So the only version 9 of cloudron i can upgrade to is a prerelease version.
This is a prod system, so id rather not.
So the only version 9 of cloudron i can upgrade to is a prerelease version.
This is a prod system, so id rather not.
oK, Im not sure if I just fat fingered something or if this was fixed, but the yaml is now set up to be working.
Here is my .yaml file
name: Sync Repo with Cloudron LAMP app
on:
workflow_dispatch:
push:
branches: [main]
jobs:
deploy-to-cloudron-app:
runs-on: ubuntu-latest
environment: [WHATEVER YOUR ENVIRONMENT NAME WAS IN SETTINGS OF REPO]
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Diagnostic – Print environment context
run: |
echo "=== GITHUB CONTEXT ==="
echo "Branch: $GITHUB_REF"
echo "Workflow: $GITHUB_WORKFLOW"
echo "Runner: $RUNNER_NAME"
echo "Workspace: $GITHUB_WORKSPACE"
echo "======================"
- name: Diagnostic – Check secret presence
shell: bash
run: |
declare -A secrets
secrets["CLOUDRON_FQDN"]="${{ secrets.CLOUDRON_FQDN }}"
secrets["CLOUDRON_TOKEN"]="${{ secrets.CLOUDRON_TOKEN }}"
secrets["CLOUDRON_APP_ID"]="${{ secrets.CLOUDRON_APP_ID }}"
echo "Checking secrets..."
for key in "${!secrets[@]}"; do
if [ -z "${secrets[$key]}" ]; then
echo "❌ $key is EMPTY"
else
echo "✅ $key is set"
fi
done
- name: Cloudron Push to App
uses: cloudron-io/cloudron-push-to-app@latest
with:
CLOUDRON_FQDN: "${{ secrets.CLOUDRON_FQDN }}"
CLOUDRON_TOKEN: "${{ secrets.CLOUDRON_TOKEN }}"
CLOUDRON_APP_ID: "${{ secrets.CLOUDRON_APP_ID }}"
CLOUDRON_PUSH_DESTINATION: "/app/data"
CLOUDRON_CREATE_APP_BACKUP: "false"
So my git repo has
/public
/apache
/logs
when I ran the yaml with the push to being /app/data, the action would fail.
I updated the yaml to push to /app/data/public
I then had a project file like this
/public/public
/public/apache
/public/logs
/public
/apache
/logs
I need this changed to be /add/data as /app/data/public, can you update that?
Ok, so I just found out the issue, its the /app/data/public push
It has to be /app/data/public, otherwise it will fail.
This also just screwed my app up as I was testing randomly and now i have nested project files.
So, im feeling pretty dumb.
I have updated the .yaml file and I have ensured the right values are in my secrets environment. I even ran this through chatgpt to make sure nothing is missing or wrong. And the action is still failing for me.
The issue is when it actually tries to push to my cloudron app
Here is my current yaml
name: Cloudron Diagnostic Deploy
on:
workflow_dispatch:
push:
branches: [main]
jobs:
deploy-to-cloudron-app:
runs-on: ubuntu-latest
environment: environment
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Diagnostic – Print environment context
run: |
echo "=== GITHUB CONTEXT ==="
echo "Branch: $GITHUB_REF"
echo "Workflow: $GITHUB_WORKFLOW"
echo "Runner: $RUNNER_NAME"
echo "Workspace: $GITHUB_WORKSPACE"
echo "======================"
- name: Diagnostic – Check secret presence
shell: bash
run: |
declare -A secrets
secrets["CLOUDRON_FQDN"]="${{ secrets.CLOUDRON_FQDN }}"
secrets["CLOUDRON_TOKEN"]="${{ secrets.CLOUDRON_TOKEN }}"
secrets["CLOUDRON_APP_ID"]="${{ secrets.CLOUDRON_APP_ID }}"
echo "Checking secrets..."
for key in "${!secrets[@]}"; do
if [ -z "${secrets[$key]}" ]; then
echo "❌ $key is EMPTY"
else
echo "✅ $key is set"
fi
done
- name: Cloudron Push to App
uses: cloudron-io/cloudron-push-to-app@latest
with:
CLOUDRON_FQDN: "${{ secrets.CLOUDRON_FQDN }}"
CLOUDRON_TOKEN: "${{ secrets.CLOUDRON_TOKEN }}"
CLOUDRON_APP_ID: "${{ secrets.CLOUDRON_APP_ID }}"
CLOUDRON_PUSH_DESTINATION: "/app/data"
CLOUDRON_CREATE_APP_BACKUP: "false"
I have the three keys set in my environment using my main cloudron domain name, my API key, and the app id string found in the app under info
For clarification purposes, by reset, do you mean restarting the app?
I guess so, I thought I was on version 9, but under system info
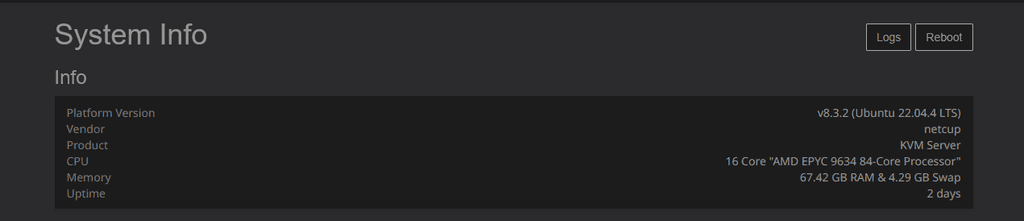
I keep getting this error message
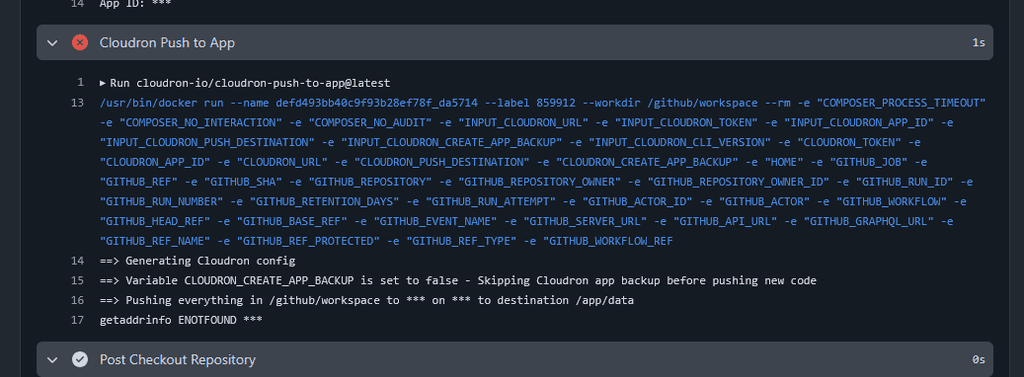
I have ensured that the URL, Token, and App ID are correct.
Here is my YAML file
on:
push:
branches:
- main
jobs:
deploy-to-cloudron-app:
runs-on: ubuntu-latest
environment: my.domain.com
steps:
- name: Checkout Repository
uses: actions/checkout@v6
- name: Setup PHP
uses: shivammathur/setup-php@v2
with:
php-version: '8.3'
extensions: pdo_mysql, pdo, json, mbstring, curl
coverage: none
- name: Verify PHP Extensions
run: |
echo "PHP Version:"
php -v
echo -e "\nInstalled Extensions:"
php -m | grep -E "(pdo_mysql|pdo|json|mbstring|curl)" || echo "Some extensions not found"
echo -e "\nAll PHP Extensions:"
php -m
- name: Install composer dependencies
run: |
composer install --no-interaction --prefer-dist --optimize-autoloader
- name: Verify Cloudron Connection
run: |
if [ -z "${{ secrets.CLOUDRON_URL }}" ]; then
echo "Error: CLOUDRON_URL secret is not set"
exit 1
fi
echo "Cloudron URL configured: ${{ secrets.CLOUDRON_URL }}"
echo "App ID: ${{ secrets.CLOUDRON_APP_ID }}"
- name: Cloudron Push to App
uses: cloudron-io/cloudron-push-to-app@latest
with:
CLOUDRON_URL: "${{ secrets.CLOUDRON_URL }}"
CLOUDRON_TOKEN: "${{ secrets.CLOUDRON_TOKEN }}"
CLOUDRON_APP_ID: "${{ secrets.CLOUDRON_APP_ID }}"
CLOUDRON_PUSH_DESTINATION: "/app/data" (I want to push to this directory, rather then to public)
CLOUDRON_CREATE_APP_BACKUP: "false"
Also, looks like in the YAML file the token and url is wapped
This is awesome! Now, how can I confirm if this worked?
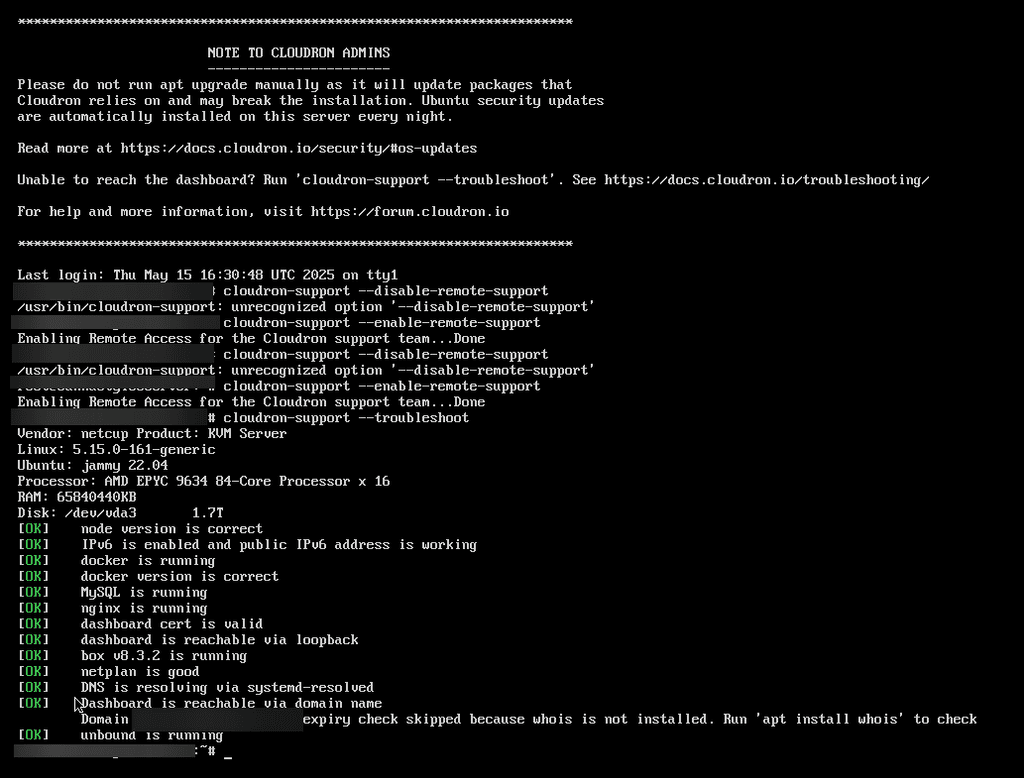
I first noticed when I log into my dashbaord, it will say cloudron unresponsive in a red banner and then it will take forever to reload.
Now its occurring everywhere. Any thing I do it is causing my server to go sluggish and be unresponsive. To manualy update a file in my lamp app it will set and load for around a minute. It used to refresh within miliseconds.
Clieck any button, visit any page, attempt to login to any app, everything is affected.
If applicable, attach relevant logs from
/home/yellowtent/platformdata/logs/box.logor the Dashboard
Nov 26 12:57:10 box:apphealthmonitor app health: 19 running / 1 stopped / 0 unresponsive
Nov 26 12:57:15 box:shell support /usr/bin/sudo -S /home/yellowtent/box/src/scripts/remotesupport.sh is-enabled /home/cloudron-support/.ssh/authorized_keys
Nov 26 12:57:15 box:shell grep: /home/cloudron-support/.ssh/authorized_keys: No such file or directory
Nov 26 12:57:15
Nov 26 12:57:15 box:shell false
Nov 26 12:57:15
Nov 26 12:57:20 box:apphealthmonitor app health: 19 running / 1 stopped / 0 unresponsive
Nov 26 12:57:29 box:shell system: swapon --noheadings --raw --bytes --show=type,size,used,name
Nov 26 12:57:30 box:apphealthmonitor app health: 19 running / 1 stopped / 0 unresponsive
Rebooted server, sebooted cloudron, different browsers, incognito window, cleared cahce
9.0.11
This information can be found here
- Cloudron 8.X my.demo.cloudron.io/#/system
- Cloudron 9.X my.demo.cloudron.io/#/metrics
- Example Shell command:
lsb_release -aExample Output:
No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 24.04.3 LTS Release: 24.04 Codename: noble
22.04.4
How do we set up GIT from github to auto pull updates from the main branch every time there is an update made or merge performed?
I may have posted in the wrong space.
But it’s an app request
Installation guide
Supported Python versions
Scrapy requires Python 3.9+, either the CPython implementation (default) or the PyPy implementation (see Alternate Implementations).
Installing Scrapy
If you’re using Anaconda or Miniconda, you can install the package from the conda-forge channel, which has up-to-date packages for Linux, Windows and macOS.
To install Scrapy using conda, run:
conda install -c conda-forge scrapy
Alternatively, if you’re already familiar with installation of Python packages, you can install Scrapy and its dependencies from PyPI with:
pip install Scrapy
We strongly recommend that you install Scrapy in a dedicated virtualenv, to avoid conflicting with your system packages.
Note that sometimes this may require solving compilation issues for some Scrapy dependencies depending on your operating system, so be sure to check the Platform specific installation notes.
For more detailed and platform-specific instructions, as well as troubleshooting information, read on.
Things that are good to know
Scrapy is written in pure Python and depends on a few key Python packages (among others):
lxml, an efficient XML and HTML parser
parsel, an HTML/XML data extraction library written on top of lxml,
w3lib, a multi-purpose helper for dealing with URLs and web page encodings
twisted, an asynchronous networking framework
cryptography and pyOpenSSL, to deal with various network-level security needs
Some of these packages themselves depend on non-Python packages that might require additional installation steps depending on your platform. Please check platform-specific guides below.
In case of any trouble related to these dependencies, please refer to their respective installation instructions:
lxml installation
cryptography installation
Using a virtual environment (recommended)
TL;DR: We recommend installing Scrapy inside a virtual environment on all platforms.
Python packages can be installed either globally (a.k.a system wide), or in user-space. We do not recommend installing Scrapy system wide.
Instead, we recommend that you install Scrapy within a so-called “virtual environment” (venv). Virtual environments allow you to not conflict with already-installed Python system packages (which could break some of your system tools and scripts), and still install packages normally with pip (without sudo and the likes).
See Virtual Environments and Packages on how to create your virtual environment.
Once you have created a virtual environment, you can install Scrapy inside it with pip, just like any other Python package. (See platform-specific guides below for non-Python dependencies that you may need to install beforehand).
Platform specific installation notes
Ubuntu 14.04 or above
Scrapy is currently tested with recent-enough versions of lxml, twisted and pyOpenSSL, and is compatible with recent Ubuntu distributions. But it should support older versions of Ubuntu too, like Ubuntu 14.04, albeit with potential issues with TLS connections.
Don’t use the python-scrapy package provided by Ubuntu, they are typically too old and slow to catch up with the latest Scrapy release.
To install Scrapy on Ubuntu (or Ubuntu-based) systems, you need to install these dependencies:
sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
python3-dev, zlib1g-dev, libxml2-dev and libxslt1-dev are required for lxml
libssl-dev and libffi-dev are required for cryptography
Inside a virtualenv, you can install Scrapy with pip after that:
pip install scrapy
Note
The same non-Python dependencies can be used to install Scrapy in Debian Jessie (8.0) and above.
https://www.scrapy.org/
Repo: https://github.com/scrapy/scrapy
Scrapy is a web scraping framework to extract structured data from websites. It is cross-platform, and requires Python 3.9+. It is maintained by Zyte (formerly Scrapinghub) and many other contributors.
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
##################
Scrapy at a glance
Scrapy (/ˈskreɪpaɪ/) is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
Even though Scrapy was originally designed for web scraping, it can also be used to extract data using APIs (such as Amazon Associates Web Services) or as a general purpose web crawler.
Walk-through of an example spider
In order to show you what Scrapy brings to the table, we’ll walk you through an example of a Scrapy Spider using the simplest way to run a spider.
Here’s the code for a spider that scrapes famous quotes from website https://quotes.toscrape.com, following the pagination:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/tag/humor/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"author": quote.xpath("span/small/text()").get(),
"text": quote.css("span.text::text").get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
Put this in a text file, name it something like quotes_spider.py and run the spider using the runspider command:
scrapy runspider quotes_spider.py -o quotes.jsonl
When this finishes you will have in the quotes.jsonl file a list of the quotes in JSON Lines format, containing the text and author, which will look like this:
{"author": "Jane Austen", "text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"}
{"author": "Steve Martin", "text": "\u201cA day without sunshine is like, you know, night.\u201d"}
{"author": "Garrison Keillor", "text": "\u201cAnyone who thinks sitting in church can make you a Christian must also think that sitting in a garage can make you a car.\u201d"}
...
What just happened?
When you ran the command scrapy runspider quotes_spider.py, Scrapy looked for a Spider definition inside it and ran it through its crawler engine.
The crawl started by making requests to the URLs defined in the start_urls attribute (in this case, only the URL for quotes in the humor category) and called the default callback method parse, passing the response object as an argument. In the parse callback, we loop through the quote elements using a CSS Selector, yield a Python dict with the extracted quote text and author, look for a link to the next page and schedule another request using the same parse method as callback.
Here you will notice one of the main advantages of Scrapy: requests are scheduled and processed asynchronously. This means that Scrapy doesn’t need to wait for a request to be finished and processed, it can send another request or do other things in the meantime. This also means that other requests can keep going even if a request fails or an error happens while handling it.
While this enables you to do very fast crawls (sending multiple concurrent requests at the same time, in a fault-tolerant way) Scrapy also gives you control over the politeness of the crawl through a few settings. You can do things like setting a download delay between each request, limiting the amount of concurrent requests per domain or per IP, and even using an auto-throttling extension that tries to figure these settings out automatically.
Note
This is using feed exports to generate the JSON file, you can easily change the export format (XML or CSV, for example) or the storage backend (FTP or Amazon S3, for example). You can also write an item pipeline to store the items in a database.
What else?
You’ve seen how to extract and store items from a website using Scrapy, but this is just the surface. Scrapy provides a lot of powerful features for making scraping easy and efficient, such as:
Built-in support for selecting and extracting data from HTML/XML sources using extended CSS selectors and XPath expressions, with helper methods for extraction using regular expressions.
An interactive shell console (IPython aware) for trying out the CSS and XPath expressions to scrape data, which is very useful when writing or debugging your spiders.
Built-in support for generating feed exports in multiple formats (JSON, CSV, XML) and storing them in multiple backends (FTP, S3, local filesystem)
Robust encoding support and auto-detection, for dealing with foreign, non-standard and broken encoding declarations.
Strong extensibility support, allowing you to plug in your own functionality using signals and a well-defined API (middlewares, extensions, and pipelines).
A wide range of built-in extensions and middlewares for handling:
cookies and session handling
HTTP features like compression, authentication, caching
user-agent spoofing
robots.txt
crawl depth restriction
and more
A Telnet console for hooking into a Python console running inside your Scrapy process, to introspect and debug your crawler
Plus other goodies like reusable spiders to crawl sites from Sitemaps and XML/CSV feeds, a media pipeline for automatically downloading images (or any other media) associated with the scraped items, a caching DNS resolver, and much more!
@jdaviescoates I use netcup.
But if another vps is better I’d happily switch.
Who can I pay to solve this for me?
My IPV6 in the dashboard is reporting working just fine.
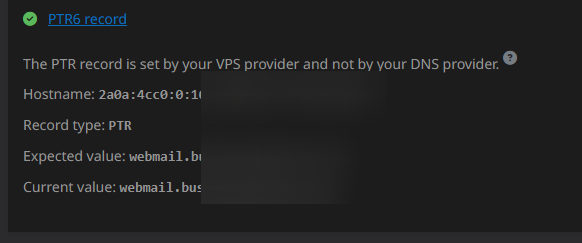
Emails are not sending to gmail emails and I need this resolved.