@andreasdueren thanks, I finally got it to work with private messages, channels seems to be more difficult. However, I also opted for the telegram option, less hassle 
Posts
-
Hermes Agent -
Hermes AgentNot sure where we should post about community packages, so I'm hijacking this topic
")
First of all, thanks for the package @andreasdueren!
Quick question: did you try/manage to connect to an encrypted Matrix channel? Is it possible that we're missing the mautrix[encryption] package?
-
redis errors after updating Open WebUI from 0.9.6 to 0.10.1Yep, redis is up and running (also says so in the services tab):
Jul 02 12:56:10 13:C 02 Jul 2026 10:56:10.580 * Configuration loaded Jul 02 12:56:10 13:C 02 Jul 2026 10:56:10.580 * Redis version=8.4.0, bits=64, commit=00000000, modified=1, pid=13, just started Jul 02 12:56:10 13:C 02 Jul 2026 10:56:10.580 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.580 * Increased maximum number of open files to 10032 (it was originally set to 1024). Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.580 * monotonic clock: POSIX clock_gettime Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.581 # Failed to write PID file: Permission denied Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.581 * Loading RDB produced by version 8.4.0 Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.581 * RDB age 5188 seconds Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.581 * RDB memory usage when created 1.08 Mb Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.581 * Running mode=standalone, port=6379. Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.581 * Server initialized Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.582 * DB loaded from disk: 0.001 seconds Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.582 * Done loading RDB, keys loaded: 3, keys expired: 1. Jul 02 12:56:10 13:M 02 Jul 2026 10:56:10.582 * Ready to accept connections tcp Jul 02 12:56:10 2026-07-02 10:56:10,573 INFO spawned: 'redis' with pid 13 Jul 02 12:56:10 2026-07-02 10:56:10,574 INFO spawned: 'redis-service' with pid 14 Jul 02 12:56:10 Redis service endpoint listening on http://:::3000 Jul 02 12:56:11 2026-07-02 10:56:11,645 INFO success: redis entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) Jul 02 12:56:11 2026-07-02 10:56:11,645 INFO success: redis-service entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)The errors only start to show up, when you access the site.
-
redis errors after updating Open WebUI from 0.9.6 to 0.10.1I've just updated my Open WebUI to 0.10.1 and the log is being spammed with this:
Jul 02 11:07:06 Cannot receive from redis... retrying in 1 secs Jul 02 11:07:06 2026-07-02 09:07:06.757 | ERROR | socketio.async_redis_manager:_redis_listen_with_retries:159 - Cannot receive from redis... retrying in 1 secs Jul 02 11:07:12 Cannot receive from redis... retrying in 1 secs Jul 02 11:07:12 2026-07-02 09:07:12.770 | ERROR | socketio.async_redis_manager:_redis_listen_with_retries:159 - Cannot receive from redis... retrying in 1 secs Jul 02 11:07:18 Cannot receive from redis... retrying in 1 secsNot sure what changed, since the redis config wasn't touched or if this has a negative impact, just wanted to let you know.
-
Backup Integrity check runs into oom-
That I know, but how would I get the second backup site to include those? Eventually I'll switch to the second backup as primary and lose the secondary one when they're in sync.
-
Right, but why does it work with the Storagebox and not MinIO, does that require more resources?
-
-
Backup Integrity check runs into oomTwo things:
I have a Cloudron (9.1.7) with two backup destinations, one MinIO and a Hetzner Storagebox. Both are set up to backup the same things every day, 2 hours apart.
- For whatever reason the MinIO backup (which was the default and only backup for years) lists also stopped apps even though they're not included in the backup, both in size and # of apps.
Screenshot:
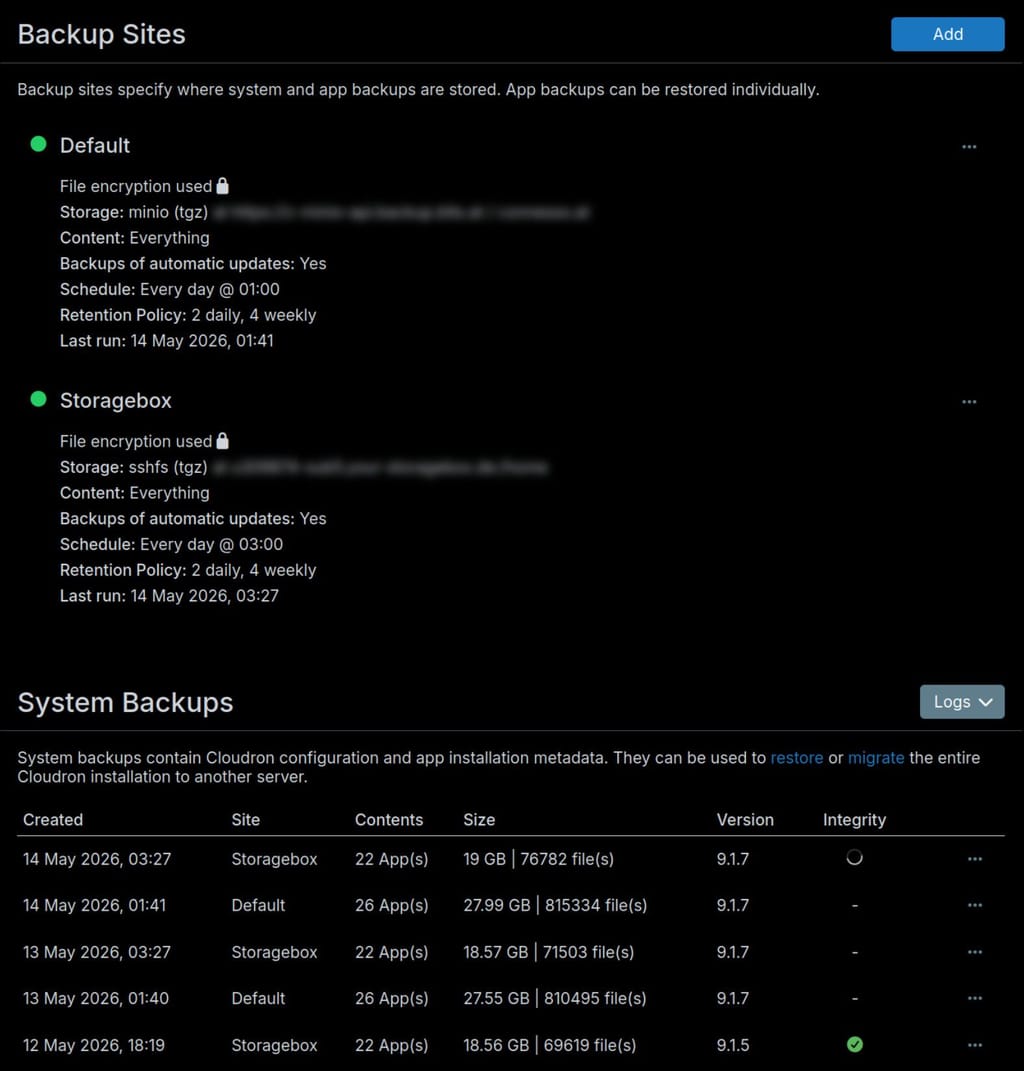
- When trying to do an integrity check on the MinIO backup, it says it crashed due to oom (ran out of memory or terminated). The server has plenty of RAM and the Storagebox integrity check works without problems.
May 14 12:32:47 tasks: startTask - starting task 12627 with options {}. logs at /home/yellowtent/platformdata/logs/tasks/12627.log May 14 12:32:47 tasks: updating task 12627 with: {"pending":false} May 14 12:32:47 shell: tasks: /usr/bin/sudo --non-interactive -E /home/yellowtent/box/src/scripts/starttask.sh 12627 /home/yellowtent/platformdata/logs/tasks/12627.log 0 400 0 May 14 12:32:50 apphealthmonitor: app health: 25 running / 5 stopped / 0 unresponsive May 14 12:32:52 shell: tasks: /usr/bin/sudo --non-interactive -E /home/yellowtent/box/src/scripts/starttask.sh 12627 /home/yellowtent/platformdata/logs/tasks/12627.log 0 400 0 errored with code 9 and signal null timeout false terminated false - stdout: "Service box-task-12627 failed to run Service box-task-12627 finished with exit code 2 and status 9 " - stderr: "Running as unit: box-task-12627.service; invocation ID: 7db618c2df95465c8db4534413f4f106 Finished with result: oom-kill Main processes terminated with: code=killed/status=KILL Service runtime: 4.670s CPU time consumed: 3.777s Memory peak: 400.0M Memory swap peak: 55.7M " May 14 12:32:52 tasks: startTask: 12627 done. error: { message: 'Task 12627 ran out of memory or terminated', code: 'crashed' } May 14 12:32:52 tasks: setCompleted - 12627: {"error":{"message":"Task 12627 ran out of memory or terminated","code":"crashed"}} May 14 12:32:52 tasks: updating task 12627 with: {"completed":true,"error":{"message":"Task 12627 ran out of memory or terminated","code":"crashed"}} May 14 12:32:52 backups: startIntegrityCheck: task error. Task 12627 ran out of memory or terminatedCould be that those 2 issues are related.
-
Latest cloudron cli doesn't accept --server and --token anymoreah thanks @joseph, haven't tried that! https://docs.cloudron.io/packaging/cli/#cicd needs an update then
-
Latest cloudron cli doesn't accept --server and --token anymoreMy build pipeline crashed because
cloudron execwouldn't accept--serverand--tokenanymore on the latest CLI version. Is that by design or a regression?cloudron exec --app example.com --server my.example.com --token $CLOUDRON_TOKEN -- rm -rf /app/data/trash/*comes back witherror: unknown option '--server'. I downgraded from v8.2.3 to v8.0.0 and it's working again. If something changed, what would be the right way to make this work again? -
Help & Feedback wanted: broken link checker needs (stress-)testing@luckow Thanks for testing, that one was actually by design
 I just added an override for max scanned pages (15k should do it), please rescan. Also, don't forget to set a higher crawl rate on larger pages (if there's no throttle), that will improve the speed significantly
I just added an override for max scanned pages (15k should do it), please rescan. Also, don't forget to set a higher crawl rate on larger pages (if there's no throttle), that will improve the speed significantly ")
-
Help & Feedback wanted: broken link checker needs (stress-)testing@james awesome, if you run out of pages and need a bump, let me know
I thought about open-sourcing the thing from the start, but after a bit of testing I realized how many websites are tunneling through services like Cloudflare - which would instantly block traffic from bots like this one.
It was quite an ordeal to get a "signed agent" approved by CF, but I managed to get that done eventually (wrong category, but hey, it's in there
 ). This means every request is signed with a special signature deriving from a host key in
). This means every request is signed with a special signature deriving from a host key in /.well-known/...So you would either have a lot of self-hosted bots that can't do a lot or you would swamp Cloudflares bot directory - both not ideal, that's why I opted to keep it closed and offered a generous free tier instead. Revenue is not the priority, I wanted to get it out so people can have fun with it.
The runners idea is interesting though, currently they all share the same internal API key for auth between each other, that would probably require some fiddling around. Lets iron out all the kinks first and see where we go from there
-
Help & Feedback wanted: broken link checker needs (stress-)testing@luckow thanks for that, I never checked light mode on the keycloak template
Should be fixed! -
Help & Feedback wanted: broken link checker needs (stress-)testingHello Cloudronauts!
I’ve been building a frontend for my broken link checker over the past months as a side project and I’m getting close to releasing it to the public. The main goal was to keep it easy, fast and straightforward, while still covering the things that tend to matter in practice (broken links, redirects, some server info and basic SEO checks).
Before actually publishing it somewhere, I thought I'd ask the Cloudron community for a little help, run it against real-world setups and see where it breaks or gives misleading results (also, I ran out of ideas which sites to check). If anyone here is interested in trying it on their own sites and sharing feedback with me (either publicly or dm), that would be much appreciated.
I’m especially interested in:
- edge cases (odd redirects, timeouts, unusual setups)
- anything confusing or missing in the reports
- cases where results don’t look correct
- general feedback/bug-reports or inconsistencies
- last minute feature requests
I’ve set up a 60-day coupon (code:
WE-LOVE-CLOUDRON, redeemable until the end of April) "starter plan" for this, so you can use it without any barriers (other than your email-address), after the 60 days it will fall back to a free account. If something looks off, you can send me a share link or just describe what you’re seeing.Here's the URL: https://www.4f.at/
This is not meant as a promotion, just trying to make the tool more solid before launch. Also posting it here especially since this is a 100% Cloudron powered affair (except the runners for the build pipeline):
- custom Next.js app with PostgreSQL and Redis (sessions, rate-limiter, caching)
- Keycloak for OIDC authentication (sends out magic links for login)
- crawlers are custom Go-apps that can be easily deployed on multiple servers to scale horizontally
- source-code resides in a private Gitea instance, the build pipeline includes the docker registry app, Cloudron build service and a custom Drone-app & runners
- Umami for statistics
Thanks for the attention!
-
Unusable applicationYou got a typo in there maybe, or a firewall?
-
Unusable application@klawitterb try without
https:// -
Notifications view doesn't have a vertical scrollbarThere is no scrollbar even though there are more elements than there is space, while checking notifications on
/#/notificationson 9.1.5: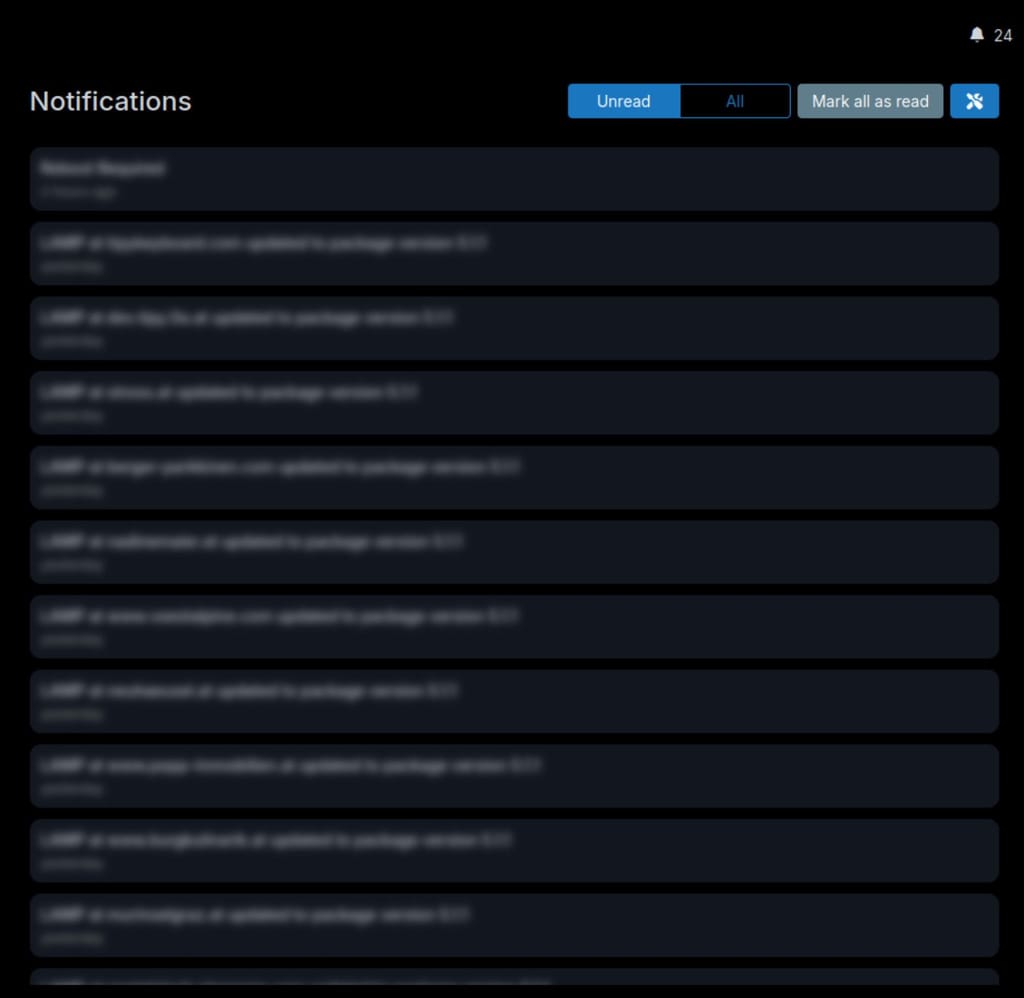
This would fix it (adjust accordingly do that specific container):
.section-body { overflow-y: scroll; } -
Web terminal font changed after update to 9.1.3If you want strange, I can throw this in the mix
: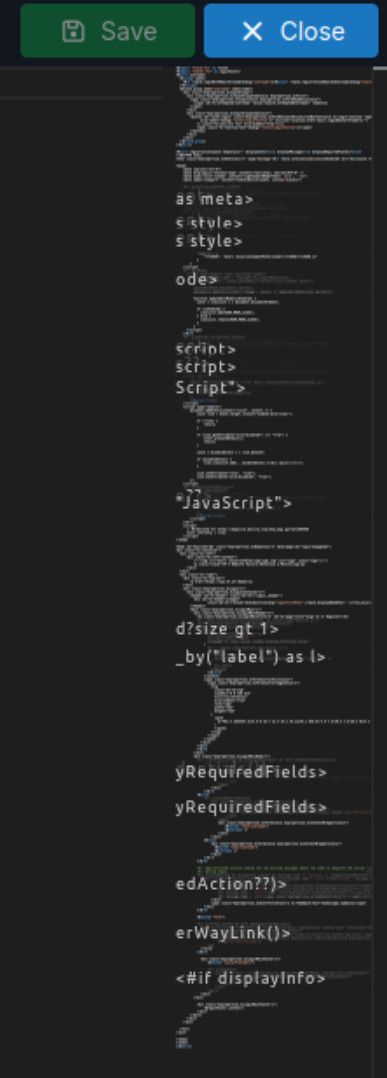
Firefox on Ubuntu, but it also happens on Brave. Might be due to the format (.ftl file)
-
What's coming in 9.1@timconsidine exactly
-
What's coming in 9.1@girish well...


-
What's coming in 9.1@girish is 9.1 stable already? Had another Cloudron that just updated by itself via cron
-
How to Package and Deploy Strapi v5 as a Custom App on CloudronWould have probably been easier to update the old attempt
https://git.cloudron.io/msbt/strapi-app