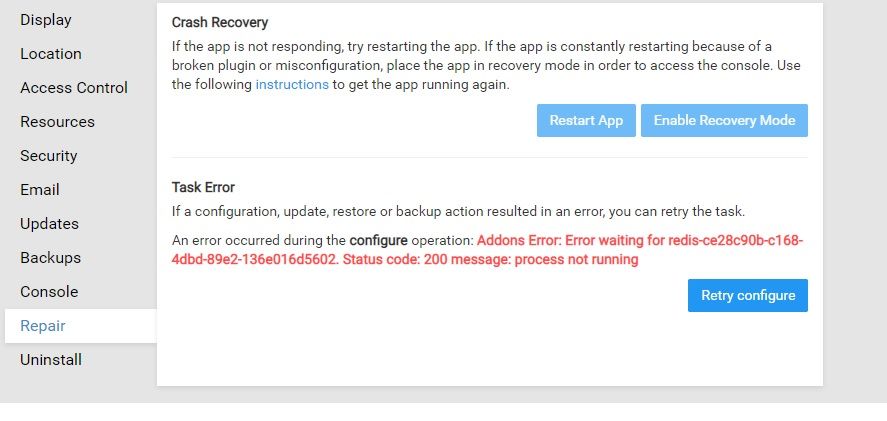
Follow up from the customer: "The issue here turned out to be that in Wordpress, WP Rocket caching plugin was used. This plugin automatically starts to preload the cache of each page once something in the site has been updated. The preload itself causes some stress on the CPU and maybe some other processes. Turning off the plugin, the products were sent for less than 2 mins."
They are working with the WP Rocket team to find a workaround.