you have not set a value for medialinks ! Or one that is accessible. In CloudronManufest,json.
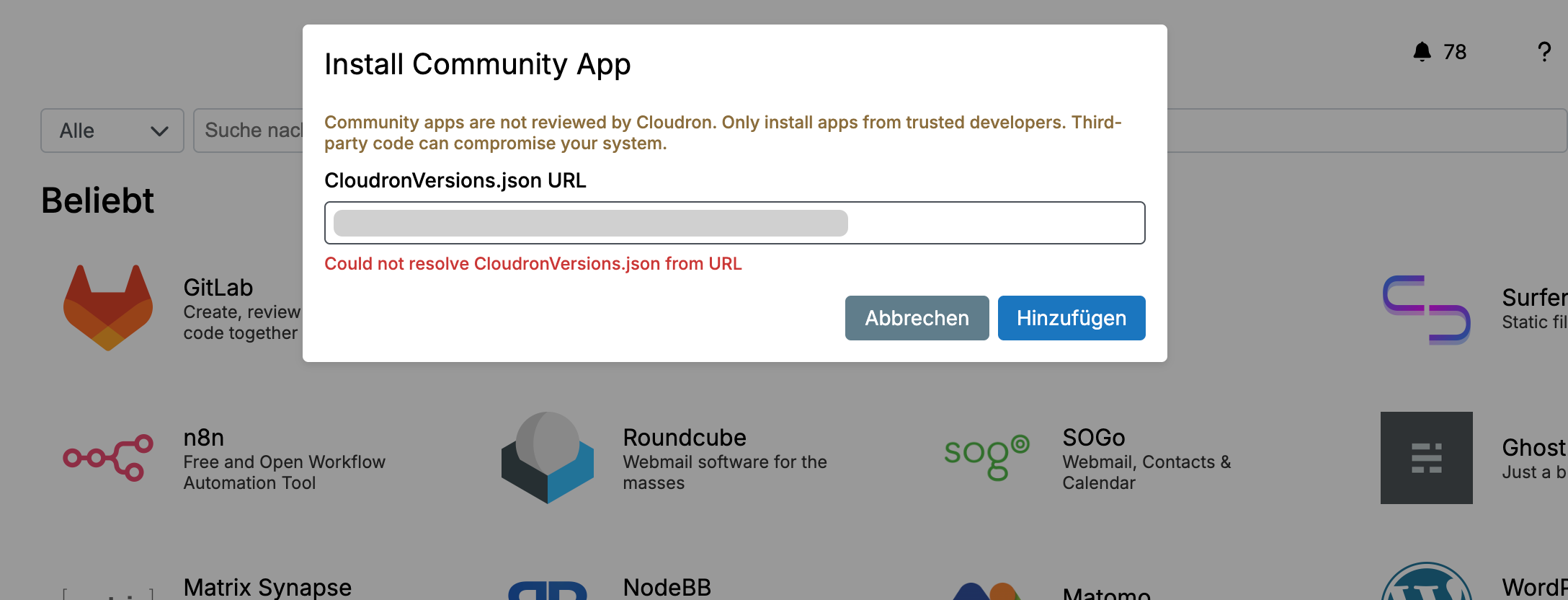
Yeah that was the second mistake. Before, I got the message "Invalid manifest: mediaLinks is empty in manifest" I had a cryptic message like: "Could not resolve CloudronVersions.json from url". In the end, my CloudronVersions was wrong, and the error message before was not helpful. However, the medialinks error message was
For this one:
CloudronVersions.json needs to be publicly accessible also the Docker image
CloudronVersions.json is public, yes
Docker image is private - but it works
I have the ghcr with credentials registered on the cloudron. So no issue anymore.
In case you are interested in an error-message-improval-bug-hunt, I can send you a version of my "broken" CloudronVersions.json via PM - if not - I am happy now