Couldn't find the stop button. Just wanted to say putting it under "Uninstall" seems like an odd UX decision.
M
mazarian
@mazarian
Posts
-
how do I stop a app -
Vaultwarden fails to start after update – DB migration error (SSO)Thank you! This saved me a lot of time and fixed the issue. I followed your steps and appreciated the ChatGPT workaround.
")
-
8.3.1 upgradeDid you update your system to 8.3.1? This issue has already been addressed. If I were a mod I'd find your abrupt tone pretty off-putting. With your level of expectation and use case, you should be paying for support contracts on enterprise plans. Your uptime/support expectations don't match up with Cloudron.
-
Auto-update to 8.3 - various apps down - database issue@girish thank you guys for everything you do and have done to have a stable platform! It's nice to see that even if issues come up, you guys are there for support - moreso than some of the large companies I buy tons of equipment from! You guys are awesome!
-
Auto-update to 8.3 - various apps down - database issue@joseph thank you for your reply! This is the error:
An error occurred during the restore operation: Addons Error: Unexpected response code or HTTP error when piping /home/yellowtent/appsdata/fa89594f-7176-4a81-9c25-1686af1e50da/postgresqldump to http://172.18.30.2:3000/databases/dbfa89594f71764a819c251686af1e50da/restore?access_token=XXXX&username=userXXXX: status 500 complete false -
Auto-update to 8.3 - various apps down - database issueAdd me to the list of people experiencing the same issue. Hoping for a solution soon! While some apps were able to be restored from backup, I have multiple Chatwoot instances that will not restore.
-
Chatwoot 1.36.1 Upgrade IssueJust wanted to add - it seems like I am having to restore from backup for many of my apps. All of the restores are working except for Chatwoot. It seems like something went wrong after the upgrade to Cloudron 8.3.
-
Chatwoot 1.36.1 Upgrade IssueIt's also odd- when I try switching between recovery mode off and on, Redis throws errors and I have to restart the service. But doing so doesn't allow me to start the application outside of recovery mode and still in the error logs, I see the same PG errors.
-
Chatwoot 1.36.1 Upgrade Issue@andreasdueren and @nebulon thank you both for your replies!
I just looked at my services, and things looked ok. Graphite was at 84% and I doubled the memory. I also doubled my Postgres memory and Redis memory (for the affected Chatwoot app) but none of those things seemed to help.
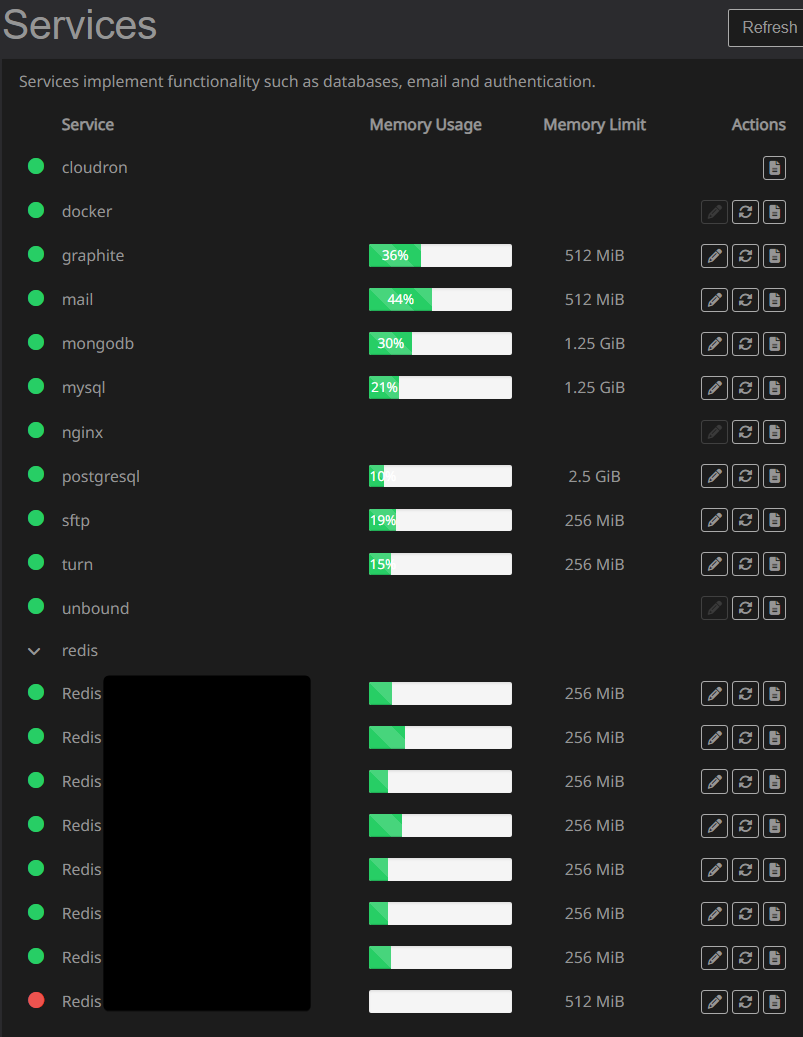
-
Chatwoot 1.36.1 Upgrade IssueI'm not quite sure how to check - I am only able to get into recovery mode and when going into the terminal and pressing the Postgres button, I see this:
root@fa89594f-7176-4a81-9c25-1686af1e50da:/app/code# PGPASSWORD=${CLOUDRON_POSTGRESQL_PASSWORD} psql -h ${CLOUDRON_POSTGRESQL_HOST} -p ${CLOUDRON_POSTGRESQL_PORT} -U ${CLOUDRON_POSTGRESQL_USERNAME} -d ${CLOUDRON_POSTGRESQL_DATABASE} psql (14.9 (Ubuntu 14.9-0ubuntu0.22.04.1), server 16.6 (Ubuntu 16.6-0ubuntu0.24.04.1)) WARNING: psql major version 14, server major version 16. Some psql features might not work. Type "help" for help. dbfa89594f71764a819c251686af1e50da=> -
Chatwoot 1.36.1 Upgrade IssueI am having a similar error in my logs, but it's happening well after the upgrade.
Mar 18 10:06:07 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:06:17 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:06:23 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:06:33 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:06:43 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:06:53 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:06:54 => Sourcing /app/data/env.sh Mar 18 10:06:54 => Starting chatwoot Mar 18 10:06:54 => Upgrading existing db Mar 18 10:06:56 I, [2025-03-18T17:06:56.956461 #10] INFO -- : [rake ip_lookup:setup] IP_LOOKUP_API_KEY empty. Skipping geoip database setup Mar 18 10:06:57 2025-03-18T17:06:57Z Mar 18 10:06:57 (See full trace by running task with --trace) Mar 18 10:06:57 /app/code/db/schema.rb:134:in `block in <main>' Mar 18 10:06:57 /app/code/db/schema.rb:134:in `block in <main>' Mar 18 10:06:57 /app/code/db/schema.rb:13:in `<main>' Mar 18 10:06:57 /app/code/db/schema.rb:13:in `<main>' Mar 18 10:06:57 /app/code/lib/tasks/db_enhancements.rake:18:in `block (2 levels) in <main>' Mar 18 10:06:57 /app/code/lib/tasks/db_enhancements.rake:18:in `block (2 levels) in <main>' Mar 18 10:06:57 /app/code/lib/tasks/db_enhancements.rake:18:in `each' Mar 18 10:06:57 /app/code/lib/tasks/db_enhancements.rake:18:in `each' Mar 18 10:06:57 /app/code/lib/tasks/db_enhancements.rake:22:in `block (3 levels) in <main>' Mar 18 10:06:57 /app/code/lib/tasks/db_enhancements.rake:22:in `block (3 levels) in <main>' Mar 18 10:06:57 ActiveRecord::StatementInvalid: PG::ConnectionBad: PQconsumeInput() server closed the connection unexpectedly (ActiveRecord::StatementInvalid) Mar 18 10:06:57 Caused by: Mar 18 10:06:57 PG::ConnectionBad: PQconsumeInput() server closed the connection unexpectedly (PG::ConnectionBad) Mar 18 10:06:57 Tasks: TOP => db:chatwoot_prepare Mar 18 10:06:57 This probably means the server terminated abnormally Mar 18 10:06:57 This probably means the server terminated abnormally Mar 18 10:06:57 before or while processing the request. Mar 18 10:06:57 before or while processing the request. Mar 18 10:06:57 rails aborted! Mar 18 10:07:07 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:07:17 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:07:26 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:07:33 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:07:43 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:07:43 BoxError: Unknown install command in apptask:error Mar 18 10:07:43 BoxError: Unknown install command in apptask:error Mar 18 10:07:53 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:07:57 => Starting chatwoot Mar 18 10:07:57 => Sourcing /app/data/env.sh Mar 18 10:07:57 => Upgrading existing db Mar 18 10:08:00 => Healtheck error: Error: connect ECONNREFUSED 172.18.19.185:3000 Mar 18 10:08:00 I, [2025-03-18T17:08:00.416259 #10] INFO -- : [rake ip_lookup:setup] IP_LOOKUP_API_KEY empty. Skipping geoip database setup Mar 18 10:08:00 rails aborted! Mar 18 10:08:00 ActiveRecord::StatementInvalid: PG::ConnectionBad: PQconsumeInput() server closed the connection unexpectedly (ActiveRecord::StatementInvalid) Mar 18 10:08:00 This probably means the server terminated abnormally Mar 18 10:08:00 before or while processing the request. Mar 18 10:08:00 /app/code/db/schema.rb:134:in `block in <main>' Mar 18 10:08:00 /app/code/db/schema.rb:13:in `<main>' Mar 18 10:08:00 /app/code/lib/tasks/db_enhancements.rake:22:in `block (3 levels) in <main>' Mar 18 10:08:00 /app/code/lib/tasks/db_enhancements.rake:18:in `each' Mar 18 10:08:00 /app/code/lib/tasks/db_enhancements.rake:18:in `block (2 levels) in <main>' Mar 18 10:08:00 2025-03-18T17:08:00Z Mar 18 10:08:00 Caused by: Mar 18 10:08:00 PG::ConnectionBad: PQconsumeInput() server closed the connection unexpectedly (PG::ConnectionBad) Mar 18 10:08:00 This probably means the server terminated abnormally Mar 18 10:08:00 before or while processing the request. Mar 18 10:08:00 /app/code/db/schema.rb:134:in `block in <main>' Mar 18 10:08:00 /app/code/db/schema.rb:13:in `<main>' Mar 18 10:08:00 /app/code/lib/tasks/db_enhancements.rake:22:in `block (3 levels) in <main>' Mar 18 10:08:00 /app/code/lib/tasks/db_enhancements.rake:18:in `each' Mar 18 10:08:00 /app/code/lib/tasks/db_enhancements.rake:18:in `block (2 levels) in <main>' Mar 18 10:08:00 Tasks: TOP => db:chatwoot_prepare Mar 18 10:08:00 (See full trace by running task with --trace) Mar 18 10:08:17 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:08:27 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:08:33 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:08:43 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:08:53 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:09:01 => Starting chatwoot Mar 18 10:09:01 => Sourcing /app/data/env.sh Mar 18 10:09:01 => Upgrading existing db Mar 18 10:09:03 => Healtheck error: Error: connect ECONNREFUSED 172.18.19.185:3000 Mar 18 10:09:03 I, [2025-03-18T17:09:03.629615 #10] INFO -- : [rake ip_lookup:setup] IP_LOOKUP_API_KEY empty. Skipping geoip database setup Mar 18 10:09:04 rails aborted! Mar 18 10:09:04 ActiveRecord::StatementInvalid: PG::ConnectionBad: PQconsumeInput() server closed the connection unexpectedly (ActiveRecord::StatementInvalid) Mar 18 10:09:04 This probably means the server terminated abnormally Mar 18 10:09:04 before or while processing the request. Mar 18 10:09:04 /app/code/db/schema.rb:134:in `block in <main>' Mar 18 10:09:04 /app/code/db/schema.rb:13:in `<main>' Mar 18 10:09:04 /app/code/lib/tasks/db_enhancements.rake:22:in `block (3 levels) in <main>' Mar 18 10:09:04 /app/code/lib/tasks/db_enhancements.rake:18:in `each' Mar 18 10:09:04 /app/code/lib/tasks/db_enhancements.rake:18:in `block (2 levels) in <main>' Mar 18 10:09:04 2025-03-18T17:09:04Z Mar 18 10:09:04 Caused by: Mar 18 10:09:04 PG::ConnectionBad: PQconsumeInput() server closed the connection unexpectedly (PG::ConnectionBad) Mar 18 10:09:04 This probably means the server terminated abnormally Mar 18 10:09:04 before or while processing the request. Mar 18 10:09:04 /app/code/db/schema.rb:134:in `block in <main>' Mar 18 10:09:04 /app/code/db/schema.rb:13:in `<main>' Mar 18 10:09:04 /app/code/lib/tasks/db_enhancements.rake:22:in `block (3 levels) in <main>' Mar 18 10:09:04 /app/code/lib/tasks/db_enhancements.rake:18:in `each' Mar 18 10:09:04 /app/code/lib/tasks/db_enhancements.rake:18:in `block (2 levels) in <main>' Mar 18 10:09:04 Tasks: TOP => db:chatwoot_prepare Mar 18 10:09:04 (See full trace by running task with --trace) Mar 18 10:09:17 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:09:27 => Healtheck error: Error: Timeout of 7000ms exceeded Mar 18 10:09:33 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:09:43 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:09:53 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000 Mar 18 10:10:03 => Healtheck error: Error: connect EHOSTUNREACH 172.18.19.185:3000I tried recovering from backup and cloning and am getting the following error:
An error occurred during the clone operation: Addons Error: Unexpected response code or HTTP error when piping /home/yellowtent/appsdata/e2f314e0-389e-4c1b-8e80-9852e13db8e3/postgresqldump to http://172.18.30.2:3000/databases/dbe2f314e0389e4c1b8e809852e13db8e3/restore?access_token=b637659aed0a708f188d2902fc267163718b8c6777cd722433926b0654ff03c7c2fc782f7c39a559f0d1954f031c7215eb96ebf6bc759500e2419d84607396d249c157dc7a7db537926351f20ae6a23261db0a55c93e07a278161db6c2e7f4fdd04756ff7cc1cd30bd67096101d9b83b643ebf91abf5f2e3a2026dbd93d1ae6b&username=usere2f314e0389e4c1b8e809852e13db8e3: status 500 complete falseAny help would greatly be appreciated!
-
Regular short getaddrinfo EAI_AGAIN outagesThat's a fantastic idea! I will add it. I ended up migrating it off Cloudron for the time being because I have come to depend on UK for work and all the notifications were bogging me down.
I will restart the old instance to test and will report back what I find out.
-
Regular short getaddrinfo EAI_AGAIN outagesHey thanks for getting back! My TLD is .LA.
-
Regular short getaddrinfo EAI_AGAIN outagesI know this is an old thread, but I'm also having this issue and curious if anyone has found a solution other than upping retries. Or perhaps there's another service similar to Uptime Kuma that doesn't have these issues?
-
Migrating to new server - Restore backup failingI wish it was, but the DNS was already set to my new IP address for all of the instances on my Cloudron. I tried doing the restore multiple times, choosing enabling and disabling the dry run option as I tried to figure things out.
-
Migrating to new server - Restore backup failingSo- after a bit of fighting with it, I was able to get all of the containers online. Many failed, but eventually the interface became responsive and I was able to restore each individually.
I think one of the things that's happening is they'are all trying to restore simultaneously. Perhaps if it restored in a linear way, there would be a bit more stability.
-
Migrating to new server - Restore backup failingHi all,
I'm having a tough time migrating my server hosted on DigitalOcean over to my own Proxmox. I created an Ubuntu 22.04 VM with 12GB memory and 320GB storage. There are 12 containers (all pretty small) on my Cloudron instance that need to be restored. I have been backing up to filesystem (following the backup/restore guide in docs) and copying the files over to the new box (I made sure permissions in entire directory are owned by yellowtent:yellowtent). When I go through the restore process, the new instance becomes very unresponsive. When I access the web interface, I can see that it is trying to restore the containers, but many of them error out. If I try to click on one of the containers to see what is happening, it gives me an error saying the app isn't responding.
Not sure how to troubleshoot but happy to provide any logs.
Thanks!
-
SSHFS Mount Backup maybe BUG@rmdes I ended up setting up a local backup for Cloudron and use RClone to handle the backup. I've used RClone for years with no issue, and since going this route, no issues with my Cloudron backup.
-
Import Archive Emails@girish Thank you for the pointer! I've spent a bit of time trying to convert my MBOX files using mb2md and it seems like there's some sort of bug that isn't working with my files.
I am getting the following error thousands of times:
Use of uninitialized value $t in utime at /usr/bin/mb2md line 1043, <MBOX> line 36621221I will report back when I have a solution!
-
Import Archive EmailsHi all,
Please excuse me if this has been covered before (if so, would love a pointer!). I have a customer with lots of archived email boxes (originally PST & converted to MBOX format) and I was wondering if anyone has any tips on importing them into Cloudron email.
My goal is to have a web-based, easily searchable mailbox for each archived mail account. If it's possible to convert the MBOX files into something that works with Cloudron, my idea is to setup a subdomain dedicated to archived accounts, and create logins for each inbox (archiveduser1@archive.example.com).
Any help in achieving this is greatly appreciated!
Thanks!