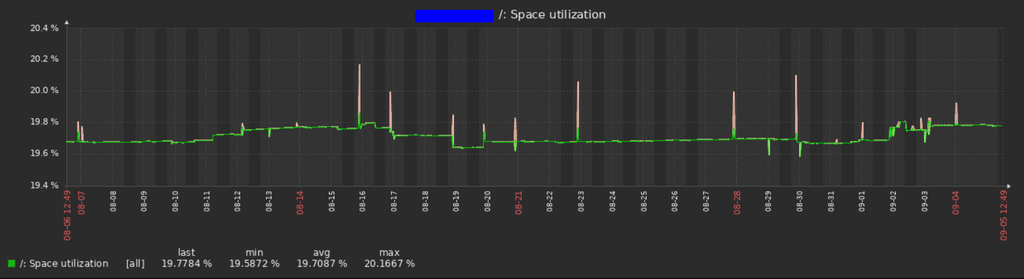
I monitor each container, I have all statistics space, ram, cpu for each container.
DATA!!!Also I can setup notification flows and states about how critical an error is and when to start notifying people.
Usage: 75% Warning 80% Average 85% High 90% Critical 95% Disaster.
And can define groups where to send messages at each level and with what media.
Warning only via Rocket Chat and E-Mail, High>Critical Mobile Push Telegram Bot / SMS / Alarm.yada yada yada.
I am unsure if it would be good to re-invent the wheel here.
To a certain degree OK but we should be careful.I think this will end up in an initial feature which is going to grow because people will want more functionality for the internal monitoring.
. . .
Hope you can understand why I am concerned about this becoming a feature since the overhead could become rather large.
-
@dev-cb said in Emailing notifications of certain crucial system events, such as full disk space:
Backup volume not found/unmounted;
Disk usage exceeds a threshold;
Service X not running since X minutes → indicates a problem;
… you name it.I agree with parts of your statement.
Yes an email notification about running out of space would be nice.
Why did the system do a local backup instead of notifying about the missing mount, or even better just try to remount the storage and then do the backup?
(I believe I talked with @nebulon about this and this should be fixed with the new update? big emphasis on believe since I am not sure if we really talked or my mind is playing games with me )But now we come into a territory where Clouron it self would have to implement a full monitoring solution it self.
"Don't re-invent the wheel"I use Zabbix for all my systems.
No there is no Zabbix app for Cloudron yet.With Zabbix I can monitor everything.
Disk Usage, docker status Cloudron API and more.
You want to see some data for a system? Sure here:
I monitor each container, I have all statistics space, ram, cpu for each container.
DATA!!!Also I can setup notification flows and states about how critical an error is and when to start notifying people.
Usage: 75% Warning 80% Average 85% High 90% Critical 95% Disaster.
And can define groups where to send messages at each level and with what media.
Warning only via Rocket Chat and E-Mail, High>Critical Mobile Push Telegram Bot / SMS / Alarm.yada yada yada.
I am unsure if it would be good to re-invent the wheel here.
To a certain degree OK but we should be careful.I think this will end up in an initial feature which is going to grow because people will want more functionality for the internal monitoring.
. . .
Hope you can understand why I am concerned about this becoming a feature since the overhead could become rather large.
-
@BrutalBirdie Can you just describe how your Zabbix system is running, I'm guessing outside of the cloudron vps right ?
@benborges
Zabbix is running on a Master Node and each Client has an Agent. (Yes the master is an external System)
Zabbix can monitor clients active and passive.
Passive means the Master asks the system for data and the system delivers.This does not always work within special networks where the master can not reach the client.
Then you use active monitoring then the client reports all data in a certain interval to the master.There can be a master / slave / proxy setup for big scale monitoring solutions. (Google Zabbix HA Cluster Setup for more details)
For more in detail please consult the doc: https://www.zabbix.com/documentation/current/en/manual/introduction/about
-
I also encountered "disk full" issue, and I was quite dumbfounded there was no email notification for this, that seems pretty basic as far as monitoring goes.
Cloudron is well-placed to add this functionality, and it would save us so much headaches.
-
I also encountered "disk full" issue, and I was quite dumbfounded there was no email notification for this, that seems pretty basic as far as monitoring goes.
Cloudron is well-placed to add this functionality, and it would save us so much headaches.
@AmbroiseUnly for some reason, linux doesn't have an event when nearing full disk space. The only way to do this then is to keep polling aggressively but this causes a lot of disk churn. Also, the notification is then limited to how frequently you can poll. There is some
quotasupport but it needs also kernel support (which Cloudron cannot control). -
Would it be possible to have a guide then? Something with best-practices in mind.
Another user mentioned Zabbix, but it feels complicated to use (the doc isn't so friendly, it doesn't look simple). I don't know if that really is complex to set up, but a guide with some sort of "Cloudron recommendation" would be really nice.
Typically, something that covers how to get alerted (email) when disk reaches 50/75/90/95/99/100% capacity, and maybe also some CPU watchers. A guide covering it from "how to install it" to "how to configure it" would be really helpful.
Also, if it uses a Cloudron App, it might also be beneficial for Cloudron, because customers would reach 3 Cloudron apps quicker, meaning more sales for you.
-
You could do something like this via cron and maybe ntfy.
We had a discussion like this already, see an example here: https://forum.cloudron.io/post/72148Otherwise, googling
cron alert disk full mailbrought up e.g.
https://askubuntu.com/questions/1503361/script-to-notify-via-email-when-low-on-disk-space or https://github.com/corneliusroot/QuickStatus -
For anyone interested in configuring proper monitoring on your Cloudron server, I wrote a guide about it, and I hope you'll find it useful!
")
It's the kind of guide I wish I would have found when first looking at this topic.
-
I am wondering if this might be possible by now. I just got the notification "Server is running out of disk space" on the Cloudron notification tab. Since there is already the possibility to subscribe to email alerts for events like "App is down", couldn't this event be added as well?
I like the idea of Cloudron being a self-contained system, so I don't want to add a custom monitoring system to it that needs to be maintained along side it. -
@AmbroiseUnly for some reason, linux doesn't have an event when nearing full disk space. The only way to do this then is to keep polling aggressively but this causes a lot of disk churn. Also, the notification is then limited to how frequently you can poll. There is some
quotasupport but it needs also kernel support (which Cloudron cannot control).@girish How about a more indirect solution?
Something that correlates to disk space, such as inodes or other low cost checks.
If not that, then how about creating a safety system for Cloudron, let's call it AirBag with ABS brakes for when you're about to crash it deploys in a controlled way.
AirBag with ABS might look like a series of 10 eager zeroed files evenly dividing a threshold of say 1GB always present on disk. When the system runs out of disk, 1 of 10 is deleted and a notification is sent. Repeat 4 more times, then wait.
That way the system has a controlled descent to 0 and some left for when an admin comes by and needs some space to work with.
Thoughts?
-
@girish How about a more indirect solution?
Something that correlates to disk space, such as inodes or other low cost checks.
If not that, then how about creating a safety system for Cloudron, let's call it AirBag with ABS brakes for when you're about to crash it deploys in a controlled way.
AirBag with ABS might look like a series of 10 eager zeroed files evenly dividing a threshold of say 1GB always present on disk. When the system runs out of disk, 1 of 10 is deleted and a notification is sent. Repeat 4 more times, then wait.
That way the system has a controlled descent to 0 and some left for when an admin comes by and needs some space to work with.
Thoughts?
-
Email notification can be added but it will be unreliable (and don't want to mislead users). See https://forum.cloudron.io/topic/7555/emailing-notifications-of-certain-crucial-system-events-such-as-full-disk-space/8
@joseph said in Emailing notifications of certain crucial system events, such as full disk space:
Email notification can be added but it will be unreliable (and don't want to mislead users). See https://forum.cloudron.io/topic/7555/emailing-notifications-of-certain-crucial-system-events-such-as-full-disk-space/8
Sure, I do understand those limitations. I was just thinking that it would be nice to have an email notification equivalent (maybe with a note pointing out the limitations) for every notification type shown in the Cloudron dashboard.
-
Currently, we run
dfevery 30 mins. Maybe this is accurate enough already. In which case, what is missing is the email notification . Can add that for next release.@girish That sounds great! The last two incidents were this would have helped me were developing over several days (exploding Rocket.Chat logs and syslog.js), so this should be within the necessary precision to prevent this type of situation.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login